Jeux d'entrainement, de validation et de test
En apprentissage automatique, une tâche courante est l'étude et la construction d'algorithmes qui peuvent apprendre et faire des prédictions sur les données[1]. De tels algorithmes fonctionnent en faisant des prédictions ou des décisions basées sur les données[2], en construisant un modèle mathématique à partir des données d'entrée. Ces données d'entrée utilisées pour construire le modèle sont généralement divisées en plusieurs jeux de données . En particulier, trois jeux de données sont couramment utilisés à différentes étapes de la création du modèle : les jeux d'apprentissage, de validation et de test.
Le modèle est initialement ajusté sur un jeu de données d'apprentissage[3] qui est un jeu d'exemples utilisés pour ajuster les paramètres (par exemple, les poids des connexions entre les neurones dans les réseaux de neurones artificiels ) du modèle[4]. Le modèle (par exemple un classificateur naïf de Bayes ) est entraîné sur le jeu de données d'apprentissage à l'aide d'une méthode d'apprentissage supervisé, par exemple à l'aide de méthodes d'optimisation telles que la descente de gradient ou la descente de gradient stochastique . En pratique, le jeu de données d'apprentissage se compose souvent de paires d'un vecteur d'entrée (ou scalaire) et du vecteur (ou scalaire) de sortie correspondant, où la variable de réponse est communément appelée cible (ou étiquette ou encore tag). Le modèle est exécuté avec le jeu de données d'apprentissage et produit un résultat, qui est ensuite comparé à la cible, pour chaque vecteur d'entrée dans le jeu de données d'apprentissage. Sur la base du résultat de la comparaison et de l'algorithme d'apprentissage spécifique utilisé, les paramètres du modèle sont ajustés. L'ajustement du modèle peut inclure à la fois la sélection de variables et l'estimation des paramètres.
Successivement, le modèle ajusté est utilisé pour prédire les réponses pour les observations dans un deuxième jeu de données appelé jeu de données de validation[3]. Le jeu de données de validation fournit une évaluation impartiale d'un ajustement de modèle sur le jeu de données d'apprentissage tout en ajustant les hyperparamètres [5] (par exemple, le nombre d'unités cachées - couches et largeurs de couche - dans un réseau de neurones[4]). Les jeux de données de validation peuvent être utilisés pour la régularisation par arrêt anticipé (arrêt de l'entraînement lorsque l'erreur sur le jeu de données de validation augmente, car cela est un signe de sur-apprentissage du jeu de données d'entraînement)[6]. Cette procédure d'apparence simple est compliquée en pratique par le fait que l'erreur du jeu de données de validation peut fluctuer pendant l'apprentissage, produisant plusieurs minima locaux. Cette complication a conduit à la création de nombreuses règles ad hoc pour décider quand le sur-apprentissage a vraiment commencé[6].
Enfin, le jeu de données de test est un jeu de données utilisé pour fournir une évaluation impartiale d'un ajustement final du modèle sur le jeu de données d'apprentissage[5]. Si les données du jeu de données de test n'ont jamais été utilisées dans l'apprentissage (par exemple en validation croisée), le jeu de données de test est également appelé jeu de données d'exclusion. Le terme « jeu de validation » est parfois utilisé au lieu de « jeu de test » dans certaines publications (par exemple, si le jeu de données d'origine a été divisé en deux sous-ensembles seulement, le jeu de test peut être appelé jeu de validation)[5].
Décider des tailles et des stratégies pour la division des jeux de données dans les jeux d'apprentissage, de test et de validation dépend beaucoup du problème et des données disponibles[7].
Jeu de données d'entraînement
Un jeu de données d'apprentissage est un ensemble de données d'exemples utilisé pendant le processus d'apprentissage et est utilisé pour ajuster les paramètres (par exemple, les poids) d'un classificateur, par exemple[8] - [9].
Pour les tâches de classification, un algorithme d'apprentissage supervisé examine le jeu de données d'apprentissage pour déterminer, ou apprendre, les combinaisons optimales de variables qui généreront un bon modèle prédictif[10]. L'objectif est de produire un modèle entraîné (ajusté) qui se généralise bien aux nouvelles données inconnues[11]. Le modèle ajusté est évalué à l'aide de « nouveaux » exemples issus des jeux de données conservés (jeux de données de validation et de test) pour estimer la précision du modèle dans la classification de nouvelles données[5]. Pour réduire le risque de problèmes tels que le sur-apprentissage, les exemples des jeux de données de validation et de test ne doivent pas être utilisés pour entraîner le modèle[5].
La plupart des approches qui recherchent dans les données d'apprentissage des relations empiriques ont tendance à surajuster les données, ce qui signifie qu'elles peuvent identifier et exploiter des relations apparentes dans les données d'apprentissage qui ne sont pas valables en général.
Jeu de données de validation
Un jeu de données de validation est un jeu de données d'exemples utilisés pour régler les hyperparamètres (c'est-à-dire l'architecture) d'un classifieur[12] Un exemple d'hyperparamètre pour les réseaux de neurones artificiels comprend le nombre d'unités cachées dans chaque couche[8] - [9]. Celui-ci, ainsi que le jeu de test (comme mentionné ci-dessus), doit suivre la même Loi de probabilité que le jeu de données d'apprentissage.
Afin d'éviter le surapprentissage, lorsqu'un paramètre de classification doit être ajusté, il est nécessaire de disposer d'un jeu de données de validation en plus des jeux de données d'apprentissage et de test. Par exemple, si le classificateur le plus approprié pour le problème est recherché, le jeu de données d'apprentissage est utilisé pour entraîner les différents classificateurs candidats, le jeu de données de validation est utilisé pour comparer leurs performances et décider lequel prendre et, enfin, le jeu de test est utilisé pour obtenir les caractéristiques de performance telles que la précision, la sensibilité, la spécificité, la mesure F, etc. Le jeu de données de validation fonctionne comme un hybride : ce sont des données d'entraînement utilisées pour les tests, mais ni dans le cadre de la formation de bas niveau ni dans le cadre du test final.
Une application de ce processus est en arrêt anticipé, où les modèles candidats sont des itérations successives du même réseau, et la formation s'arrête lorsque l'erreur sur le jeu de validation augmente, en choisissant le modèle précédent (celui avec l'erreur minimale).
Jeu de données de test
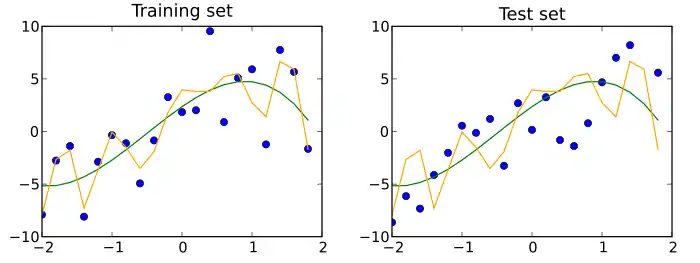
Un jeu de données de test est un jeu de données indépendant du jeu de données d'apprentissage, mais qui suit la même distribution de probabilité que le jeu de données d'apprentissage. Si un modèle ajusté au jeu de données d'apprentissage s'adapte également bien au jeu de données de test, un surajustement minimal a eu lieu (voir la figure ci-dessous). Un meilleur ajustement du jeu de données d'apprentissage par opposition au jeu de données de test indique généralement un surajustement.
Un jeu de test est donc un jeu d'exemples utilisés uniquement pour évaluer les performances (c'est-à-dire la généralisation) d'un classificateur entièrement spécifié[8] - [9]. Pour ce faire, le modèle final est utilisé pour prédire les classifications des exemples dans le jeu de test. Ces prédictions sont comparées aux véritables classifications des exemples pour évaluer la précision du modèle[10].
Dans un scénario où les jeux de données de validation et de test sont utilisés, le jeu de données de test est généralement utilisé pour évaluer le modèle final sélectionné au cours du processus de validation. Dans le cas où le jeu de données d'origine est partitionné en deux sous-ensembles (jeu de données d'entraînement et de test), le jeu de données de test peut évaluer le modèle une seule fois (par exemple, dans la méthode d'exclusion )[13]. Notez que certaines sources déconseillent une telle méthode[11]. Cependant, lors de l'utilisation d'une méthode telle que la validation croisée, deux partitions peuvent être suffisantes et efficaces, car les résultats sont moyennés après des cycles répétés d'entraînement et de test du modèle pour aider à réduire les biais et la variabilité[5] - [11].
Confusion dans la terminologie
Tester, c'est essayer quelque chose pour le découvrir et valider, c'est prouver que quelque chose est valide. Dans cette perspective, l'utilisation la plus courante des termes jeu de test et jeu de validation est celle décrite ici. Cependant, tant dans l'industrie que dans le milieu universitaire, ils sont parfois utilisés de manière interchangeable, en considérant que le processus interne teste différents modèles à améliorer (jeu de test en tant qu'ensemble de développement) et que le modèle final est celui qui doit être validé avant une utilisation réelle avec une donnée invisible (jeu de validation). La littérature sur l'apprentissage automatique inverse souvent le sens des jeux de 'validation' et de 'test'. C'est l'exemple le plus flagrant de la confusion terminologique qui imprègne la recherche en intelligence artificielle[14]. Néanmoins, le concept important qui doit être conservé est que le jeu de données final, qu'il soit appelé test ou validation, ne doit être utilisé que dans l'expérience finale.
Validation croisée
Afin d'obtenir des résultats plus stables et d'utiliser toutes les données précieuses pour l'entraînement, un jeu de données peut être divisé à plusieurs reprises en plusieurs jeu de données d'entraînement et de validation. C'est ce qu'on appelle la validation croisée. Pour valider les performances du modèle, un jeu de données de test supplémentaire, qui n'est pas soumis à la validation croisée, est normalement utilisé.
Articles connexes
Références
- Ron Kohavi et Foster Provost, « Glossary of terms », Machine Learning, vol. 30, , p. 271–274 (DOI 10.1023/A:1007411609915, lire en ligne)
- Christopher M. Bishop, Pattern Recognition and Machine Learning, New York, Springer, (ISBN 0-387-31073-8), vii :
« Pattern recognition has its origins in engineering, whereas machine learning grew out of computer science. However, these activities can be viewed as two facets of the same field, and together they have undergone substantial development over the past ten years. »
- Gareth James, An Introduction to Statistical Learning: with Applications in R, Springer, (ISBN 978-1461471370, lire en ligne), p. 176
- Brian Ripley, Pattern Recognition and Neural Networks, Cambridge University Press, (ISBN 978-0521717700, lire en ligne), 354
- Brownlee, « What is the Difference Between Test and Validation Datasets? », (consulté le )
- Lutz Prechelt et Geneviève B. Orr, Neural Networks: Tricks of the Trade, Springer Berlin Heidelberg, coll. « Lecture Notes in Computer Science », , 53–67 (ISBN 978-3-642-35289-8, DOI 10.1007/978-3-642-35289-8_5, lire en ligne), « Early Stopping — But When? »
- « Machine learning - Is there a rule-of-thumb for how to divide a dataset into training and validation sets? », Stack Overflow (consulté le )
- Ripley, B.D. (1996) Pattern Recognition and Neural Networks, Cambridge: Cambridge University Press, p. 354
- "Subject: What are the population, sample, training set, design set, validation set, and test set?", Neural Network FAQ, part 1 of 7: Introduction (txt), comp.ai.neural-nets, Sarle, W.S., ed. (1997, last modified 2002-05-17)
- D. T. Larose et C. D. Larose, Discovering knowledge in data : an introduction to data mining, Wiley, (ISBN 978-0-470-90874-7, OCLC 869460667, DOI 10.1002/9781118874059)
- Xu et Goodacre, « On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning », Journal of Analysis and Testing, Springer Science and Business Media LLC, vol. 2, no 3, , p. 249–262 (ISSN 2096-241X, DOI 10.1007/s41664-018-0068-2)
- (en) « Deep Learning », Coursera (consulté le )
- Kohavi, A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection, vol. 14, (lire en ligne)
- Ripley, Brian D., Pattern recognition and neural networks, Cambridge Univ. Press, , Glossary (ISBN 9780521717700, OCLC 601063414)