Structure de données multidimensionnelles
Une structure de données multidimensionnelles est une structure logique permettant de stocker des couples de données afin de leur appliquer des traitements simplifiés.
Ce type de structure est utilisé dans des applications, telles que la géolocalisation, afin de stocker les positions comme un couple de données (Latitude/Longitude/Altitude).
Famille R-Tree
R-Tree[1]
Le R-Tree est un arbre équilibré, les feuilles de l'arbre contiennent un tableau indexé constitué des références vers les objets stockés. Tous les objets sont stockés dans une collection, chaque objet (ou tuple) possède un identifiant unique afin de pouvoir l'obtenir.
Structure
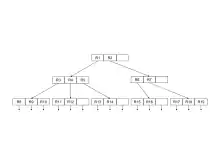
Les nœuds de l'arbre sont constitués d’éléments de la forme suivante :

- : l'adresse du nœud suivant.
- : un rectangle à n dimension contenant tous les rectangles de ces fils.


Les feuilles de l'arbre sont constituées d’éléments de la forme suivante :

- : un identifiant de tuple.
- : un rectangle à n dimension contenant les objets référencés par cette feuille.

Propriétés
Chaque rectangle représenté par est de la forme : , avec le nombre de dimension.


En prenant le postulat suivant :
- , le nombre d'éléments stockés.
- , le nombre maximum d'éléments dans un nœud.
- , le nombre minimum d'éléments dans un nœud.
- , un paramétrage du R-Tree.
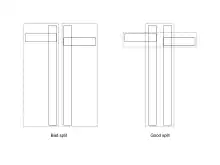 Une bonne et une mauvaise scission
Une bonne et une mauvaise scission




L'arbre possède les propriétés suivantes :
- Chaque nœud contient entre et éléments, sauf la racine.
- La racine contient au minimum deux fils sauf si la hauteur de l'arbre est de 0.
- Toutes les feuilles ont une profondeur égale.
- est le plus petit rectangle contenant les rectangles fils.
- est le plus petit rectangle contenant les éléments référencés par la feuille.
- , avec la hauteur de l'arbre.
- , le nombre maximum de nœud.





Hilbert R-Tree[2]
Cette structure est essentiellement la même que celle du R-Tree, seulement les nœuds sont triés par valeur d'Hilbert afin d'améliorer l'insertion, et par conséquent, obtenir de meilleur résultat que sur le R-Tree.
Nœuds
Chaque nœuds possède une valeur supplémentaire, appelé valeur d'Hilbert maximale. Cette valeur correspond à la valeur d'Hilbert maximale présente parmi tous ces fils.
Cette valeur d'Hilbert est calculée à l'aide de la Courbe d'Hilbert. La valeur d'Hilbert d'un rectangle, est la valeur d'Hilbert du centre du rectangle.
Scission
Dans le R-Tree, il faut attendre éléments avant de scinder un rectangle en deux sous-rectangles.

Le Hilbert R-Tree attend que le nœud possède éléments, et son père aussi avant de le scinder.
X-Tree[3]
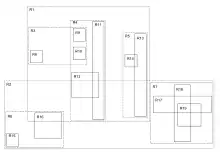
Cette structure a pour but d'améliorer la recherche du R-Tree, en effet la recherche dans le R-Tree se détériore très vite lorsque le nombre de dimensions augmente. Cependant, dans le pire des cas, la performance reste similaire au R-Tree.
Son but est de réduire la surface totale couverte par plusieurs rectangles du même nœud (pour une dimension 2).
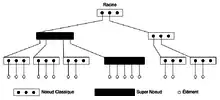
C'est dans ce but que le X-Tree différencie ces nœuds en deux catégories
- Les nœuds classiques, similaires au R-Tree
- Les super-nœuds.
Super-nœuds
Ces super-nœuds sont semblables aux nœuds classiques d'un R-Tree, cependant la différence se situe sur le nombre maximal d'éléments pouvant être contenus. Ce nombre est supérieur à celui des nœuds classiques.
Leur but est d'éviter la scission le plus possible, afin de réduire les chemins possibles dans l'arbre, et donc d'améliorer le temps de recherche.
Les super-nœuds sont créés à l'insertion lorsque la scission est inévitable.
Famille Kd-Tree
Kd-Tree[4]
Le kd-tree est un arbre binaire de recherche multidimensionnel où k représente la dimension de l'espace.
Structure
- Chaque nœud contient clés que nous nommerons .
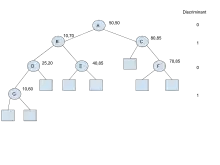 Exemple de 2d-tree
Exemple de 2d-tree - Chaque nœud contient deux pointeurs, qui soit sont nuls, soit pointent chacun vers un autre nœud de l'arbre.
- Pour un nœud , nous appellerons et ses deux pointeurs et son discriminant.
- Le discriminant commence à 0 pour le nœud à la racine.
- Pour un nœud ayant pour discriminant , ses deux fils et ont pour discriminant .









Propriétés
- Pour tout dans un kd-tree, soit , alors pour n'importe quel nœud ,
- Pour tout dans un kd-tree, soit , alors pour n'importe quel nœud ,




KDB-Tree[5]
Le KDB-tree est une solution pour stocker des enregistrements à clés multiples de grande taille. Pour cela, il s'appuie sur les forces du B-tree ainsi que sur celles du kd-tree afin de proposer un coût en entrée / sortie proche du premier lors de l'ajout ou de la suppression de données, ainsi qu'une performance de recherche proche du second.
Les enregistrements dans un KDB-tree sont de la forme où est un élément du et est une constante.



Tout comme pour le B-tree, chaque nœud est stocké comme une page. Nous distinguerons deux types de pages :
un point se décrit comme un élément du domaine


une région correspond quant à elle à l'ensemble de tous les points correspondant à , .



Propriétés
- Les pages dites régions pointent toujours vers des pages fils et ne peuvent pas être vides. Les pages dites points sont les feuilles de l'arbre.
- Comme le B tree, la taille du chemin de la racine jusqu'à n'importe quelle feuille est le même.
- Pour chaque page dite région, les régions dans cette page sont disjointes, et leur union est une région.
- Si la racine est une région, l'union de ses régions est alors , soit l'espace de recherche entier.
- Quand le fils d'une paire (région, fils) dans une page dite région est aussi une page région, l'union de toutes les régions du fils est une région.
- À l'inverse, si la page fils est un point, alors tous les points de la page doivent être dans la région.
BKD-Tree[6]
Parmi les nombreuses structures de données multidimensionnelles, la performance a tendance à baisser plus le nombre d'ajouts et de suppressions est élevé. En effet, il est compliqué de maintenir les trois caractéristiques suivantes simultanément :
- Un remplissage maximum de la structure
- Un changement minimal de la structure lors de l'ajout ou de la suppression de données.
- Un temps de recherche minimal pour un élément ou une zone de la structure.
L'ajout d'un nœud dans un kd-tree se fait en moyenne en , mais ne garde pas une structure équilibrée. En pratique, lors d'un grand nombre d'ajout, nous sommes donc face à une structure déséquilibrée, ce qui impacte sur la performance des requêtes. De plus, contrairement à certaines structures qui se rééquilibrent facilement pour un coût minimum, celle-ci nécessite le remaniement de larges zones, ce qui diminue fortement ses performances.

De la même manière, le KDB-tree demande potentiellement un large remaniement lors de l'ajout ou de la suppression d'une valeur dans l'arbre, ce qui nuit fortement aux performances de la structure au fur et à mesure que celle-ci se remplie.
Le BKD-tree propose une structure basée sur le KDB-tree qui permet une utilisation de la structure proche de 100% ainsi qu'une excellente performance d'ajout et de suppression comparable à celle du kd-tree. Cependant, contrairement à ce dernier, ces performances sont conservées, peu importe le nombre de requêtes effectuées.
Pour cela, au lieu de construire un seul arbre et de le rééquilibrer après chaque ajout ou suppression de données, il représente chaque sous-arbre comme un kd-tree, et détermine ainsi le strict minimum à rééquilibrer lors de mise à jour de la structure.
Famille Quad-Tree
Quad-Tree[7]
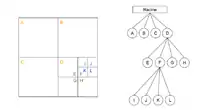
Le Quad-Tree permet de diviser récursivement l'espace en parties. Le Quad-Tree est utilisé pour un espace à 2 dimensions, cependant le concept peut s’étendre à dimensions.


Structure
Les nœuds de l'arbre sont de la structure suivante :

- , l'espace couvert par le nœud en question.
- , l'ensemble des éléments couverts par ce nœud.

Propriétés
En prenant le postulat suivant :
- , le nombre maximal d'éléments dans un nœud.
- , le nombre de dimensions.
- , la surface totale couverte par l'arbre
- , la profondeur d'un nœud.


L'arbre possède les propriétés suivantes :
- Si un nœud possède éléments, alors ces derniers sont repartis dans fils, chacun représentant une fraction égale de l'espace couvert par .
- Un nœud de profondeur couvre de S

Famille Patricia-Tree
Patricia-Tree[8]
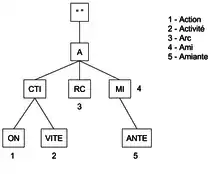
Le terme "Patricia" signifie "Practical Algorithm To Retrieve Information Coded In Alphanumeric".
Le Patricia-Tree permet de stocker des chaines de caractères de manières optimisée, en termes de performance, et d'espace.
Ce type d'arbre est souvent utilisé pour la prédiction de mot contenu dans un dictionnaire.
Structure
Les nœuds de l'arbre sont de la structure suivante :

- Une chaîne de caractère.
Propriétés
En prenant le postulat suivant :
- , la taille du mot le plus long stocké dans l'arbre.
- La racine correspond à la chaîne vide.

L'arbre possède les propriétés suivantes :
- Tous les fils d'un nœud correspondent à des mots ayant un préfixe commun.
- Plus les mots stockés dans l'arbre possèdent des préfixes, plus l'espace mémoire est optimisé.
- La profondeur de l'arbre est égale à
Famille PH-Tree
PH-Tree[9]
Le PH-Tree reprend deux concepts, ceux de la famille des Patricia-Tree, ainsi que ceux du Quad-Tree (Hypercube, lorsqu'on étend le concept à dimensions).
Cet arbre, à la différence des Patricia-Tree, ne se contente pas de stocker des chaines de caractères, il permet de stocker des objets complexes, par exemple des tuples de entiers.
Pour ce faire, le PH-Tree stocke des bits à la place des caractères.
Structure
Les nœuds de l'arbre sont de la structure suivante :

- , les premiers bits partagés.
- , un tableau de cases, contenant chacune bits.
- , un tableau de cases, contenant chacune bits, représente la fin de la représentation binaire de l'objet stocké.



La racine de l'arbre est de la structure suivante :

- , un tableau de cases, contenant chacune bits.
Propriétés
En prenant le postulat suivant :
- , la taille de la représentation binaire la plus longue stockée.
- On peut interpréter la racine comme l'objet

L'arbre possède les propriétés suivantes :
- Tous les fils d'un nœud possèdent le même début de représentation binaire pour chaque dimension.
- Plus les objets stockés dans l'arbre possèdent des représentations binaires communes, plus l'espace mémoire est optimisé.
- La profondeur de l'arbre est égale à
Comparatif
Le tableau ci-dessous reprend une liste non exhaustive des complexités des différentes opérations appliquées aux structures décrites.
| Complexité | |||||
|---|---|---|---|---|---|
| Insertion | Modification | Suppression | Recherche | ||
| Tree | R | ||||
| Hilbert | |||||
| X | |||||
| KD | |||||
| BKD | |||||
| KDB | |||||
| Quad | |||||
| Patricia | |||||
| PH | |||||






Références
- Antonin Guttman, « R-trees: A Dynamic Index Structure for Spatial Searching », SIGMOD, ACM, sIGMOD '84, (ISBN 0-89791-128-8, DOI 10.1145/602259.602266, lire en ligne)
- Ibrahim Kamel et Christos Faloutsos, « Hilbert R-tree: An Improved R-tree Using Fractals », VLBD, Morgan Kaufmann Publishers Inc., vLDB '94, (ISBN 1-55860-153-8, lire en ligne)
- Stefan Berchtold, Daniel A. Keim et Hans-Peter Kriegel, « The X-tree: An Index Structure for High-Dimensional Data », VLDB, Morgan Kaufmann Publishers Inc., vLDB '96, (ISBN 1-55860-382-4, lire en ligne)
- Jon Louis Bentley, « Multidimensional Binary Search Trees Used for Associative Searching », Commun. ACM, vol. 18, (ISSN 0001-0782, DOI 10.1145/361002.361007, lire en ligne)
- John T. Robinson, « The K-D-B-tree: A Search Structure for Large Multidimensional Dynamic Indexes », SIGMOD, ACM, sIGMOD '81, (ISBN 0-89791-040-0, DOI 10.1145/582318.582321, lire en ligne)
- (en) Octavian Procopiuc, Pankaj K. Agarwal, Lars Arge et Jeffrey Scott Vitter, Bkd-Tree: A Dynamic Scalable kd-Tree, Springer Berlin Heidelberg, coll. « Lecture Notes in Computer Science », (ISBN 978-3-540-40535-1 et 978-3-540-45072-6, DOI 10.1007/978-3-540-45072-6_4, lire en ligne)
- (en) R. A. Finkel et J. L. Bentley, « Quad trees a data structure for retrieval on composite keys », Acta Informatica, vol. 4, (ISSN 0001-5903 et 1432-0525, DOI 10.1007/BF00288933, lire en ligne)
- Donald R. Morrison, « PATRICIA—Practical Algorithm To Retrieve Information Coded in Alphanumeric », J. ACM, vol. 15, (ISSN 0004-5411, DOI 10.1145/321479.321481, lire en ligne)
- Tilmann Zäschke, Christoph Zimmerli et Moira C. Norrie, « The PH-tree: A Space-efficient Storage Structure and Multi-dimensional Index », SIGMOD, ACM, sIGMOD '14, (ISBN 978-1-4503-2376-5, DOI 10.1145/2588555.2588564, lire en ligne)