Transformeur génératif pré-entraîné
Le transformeur génératif pré-entraîné (ou GPT, de l’anglais generative pre-trained transformer) est une famille de modèles de langage généralement formée sur un grand corpus de données textuelles pour générer un texte de type humain.
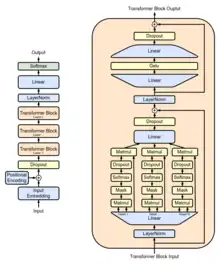
Description
Il est construit en utilisant plusieurs blocs de l'architecture du transformeur. Ils peuvent être affinés pour diverses tâches de traitement du langage naturel telles que la génération de texte, la traduction de langue et la classification de texte. Le "pré-entrainement" dans son nom fait référence au processus de formation initial sur un grand corpus de texte où le modèle apprend à prédire le mot suivant dans un passage, ce qui fournit une base solide pour que le modèle fonctionne bien sur des tâches en aval avec des quantités limitées de données spécifiques à la tâche.
Exemples d'utilisation
- ChatGPT (Chat Generative Pre-trained Transformer[1]) est un chatbot lancé par OpenAI en novembre 2022. Il utilise GPT-3.5 et est affiné (une approche de l'apprentissage par transfert[2]) avec des techniques d'apprentissage supervisé et par renforcement.
- BioGPT est un GPT qui se concentre sur la réponse aux questions biomédicales[3]. Il est développé par Microsoft[4].
- ProtGPT2 est un GPT qui se concentre sur la conception de protéines[5].
Historique
Le 11 juin 2018, OpenAI a publié un article intitulé Improving Language Understanding by Generative Pre-Training, dans lequel est présenté le Generative Pre-trained Transformer (GPT)[6]. À ce stade, les modèles de TAL neuronaux les plus performants utilisaient principalement l'apprentissage supervisé à partir de grandes quantités de données étiquetées manuellement. Cette dépendance à l'apprentissage supervisé a limité leur utilisation sur des ensembles de données qui n'étaient pas bien annotés, en plus de rendre excessivement coûteux et chronophage la formation de modèles extrêmement volumineux[6] - [7] ; de nombreuses langues (telles que le swahili ou le créole haïtien ) sont difficiles à traduire et à interpréter à l'aide de tels modèles en raison d'un manque de texte disponible pour la construction de corpus[7]. En revanche, l'approche « semi-supervisée » de GPT comportait deux étapes : une étape de « pré-entrainement » génératif non supervisée dans laquelle un objectif de modélisation du langage était utilisé pour définir les paramètres initiaux, et une étape de « réglage fin » discriminatif supervisé dans laquelle ces paramètres ont été adaptés à une tâche cible[6].
| Architecture | Nombre de paramètres | Données d'entraînement | |
|---|---|---|---|
| GPT-1 | Transformateur de type decodeur à 12 niveaux et 12 têtes (pas d'encodeur), suivi de linear-softmax. | 0,12 milliard | BookCorpus[8] : 4,5 Go de texte, à partir de 7 000 livres inédits de divers genres. |
| GPT-2 | GPT-1, mais avec une normalisation modifiée | 1,5 milliard | WebText : 40 Go de texte, 8 millions de documents, à partir de 45 millions de pages Web votées sur Reddit. |
| GPT-3 | GPT-2, mais avec des modifications pour permettre une plus grande mise à l'échelle. | 175 milliards | 570 Go de texte en clair, 0,4 billion de jetons. Principalement CommonCrawl, WebText, Wikipedia anglais et deux corpus de livres (Books1 et Books2). |
Références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Generative pre-trained transformer » (voir la liste des auteurs).
- (en-US) Kevin Roose, « The Brilliance and Weirdness of ChatGPT » [archive du ], The New York Times, (consulté le ) : « Like those tools, ChatGPT — which stands for generative pre-trained transformer — landed with a splash. »
- Joanne Quinn, Dive into deep learning: tools for engagement, Thousand Oaks, California, (ISBN 9781544361376, lire en ligne [archive du ]), p. 551
- (en) Luo R, Sun L, Xia Y, Qin T, Zhang S, Poon H, « BioGPT: generative pre-trained transformer for biomedical text generation and mining. », Brief Bioinform, vol. 23, no 6, (PMID 36156661, DOI 10.1093/bib/bbac409, lire en ligne)
- (en) Matthias Bastian, « BioGPT is a Microsoft language model trained for biomedical tasks », The Decoder,
- (en) Ferruz, N., Schmidt, S. & Höcker, B., « ProtGPT2 is a deep unsupervised language model for protein design. », Nature Communications volume, vol. 13, (DOI 10.1038/s41467-022-32007-7, lire en ligne)
- (en) Alec Radford, Karthik Narasimhan, Tim Salimans et Ilya Sutskever, « Improving Language Understanding by Generative Pre-Training » [archive du ], OpenAI, (consulté le ), p. 12
- (en) Yulia Tsvetkov, « Opportunities and Challenges in Working with Low-Resource Languages » [archive du ], Carnegie Mellon University, (consulté le )
- (en) Yukun Zhu, Ryan Kiros, Rich Zemel et Ruslan Salakhutdinov, « Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books », IEEE International Conference on Computer Vision, , p. 19–27 (lire en ligne)