Régularisation (mathématiques)
Dans le domaine des mathématiques et des statistiques, et plus particulièrement dans le domaine de l'apprentissage automatique, la régularisation fait référence à un processus consistant à ajouter de l'information à un problème, s'il est mal posé ou pour éviter le surapprentissage. Cette information prend généralement la forme d'une pénalité envers la complexité du modèle. On peut relier cette méthode au principe du rasoir d'Occam. D'un point de vue bayésien, l'utilisation de la régularisation revient à imposer une distribution a priori sur les paramètres du modèle.
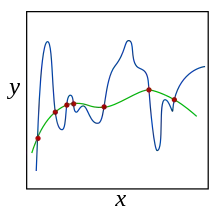
Une méthode généralement utilisée est de pénaliser les valeurs extrêmes des paramètres, qui correspondent souvent à un surapprentissage. Pour cela, on va utiliser une norme sur ces paramètres, que l'on va ajouter à la fonction qu'on cherche à minimiser. Les normes les plus couramment employées pour cela sont L₁ et L₂ . L₁ offre l'avantage de revenir à faire une sélection de paramètres, mais elle n'est pas différentiable, ce qui peut être un inconvénient pour les algorithmes utilisant un calcul de gradient pour l'optimisation[1] - [2].
Références
- Andrew, Galen; Gao, Jianfeng (2007). "Scalable training of L₁-regularized log-linear models". Proceedings of the 24th International Conference on Machine Learning. doi:10.1145/1273496.1273501. (ISBN 9781595937933).
- Tsuruoka, Y.; Tsujii, J.; Ananiadou, S. (2009). "Stochastic gradient descent training for l1-regularized log-linear models with cumulative penalty". Proceedings of the AFNLP/ACL.