Techniques d'accélération matérielle de la virtualisation
La performance est l’un des problèmes majeurs de la virtualisation. Plusieurs solutions d’améliorations logicielles, matérielles et hybrides sont proposées.
Les techniques d’accélération matérielle de la virtualisation sont l’objet de cet article. Les solutions matérielles proposées pour améliorer les performances de la virtualisation sont basées sur des supports matériels pour lesquels des fonctions spécifiques ont été confiées afin qu'elles soient exécutées plus efficacement.
Objectif de l'accélération matérielle de la virtualisation
Les solutions logicielles de la virtualisation souffrent de problèmes de performances et de scalabilité[1].
L’accélération matérielle de la virtualisation a été introduite pour simplifier la mise en œuvre et améliorer les performances de la virtualisation[2]. Les principaux objectifs de la virtualisation sont les suivants : fournir un environnement dans lequel les applications peuvent être exécutées de manière fiable[3], adapter cet environnement d’exécution à l'application et limiter l’accès et l'utilisation des ressources matérielles par les techniques d'isolement [3]. La virtualisation est très utile quand le redimensionnement de l’environnement est nécessaire et si le système physique est en mesure de répondre, de nouvelles capacités peuvent être fournies localement, sur le même système physique[3].
Techniques d'accélération de la mémoire virtuelle
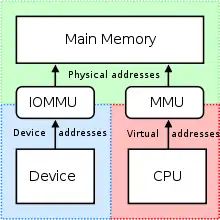
Principe de virtualisation de la mémoire
les E/S de l'unité de gestion de la mémoire (IOMMU) créent un ou plusieurs espaces d'adressages uniques qui peuvent être utilisés pour contrôler comment une opération DMA (accès direct à la mémoire) accède à la mémoire à partir d'un périphérique. Cette fonctionnalité peut également fournir un mécanisme par lequel les accès de périphériques sont isolés. La MMU maintient à jour le tableau de correspondance entre les adresses physiques et les adresses linéaires demandées par le système d'exploitation[4].
Technologie de virtualisation Intel VT
La technologie de virtualisation Intel propose une architecture d’E/S qui permet de fournir la liaison DMA (accès direct à la mémoire) aux matériels qui ajoute le support pour isoler des accès de périphériques à la mémoire ainsi que la translation des fonctionnalités. La liaison matérielle DMA intercepte le périphérique qui tente d'accéder à la mémoire système, ensuite elle utilise une table de pages d’E/S pour déterminer si l'accès est autorisé et son emplacement prévu.
La structure de traduction est unique pour une fonction utilisant un périphérique (bus PCI, périphérique et fonction) et est basée sur une table de pages à plusieurs niveaux. Chaque périphérique d'E/S reçoit l'espace d'adressage virtuel DMA identique à l'espace d'adressage physique ou un espace d'adressage purement virtuel défini par le logiciel.
La liaison matérielle DMA utilise une table indexée par bus PCI, périphérique et fonction pour trouver la racine de la table de traduction de l’adresse. Le matériel peut mettre en cache cette table ainsi que les traductions efficaces (IOTLB) [note 1] d'E/S de la table pour minimiser les coûts généraux encourus pendant l’extraction de cette table de la mémoire.
Les erreurs qui sont provoquées par la liaison matérielle sont détectées et traitées par le matériel qui fait remonter les erreurs à l’application à travers l'événement de panne (interruption)[5].
Technologie de virtualisation AMD-V
L'assistance à la virtualisation AMD pacifica AMD-V est la proposition d'AMD pour la gestion de la virtualisation des E/S en ajoutant un périphérique DEV[note 2] qui permet ou bloque l’accès direct à la mémoire sur des pages mémoires spécifiées. AMD-V est l’équivalent de Vt-d chez Intel[6].
Technologie de virtualisation d'IBM
Les puces PCI-X d'IBM fournissent la fonctionnalité matérielle IOMMU pour traduire et isoler les accès directes à la mémoire. Les traductions sont définies par un ensemble d'entrées de contrôle de traduction (TCE) dans une table de la mémoire système. La table peut être considérée comme un tableau où l'index est le numéro de page dans l'espace d'adressage du bus et le TCE à cet index décrit le numéro de page physique dans la mémoire système. Le TCE peut également contenir des informations supplémentaires telles que les droits d'accès de direction DMA et des dispositifs spécifiques (ou groupes de périphériques) de sorte que chaque traduction peut être considérée comme valide[5].
Technologie de virtualisation ARM
Afin de supporter la virtualisation les processeurs ARM ont recours à un troisième niveau de privilèges, EL2, en plus des niveaux EL0 et EL1 déjà présents et correspondant respectivement à l'espace utilisateur et l'espace kernel[7]. Ce niveau de privilège permet de configurer le processeur pour qu'il accepte les VMs. Il va permettre d'intercepter les accès au matériel depuis les différentes VMs afin de les contrôler[7].
Avec l'architecture ARMv8.1 une nouvelle fonctionnalité d'accélération de la virtualisation a été ajouté aux processeurs ARM le VHE[8]. Son but principal est d'accélérer les hyperviseurs de type 2 en permettant au système hôte de s’exécuter avec le niveau de privilège EL2 diminuant ainsi le coût de transition entre la VM et le système hôte[8]. Pour parvenir à cet objectif VHE propose trois choses. Premièrement il augmente le nombre de registres disponibles en mode EL2 afin d'en avoir le même nombre qu'en mode EL1 . Ensuite il offre un mécanisme de traduction d'instructions, ainsi les instructions d'accès aux registres EL1 seront automatiquement traduites pour accéder aux registres EL2 sans avoir besoin de modifier le code, supprimant ainsi le coût de sauvegarde des registres lors de la transition entre le système hôte et l'hyperviseur. La troisième et dernière fonctionnalité de VHE est d'unifier le format des pages mémoires entre EL1 et EL2 rendant les accès mémoire identique entre les deux modes de privilèges[9].
Pause Sortie de Boucle
La technique Pause Sortie de Boucle PLE [note 3] fournit l'assistance matérielle pour détecter le spinlock. Le CPU utilise l'instruction PAUSE comme indice de boucle de verrouillage au processeur. Cependant, l'instruction PAUSE est également utilisée dans le noyau du système d'exploitation à d'autres fins (comme dans une boucle de délai). La technologie permet à VMM de détecter le verrouillage de spin en surveillant l'exécution des instructions PAUSE à l'aide des valeurs PLE_Gap et PLE_Window. PLE_Gap est le nombre maximum de cycles entre deux exécutions successives de PAUSE dans une boucle. Le CPU détecte un spin-lock s'il identifie une série d'exécutions d'instructions PAUSE et que la latence entre deux exécutions successives se trouve dans la valeur PLE_Gap. PLE_Window est le temps maximum que prend un VCPU pour exécuter une boucle de spin. Si le temps d'exécution de boucle de spin surpasse la valeur PLE_Window, le CPU lancera une sortie VM pour avertir l'hyperviseur. Le gestionnaire de la pause de la sortie de boucle est responsable de la définition des valeurs PLE_Gap et PLE_Window [10].
La Table de page étendue (EPT)
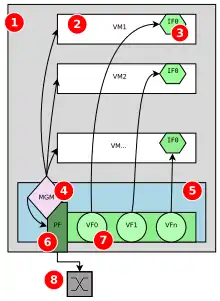
Cette technique est proposée pour éliminer les contenus excessifs de sortie VM et de verrouillage dans la Table de pages d'ombre (Shadow tables (en)). Avec la prise en charge de l'EPT, la Table des pages d'invité (GPT) contient le mappage de l'adresse mémoire invitée (GLA) à l'adresse physique invitée (GPA), tandis que l'EPT contient le mappage de l'adresse physique de l'invité à l'adresse physique de l'hôte. Le gestionnaire de l'EPT de XEN maintient un tableau de l'EPT pour gérer la traduction du GPA au HPA. L'invité de l'EPT récupère la propriété de ses tables de pages et par conséquent l'EPT peut complètement Éliminer la nécessité d'une protection contre l'écriture sur les accès de Table de pages invitée et évite tout à fait les excès de contenus VM-exit et lock. Avec l'EPT, le matériel parcourt à la fois la table des pages d'invités et l'EPT [11].
La racine unique d'E/S de la virtualisation (SR-IOV)
Le SR-IOV [note 4] est une méthode de virtualisation destinée aux périphériques PCI Express qui les rend accessibles à plusieurs machines virtuelles, sans avoir besoin de passer par la VMM. Un périphérique compatible SR-IOV a une seule ou plusieurs fonctions physiques (PF). Chaque PF peut créer de multiples instances d'entités de fonction PCI, appelées fonctions virtuelles (VF), qui sont configurées et gérées par les fonctions physiques. Chaque fonction virtuelle peut être attribuée à un invité pour un accès direct, tout en partageant les ressources principales du périphérique, afin de parvenir au partage des ressources et aux performances élevées [11].
Performance
Intel fournit le support matériel permettant d’activer un simple moniteur de machines virtuelles VMM[note 5]. Cependant, la simplicité et la performance sont souvent des objectifs concurrents. Le matériel du moniteur de machine virtuelle fonctionne mieux dans certaines expériences, mais globalement le logiciel moniteur de machine virtuel fournit une meilleure solution de virtualisation haute performance[12].
Pour mieux identifier efficacement les problèmes de performance dans l'environnement de virtualisation, il faut avoir de nouvelles boîtes à outils pour pouvoir mesurer les performances du moniteur de la machine virtuel VMM, car son architecture est très différente des systèmes d’exploitations ou des applications pour lesquelles la plupart des outils existants ont été développés. Avant Xen / VT, Xentrace était également disponible pour mesurer les performances dans l'environnement de la paravirtualisation. Il est très utile pour identifier les principaux goulets d'étranglement de performance[13].
Diagnostic du coût de gérer l’événement Exit de la machine virtuelle
Pour diagnostiquer les performances d’une architecture (exemple Xen / VT), tout d'abord, il faut mettre à profit des outils de performance améliorés et des outils de référence pour recueillir des données afin de montrer les principaux coût généraux dépensés en hyperviseurs. Ensuite, présenter des solutions pour résoudre les problèmes potentiels de la performance[13].
Pour obtenir un aperçu de la charge totale du logiciel pour gérer tous les types d'événements Exit de la machine virtuelle, une étude a été faite avec l’outil Xentrace qui a permis de suivre tous les événements Exit qui se produisent lorsque la charge de travail CPU2000 et la compilation de noyaux ont été exercés. Les résultats sont présentés dans le tableau ci-dessous :
| L’événement Exit | Nombre d’événements Exit | Gestion S/W (Cycle) | Temps Total de gestion |
|---|---|---|---|
| Io instruction | 14.09% | 202286 | 57.93% |
| Exception NMI | 77.19% | 24757 | 38.83% |
| CR Acess | 3.09% | 21064 | 1.32% |
Table 1 : Mesure des coûts de l'événement Exit pour CPU2000[14].
Diagnostic du coût des E/S de la machine virtuelle
Cette étude a montré que l'émulation E/S est le problème de performance critique à traiter. Dans cette section, des expériences ont été faites pour découvrir les cycles de CPU passés dans un accès d'E/S d’une machine invitée, en insérant plusieurs sondes sur l'horodatage d'échantillon de chaque point[15].
Pour isoler l'impact du temps d'émulation de port dans le modèle d'appareil, nous avons utilisé un port d'E/S factice pour la mesure expérimentale. Dans cette étude, le port d'E/S 0x22e a été utilisé, qui n'est pas implémenté dans la plate-forme virtuelle, puis on exécute une application simple dans HVM [note 6] invité qui lit de ce port d’une manière circulaire. En outre, on a désactivé également la virtualisation TSC[note 7] dans l'invité HVM, de sorte que les horodateurs TSC échantillonnés dans dom0, hyperviseur et HVM invité proviennent de la même source de temps matérielle et ont rendu le résultat expérimental plus précis[16].
Le résultat de cette expérience montre que le modèle de dispositif lui-même ne dépense que près d'un sixième du temps total (51.4K), mais l'interrupteur de processus dom0, dépensant plus de cycles, est l'un des principaux problèmes ayant une incidence sur les performances. En fait, le temps passé dans le domaine passe de nouveau au domaine HVM (c'est-à-dire, dom0 renonce au processeur quantum après l'achèvement de l'émulation d'E/S), provient principalement du commutateur de processus dans dom0 du modèle de périphérique au processus inactif, l'hypercall quand le processus est ralenti end_8259A_irq, tandis que le port 0x20 est écrit uniquement dans mask_and_ack_8259A pour EOI[16].
Performances des architectures ARM
Avec l'arrivée du support du 64 bits avec l'architecture ARMv8 il devient envisageable d'utiliser des processeurs ARM dans des serveurs. Les serveurs ayant massivement recourt à la virtualisation il est nécessaire d'évaluer les performances de ces processeurs pour la virtualisation.
Afin d'évaluer la latence générée par la virtualisation les chercheurs ont réalisé une série de microbenchmarks réalisant des opérations basiques[17]. Dans l'ensemble Xen génère de 2 à 10 fois moins d'overhead que KVM et obtient des performances comparables à Xen sur architecture x86 à l'exception des opérations de type E/S[18].
Dans un second temps les chercheurs ont effectué de nouveaux benchmarks à l'aide d'applications réellement utilisées afin de se rapprocher des conditions réelles d'utilisation des serveurs[19]. Dans ce cas les performances des deux architectures sont sensiblement les mêmes sur les deux types d'hyperviseurs[19], malgré des performances théoriques en retrait pour les hyperviseur de type 2.
L'architecture ARMv8 est beaucoup plus récente que l'architecture x86-64 ainsi elle n'est pas encore aussi bien exploitée au sein des hyperviseurs ce qui peut expliquer ses performances décevantes. L'architecture ARMv8.1 devrait régler les problèmes de performances en E/S avec les hyperviseurs de type 1 tout en améliorant également les performances des hyperviseurs de type 2 de 10% à 20% mais elle n'est pas encore disponible[20].
Enjeux économiques
Les résultats expérimentaux montrent une amélioration allant jusqu'à 77 % avec ces accélérations matérielles, dont 49% sont dus à la table de page étendue (EPT) et 28 % supplémentaires à la racine unique d'E/S de la virtualisation (SR-IOV)[21].
Historique
Les machines virtuelles sont utilisées depuis 1960 par IBM[22] avec des systèmes informatiques équipées de gros calculateurs, les Mainframes coûteux à fournir une compatibilité pour les clients[23]. En 1974, les prérequis de la virtualisation ont été définis par Gerald J. Popek (en) et Robert P. Goldberg (en), 1999 VMware ESX et Workstation, 2003 Xen, 2005 Intel VT-x, 2006 AMD-v, 2007 virtualBox par Inno Tech (acquisition par Sun en 2008)et en 2008 KVM (acquisition par Redhat)[24].
Bibliographie
Articles
- (en) Yaozu Dong, Xudong Zheng, Xiantao Zhang, Jinquan Dai, Jianhui Li, Xin Li, Gang Zhai et Haibing Guan, « Improving Virtualization Performance and Scalability with Advanced Hardware Accelerations », IEEE International Symposium on, , p. 1 - 10 (DOI 10.1109/IISWC.2010.5649499)
- (en) Yaozu Dong, Xiantao Zhang, Jinquan Dai et Haibing Guan, « HYVI: A HYbrid VIrtualization Solution Balancing Performance and Manageability », IEEE Journals & Magazines, vol. 25, no 9, , p. 2332 - 2341 (DOI 10.1109/TPDS.2013.239)
- (en) Nasim Robayet et J. Kassler Andreas, « Deploying OpenStack: Virtual Infrastructure or Dedicated Hardware Accelerations », IEEE, , p. 1 - 10 (DOI 10.1109/COMPSACW.2014.18)
- (en) Khalil Blaiech, Salaheddine Hamadi, Amina Mseddi et Omar Cherkaoui, « Data plane acceleration for virtual switching in data centers : NP-based approach », IEEE, , p. 108 - 113 (DOI 10.1109/CloudNet.2014.6968977)
- (en) Leonhard Nobach et David Hausheer, « Open, elastic provisioning of hardware acceleration in NFV environments », IEEE, , p. 1 - 5 (DOI 10.1109/NetSys.2015.7089057)
- (en) Jun Suzuki2010, Yoichi Hidaka, Junichi Higuchi, Teruyuki Baba, Nobuharu Kami et Takashi Yoshikawa, « Multi-root Share of Single-Root I/O Virtualization (SR-IOV) Compliant PCI Express Device », IEEE Conference Publications, , p. 25 - 31 (DOI 10.1109/HOTI.2010.21)
- (en) Salaheddine Hamadi2014, Ilyas snaiki et Omar Cherkaoui, « Fast Path Acceleration for Open vSwitch in Overlay Networks », IEEE Conference Publications, , p. 1-5 (DOI 10.1109/GIIS.2014.6934286)2014 Global Information Infrastructure and Networking Symposium (GIIS)
- (en) Jonghwan Kim, Kee Seong Cho et Won Ryu, « Screen Acceleration VNF scheme in NFV for VDI service », IEEE, , p. 816-818 (DOI 10.1109/ICTC.2015.7354673)Information and Communication Technology Convergence (ICTC), 2015 International Conference on
- (en) Soo-Cheol Oh, KwangWon Koh, Chei-Yol Kim et SeongWoon Kim, « Acceleration of dual OS virtualization in embedded systems », IEEE Conference Publications, , p. 1098 - 1101 (lire en ligne)
- (en) Xiantao Zhang et Yaozu Dong, « Optimizing Xen VMM Based on Intel® Virtualization Technology », IEEE, , p. 367 - 374 (DOI 10.1109/ICICSE.2008.81)
- (en) Hui Zhu, Zhifeng Zhang, Jun Wu, Dong Guo et Shaoxian Tang, « Scheduling Algorithm Design for Virtualized Hardware Accelerator in C-RAN », IEEE, , p. 25-29 (DOI 10.1109/ICCCRI.2016.13)Cloud Computing Research and Innovations (ICCCRI), 2016 International Conference on
- (en) Yaozu Dong, Xiaowei Yang, Jianhui Li et Guangdeng Liao, « High performance network virtualization with SR-IOV », Journal of Parallel and Distributed Computing, communication Architectures for Scalable Systems, vol. 72, no 11, , p. 1471–1480 (DOI 10.1016/j.jpdc.2012.01.020, lire en ligne, consulté le )
- (en) Christoffer Dall, Shih-Wei Li, Jin Tack Lim, Jason Nieh et Georgios Koloventzos, « ARM Virtualization: Performance and Architectural Implications », Computer Architecture (ISCA), 2016 ACM/IEEE 43rd Annual International Symposium on, , p. 304–316 (DOI 10.1109/ISCA.2016.35)
- (en) Muli Ben Yehuda, Jon Mason, Orran Krieger, Jimi Xenidis, Leendert Van Doorn, Asit Mallick, Jun Nakajima et Elsie Wahlig, Utilizing IOMMUs for Virtualization in Linux and Xen, , 1-15 p. (lire en ligne)
- (en) John Fisher-Ogden, Hardware Support for Efficient Virtualization, 1-12 p. (lire en ligne)
- Pascale Primet, Olivier Mornard et Jean-Patrick Gelas, Evaluation des performances réseau dans le contexte de la virtualisation XEN, , 1-20 p. (lire en ligne)
- Damien Dejean, La virtualisation vue de l’intérieur, (lire en ligne)
- (en) David Brash, The ARMv8-A architecture and its ongoing development, (lire en ligne)
Références
- Dong 2014, p. 2332
- Dong 2010, p. 1
- Primet 2007, p. 4
- Yehuda 2006, p. 1
- Yehuda 2006, p. 3
- Fisher-Ogden, p. 9
- Dall 2016, p. 3
- ARM, 2014
- Dall 2016, p. 10
- Dong 2010, p. 2,3
- Dong 2010, p. 3
- John, p. 6
- Xiantao, p. 368
- Xiantao, p. 369
- Xiantao, p. 370
- Xiantao, p. 371
- Dall 2016, p. 308
- Dall 2016, p. 309
- Dall 2016, p. 311
- Dall 2016, p. 315
- Dong 2010, p. 9
- Zhang 2008, p. 367
- Fisher-Ogden, p. 1
- Dejean 2013, p. 3
Notes
- IOTLB = I/O Translation Lookaside Buffer
- DEV = device exclusion vector
- PLE = pause loop exit
- SR-IOV = Single-Root Input/Output Virtualization
- VMM = Virtual Machine Monitor
- HVM = Hardware Virtual Machine
- TSC = Terminaison Synchronisation Circuit