ParaView
ParaView est un logiciel libre de visualisation de données (voir par exemple Représentation graphique de données statistiques, Représentation cartographique de données statistiques, Visualisation scientifique). Il est fondé sur la bibliothèque VTK et publié sous licence BSD. Il est développé principalement par le Sandia National Laboratories (Lockheed Martin Corporation), le Los Alamos National Laboratory et la société Kitware Inc.
| Développé par | Kitware et Utkarsh Ayachit (d) |
|---|---|
| Dernière version | 5.11.0 ()[1] |
| Écrit en | C, C++, Python et Fortran |
| Interface | Qt |
| Système d'exploitation | Unix et type Unix |
| Environnement | Multiplateforme |
| Formats lus | VTK, CFD General Notation System et Extensible data model and format |
| Formats écrits | ParaView VTK Image data (d), ParaView VTK Structured grid (d), ParaView state (d) et ParaView VTK Unstructured grid (d) |
| Type |
Logiciel de modélisation tridimensionnelle Logiciel de tracé de diagramme (d) |
| Licence | Licence BSD |
| Site web | www.paraview.org |
ParaView dispose d'une architecture client-serveur qui permet de traiter des données à distance ; typiquement, pour un volume de données important, tout ou partie du traitement est effectué par un serveur, le poste de travail servant uniquement à l'affichage. En visualisation volumique, il réduit le niveau de détail des objets éloignés afin de maintenir une bonne vitesse d'affichage (méthode dite du level of detail, LOD).
Historique
Le projet a démarré en 2000, sous la forme d'une collaboration entre Kitware Inc. et le Los Alamos National Laboratory. La première version publiée, la 0.6, sort en . En 2005, l'interface utilisateur est entièrement repensée, et cette nouvelle interface est intégrée dans la version 3.0 sortie en 2007.
Interface
Dans la logique de VTK, le processus de visualisation consiste à appliquer différents filtres aux données. Le terme filtre est générique et peut désigner divers processus de transformation : extraction, tri, calculs, … La démarche globale est donc :
- le chargement des données (première opération) ;
- l'application successive de filtres ;
- l'affichage des données.
Les différents processus sont représentés dans une arborescence appelée pipeline (tuyau, dataduc). Les données initiales ne sont pas modifiées, elles sont copiées à chaque étape, même s'il peut s'agir d'une copie virtuelle (shallow copy, le logiciel pointe vers les données plutôt que de les dupliquer) lorsqu'il n'y a pas de modification. Ainsi, il est possible de revenir en arrière, ou de repartir d'un état antérieur des données pour générer un nouvel affichage.
Représentation interne des données
Toujours dans la logique de VTK, la base de la représentation est la notion de grille (grid), de maillage (au sens des éléments finis). Les données sont des champs, c'est-à-dire la donnée de valeurs — scalaires, vectorielles[2] — à des points définis par un maillage.
Les valeurs peuvent être définies aux nœuds du maillage, ou bien pour une maille (élément). Si les valeurs sont définies aux nœuds, alors les valeurs sont interpolées pour avoir une variation continue. Si les valeurs sont définies aux mailles, les valeurs sont considérées comme uniformes dans chaque maille.
Le maillage peut être défini de manière explicite — on indique les coordonnées de tous les nœuds (coordonnées explicites), on indique quels nœuds forment telle maille (topologie explicite) — ou implicite :
- si le maillage est un pavage régulier de segments (1D), rectangles (2D) de parallélépipèdes rectangles (3D) tous identiques (grille rectiligne uniforme, de type image matricielle), alors la grille est définie de manière implicite : on indique le nombre de points sur chaque axe, la position de l'origine et l'espacement sur chaque axe ; ainsi, quel que soit le nombre de nœuds, la grille est donc décrite par trois nombres en 1D, six nombres en 2D et neuf nombres en 3D ;
- si le pavage consiste en des rectangles tous alignés mais de dimensions différentes (grille rectiligne), la représentation est semi-implicite : on indique la position des nœuds sur chaque axe ; ainsi, si l'axe i a ni nœuds, la représentation des ∏ni nœuds nécessite la données de ∑ni valeurs ; par exemple, pour un maillage volumique de 10×10×10 = 1 000 nœuds, il faut 10 + 10 + 10 = 3 valeurs ;
- s'il s'agit d'un pavage curviligne (structuré), c'est-à-dire que les mailles sont des rectangles bien que les points soient sur de courbes, alors les nœuds sont représentés de manière explicite : il faut indiquer les coordonnées de chaque nœuds ; par contre, la topologie est toujours implicite, c'est-à-dire qu'il n'est pas nécessaire de définir les mailles (de même que pour les cas précédents) ;
- s'il s'agit d'un maillage non structuré, par exemple par des triangles (2D), des tétraèdres (3D) ou par des types de mailles différents, alors la description est totalement explicite (coordonnées et topologie).
ParaView gère aussi les maillages adaptatifs de type Berger-Oliger (ARM : adaptative refinement mesh) : il s'agit de maillages localement rectilinéaires uniformes, c'est-à-dire que sur une zone rectangulaire donnée, le maillage est rectilinéaire uniforme, mais la dimension des mailles varie d'une zone à l'autre. Cela permet de représenter plus finement certaines zones, typiquement celles où les variations des valeurs sont les plus fortes (affinement local), tout en gardant un volume de données raisonnable.
 Pavage rectilinéaire uniforme
Pavage rectilinéaire uniforme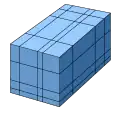 Pavage rectilinéaire
Pavage rectilinéaire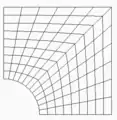 Pavage curvilinéaire (grille dite « structurée »)
Pavage curvilinéaire (grille dite « structurée »)
Performances et récompenses
À la date de 2013, ParaView a démontré qu'il pouvait travailler sur des modèles possédant des milliards de cellules non-structurées, ou sur des modèles possédant plus d'un billion de cellules structurées, et avec une architecture parallèle comprenant plus de 100 000 processeurs[3].
Le logiciel a été primé par le site HPCwire :
Programmation
L'utilisateur peut programmer ses propres filtres (scripts) en Python ou en C++.
L'application utilisateur (client) ParaView est construite sur un ensemble de composants VTK et Qt réutilisables. Il est possible de créer de nouvelles applications ParaView soit en modifiant le fichier Qt UI décrivant l'interface principale de l'application, soit en utilisant ces composants pour construire une application avec une interface différente.
Notes et références
- « https://discourse.paraview.org/t/paraview-5-11-0-available-for-download/10795 »
- Il n'existe pas de manière simple de représenter un champ tensoriel de plus grande dimension ; on se ramène en général à une valeur scalaire ou vectorielle « équivalente », ou bien à plusieurs représentations
- Kenneth Moreland, The ParaView Tutorial : version 4.0, Sandia National Laboratories, (lire en ligne), p. 1
- 2016 Annual HPCwire Editors' Choice Awards
- 2012 Annual HPCwire Readers' Choice Awards
- |2010 Annual HPCwire Readers' Choice Awards