Génération automatique de textes
La génération automatique de texte (GAT)[1] est une sous discipline de la linguistique computationnelle qui vise à exprimer sous une forme textuelle, syntaxiquement et sémantiquement correcte[2], une représentation formelle d'un contenu.
Outre ses nombreuses applications existantes ou potentielles - par exemple pour produire automatiquement des bulletins météorologiques, ou des rapports automatisés - elle offre par ailleurs un cadre d'investigation des théories linguistiques, et particulièrement de ses mécanismes de production.
Historique
Travaux de Shannon et Turing
Historiquement, les deux premiers chercheurs à s'être penchés sur la question de la production de texte par des systèmes d'information sont Claude Shannon, suivi de Alan Turing.
Alan Turing réfléchit de manière générale à cette possibilité dans le cadre de sa proposition du test d’IA intitulé Le jeu de l’imitation. Ce test, que Turing décrit en 1950 dans son article prospectif sur le rapport existant entre intelligence et mécanique informatique[3], consiste à faire dialoguer un humain avec un ordinateur et ce même humain avec un autre humain. Selon Turing, si l’homme qui engage les deux conversations n’est pas capable de différencier un locuteur humain d’un ordinateur, il est permis de considérer que le logiciel a passé avec succès le test. Ce test, comme on le voit aujourd'hui à l'occasion du Prix Loebner, consiste en grande partie à générer des phrases syntaxiquement et sémantiquement correctes.
Claude Shannon, dans son article sur la « Théorie mathématique de la communication », fondement de la Théorie de l'information, dès 1948[4], imagine la possibilité de générer automatiquement du texte en utilisant des probabilités markoviennes de transition d'un mot à un autre. Il construit le premier modèle théorique de générateur de texte. Aidé d'une table de transition calculée à la main, il élabore diverses phrases qui ressemblent à l'anglais. L'un des exemples donné par Shannon, d'ordre deux, c'est-à-dire reposant sur la probabilité de transition pour deux mots consécutifs, est le suivant :
« THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED ».
Shannon ne poursuivra pas ses recherches en matière de génération, son objectif principal est de formaliser mathématiquement la transmission d'information, mais la méthode qu'il décrit est aujourd'hui au cœur de nombreuses méthodes appliquées au traitement automatique du langage, par exemple dans les (en)modèles de langage probabilistes. Les modèles de langage sont également impliqués dans certaines architectures de générateurs de texte dits statistiques.
Mais les premiers systèmes appliqués de GAT datent des années 1960. Ils ont été mis au point pour expérimenter dans un cadre théorique la théorie présentée par Chomsky dans Structures Syntaxiques.
Les systèmes inspirés de la linguistique Chomskyenne
Victor Yngve (en) en 1961[5], très peu de temps après la parution de Structures Syntaxiques cherche avec les systèmes rudimentaires de l'époque à expérimenter la production de phrases d'après les propositions de Chomsky. Il décrit l'algorithme de son système, presque entièrement basé sur des grammaires génératives, dans son article intitulé Random Generation of English Sentences. Yngve se heurte aux phénomènes de complexité linguistique qui perturbent la recherche sur la mécanisation du langage depuis la fin des années 1940. Il indique d'ailleurs dans son article « que les grammaires transformationnelles originelles ont été abandonnées car elles ne peuvent pas être mécanisées avec un appareil fini, en raison de la difficulté d’associer une structure de phrase au résultat d’une transformation ».
D'autres travaux tels ceux de Matthews[6] en 1962 ou de Friedman[7] en 1969 sont similaires à ceux de Yngve. Très marqué par les besoins de l'époque et les orientations des financements universitaires en Amérique du Nord, ils s’inscrivent dans la perspective d’insérer le générateur de texte en tant qu'élément d'un système de traduction automatique. Souvent, ces travaux ne cherchent pas réellement à produire un texte sémantiquement correct mais se focalisent plus sur la capacité des systèmes à produire des phrases syntaxiquement correctes. Comme le système de Friedman, écrit en Fortran et fonctionnant sur IBM 360/67, qui génère des structures syntaxiques de manière aléatoire.
Cadre théorique
Approche symbolique
Les formalismes théoriques dérivant des méthodes symboliques sont principalement les suivants[2] - [8] :
- SFG (en) (systemic-functional grammars), grammaires systémiques-fonctionnelles. Utilisées pour l'accent qu'elles mettent sur l'aspect « fonctionnel », notamment via l'utilisation de « traits fonctionnels ». Exemples de systèmes :
FUF[9] qui utilise le principe d’« unification » des traits ;KPML[10], système multilingue héritier dePENMAN. - TAG (tree-adjoining grammars), grammaires d'arbres adjoints. Utilisées pour effectuer de la génération incrémentale.
- MTM (meaning-text model), modèle sens-texte d'Igor Mel'čuk.
Architecture
La GAT s'oppose à la compréhension du langage naturel puisque cette dernière part du texte pour en saisir le sens alors que le but de la GAT est de transformer du sens en texte. Ceci se traduit par une plus grande variété d’inputs différents, en fonction du domaine d'application (alors que du texte restera toujours du texte). De plus, contrairement à la compréhension, la génération n'a pas à se soucier (ou dans une moindre mesure) de l'ambiguïté, de la sous-spécification ou d'un input mal formé, qui sont les principales préoccupations en compréhension[11].
Le problème majeur de la GAT est le choix. Cet embarras du choix se pose à plusieurs niveaux[12] :
- contenu : quoi dire ?
- choix lexicaux (en) et syntaxiques : comment le dire ?
- choix rhétoriques : quand dire quoi ?
- présentation textuelle (ou orale) : le dire !
Ces choix sont loin d'aller de soi. Prenons les deux phrases suivantes[13] :
- You can only stay until 4.
- You have to leave by 4.
Qu'on peut traduire approximativement par Vous ne pouvez rester que jusque 16 heures et Vous devez être parti pour 16 heures. Ces deux phrases partagent une synonymie sémantique évidente, mais elles diffèrent par une nuance communicative. La phrase (1) met l'accent sur stay, (2) sur leave. Le choix lexical se fera en fonction du contexte : dans ce cas-ci, par exemple, si l'on souhaite porter l'attention sur l'activité en cours ou plutôt sur l'activité à venir.
Par conséquent, la GAT implique un grand nombre[14] de connaissances préalables[15] :
- connaissance du domaine couvert ;
- connaissance du langage spécifique de ce domaine ;
- connaissance rhétorique stratégique ;
- connaissance de l'ingénierie ;
- connaissance des habitudes et contraintes de l'utilisateur final.
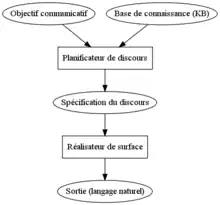
La formulation optimale devra tenir compte d'une série de facteurs, tels que la grammaticalité, l'absence d'ambiguïté, la cohérence, l'effet rhétorique souhaité. Mais également des contraintes sociales, discursives et pragmatiques. Les théories fonctionnelles du langage sont très utilisées en génération, car elles tentent d'intégrer ce type de facteurs[2].
La figure ci-contre présente un exemple d'architecture pour la GAT. Les deux composants principaux de cette architecture sont le Planificateur de discours (Discourse Planner) et le Réalisateur de surface (Surface Realizer). Le Planificateur sélectionne le contenu dans la base de connaissance et le structure en fonction de l'objectif communicatif. Ensuite, le Réalisateur de surface génère les phrases, selon les contraintes lexicales et syntaxiques qui lui sont implémentées, en suivant le plan spécifié par le Planificateur[11].
Notes et références
- En anglais « Natural language generation » ou NLG.
- Bateman & Zock (2003).
- (en) Alan Turing, « Computing machinery and intelligenc », Mind, .
- (en) Claude Shannon, « A Mathematical Theory of Communication », ACM SIGMOBILE, Mobile Computing and Communications Review, vol. 5, no 1,
- (en) Victor Yngve (en), « Random generation of English sentences », Proceedings of International Congress on Machine Translation and Applied Language Analysis, .
- (en) G. Matthew, « Analysis by synthesis of sentences of natural languages. », Proceedings International Congress on Machine Translation and Applied Language Analysis, .
- (en) Joyce Friedman, « Direct Random Generation of English Sentence. », Communications of the ACM, .
- Pour un large aperçu de l'état de l'art, voir Bateman (2002).
- Elhadad (1992).
- Bateman (1997).
- Vander Linden (2000)
- Adapté de Bateman & Zock (2003) et de Vander Linden (2000).
- Exemple emprunté à McDonald (1991).
- Nombre qui varie bien sûr en fonction du domaine traité et de la précision recherchée.
- Adapté de Bateman & Zock (2003).
Voir aussi
Bibliographie
- Bateman, J. (1997). Enabling technology for multilingual natural language generation: the KPML development environment. Journal of Natural Language Engineering, 3(1), 15-55.
- Bateman, J. (2002). Natural Language Generation: an introduction and open-ended review of the state of the art.
- Bateman, J. et M. Zock (2003). Natural Language Generation. The Oxford Handbook of Computational Linguistics. R. Mitkov (éd.), Oxford University Press, New York, 284-304.
- Danlos, L. (1985). Génération automatique de textes en langue naturelle. Paris : Masson.
- Elhadad, M. (1992). Using Argumentation to Control Lexical Choice: A Functional Unification-Based Approach. Ph.D. thesis, Department of Computer Science, Columbia University.
- McDonald, D. (1991). On the place of words in the generation process. Natural Language Generation in Artificial Intelligence and Computational Linguistics. C. Paris, W. Swartout et W. Mann (éds.), Kluwer, Dordrecht, 229-247.
- Vander Linden, K. (2000). Natural Language Generation. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. D. Jurafsky et J.H. Martin, Prentice Hall, Upper Saddle River, New Jersey, 763-798.
Articles connexes
Liens externes
- (en) KPML, one point access. Automatic Domain-independent Multilingual Natural Language (approche par grammaires spécialisées).
- (en) État de l'art en anglais par Bateman
- Génération automatique de textes en langue naturelle, Laurence Danlos, LINX, 1991], hors-série no 4, 1991. Texte et ordinateur. Les Mutations du Lire-Ecrire, pp. 197–214
- La génération automatique de textes : trente ans déjà, ou presque; M. Zock, G. Sabah, Langages, 26e année, no 106, 1992, pp. 8–35.