Jeu d'instructions
Le jeu d'instructions est l'ensemble des instructions-machine qu'un processeur d'ordinateur peut exécuter. Ces instructions-machines permettent d'effectuer des opérations élémentaires (addition, ET logique…) ou plus complexes (division, passage en mode basse consommation…). Le jeu d'instructions définit quelles sont les instructions supportées par le processeur. Le jeu d'instructions précise aussi quels sont les registres du processeur manipulables par le programmeur (les registres architecturaux).
Principales familles
Parmi les jeux d'instructions principaux des années 1980 à 2020, nous avons, pour les microprocesseurs :
- Z80 (8 bits, CISC) ;
- 6502 (8 bits, CISC) ;
- x86 (16, puis 32 bits, CISC) ;
- VAX (32 bits) ;
- Alpha (64 bits, RISC) ;
- SPARC (32, puis 64 bits, RISC) ;
- MIPS (32 puis 64 bits, RISC) ;
- 68000 (16/32 puis 32 bits, CISC) ;
- IA-64 (version 64 bits de x86 par Intel n'ayant pas percé, abandonné, CISC) ;
- AMD64 (version 64 bits de x86 par AMD, aujourd'hui la plus répandue de la famille x86, CISC) ;
- PowerPC (32, puis 64 bits, RISC) ;
- ARM (16, 32, puis 64 bits, RISC) ;
- RISC-V (32, 64 et 128 bits, RISC), un format ouvert.
Et pour les microcontrôleurs :
Langage machine
Le jeu d'instructions précise non seulement les registres et instructions supportées par le processeur, mais aussi la façon dont ces instructions et les opérandes sont représentés en mémoire.

Chaque instruction-machine contient un code qui indique l'instruction à exécuter : addition, multiplication, branchement, etc. Ce code est appelé le code opération, en abrégé opcode. (Toutefois, certaines transport triggered architectures n'ont qu'une seule instruction, donc l'opcode est inutile ; mais c'est un cas très particulier.)
Une instruction, comme l'addition, s'applique généralement à des opérandes. Suivant les cas, chaque opérande est indiqué comme une valeur constante, une adresse, un registre, un décalage (offset), etc. (Toutefois, sur les machines à pile, les opérandes sont au sommet de la pile, donc à nouveau il est inutile de les indiquer.)
Cette représentation des instructions est fixée une fois pour toutes par le jeu d'instructions. Celui-ci précise quel opcode correspond à telle ou telle instruction, quels sont les opérandes permis, quels sont les modes d'adressage possibles pour chaque instruction, etc. L'ensemble de cette spécification s'appelle le langage machine.
Sur les architectures VLIW, plusieurs opcodes et opérandes peuvent être fournis en une seule instruction, permettant à celle-ci de demander l’exécution simultanée de plusieurs opérations.
Classes des jeux d'instructions
On distingue plusieurs familles de jeux d'instructions, selon la façon dont les instructions accèdent à leurs opérandes, leur codage et leur complexité. Les jeux d'instructions des processeurs diffèrent aussi dans la façon dont sont spécifiés les opérandes des instructions. Voici schématiquement représentées différentes classes.
Légende :
- Les registres, l'accumulateur ou la pile sont représentés dans les tons jaunes ;
- La mémoire centrale est représentée dans les tons mauves ;
- Le chemin de données (mode lecture) entre registres (ou l'accumulateur ou la pile) et l'Unité Arithmétique et Logique est en vert ;
- Le chemin de données (mode écriture) entre la sortie de l'Unité Arithmétique et Logique et les registres (ou l'accumulateur ou la pile) est en bleu ;
- Le chemin de données (mode lecture ou écriture) avec la mémoire est en violet.
« 0 adresse »

Dans cette architecture, les instructions vont directement agir sur la pile. Les opérandes sont automatiquement chargés depuis le pointeur de pile (SP, Stack Pointer), et le résultat est à son tour empilé.
L'opération A = B + C sera traduite par la séquence suivante :
PUSH B ; Empile B PUSH C ; Empile C ADD ; Additionne B et C POP A ; Stocke le haut de la pile à l'adresse A et dépile
Avec cette architecture, les instructions arithmétiques et logiques sont vraiment très courtes : leurs opérandes sont placés au sommet de la pile, et sont adressés implicitement : le processeur n'a pas besoin de préciser leur localisation dans la mémoire. En conséquence, ces instructions sont souvent constituées d'un seul et unique opcode. Ces opérations étant assez courantes, la taille moyenne d'une instruction est donc très faible. En conséquence, la taille des programmes d'une architecture « 0-adresse » est très faible comparée aux autres architectures. On résume cet état de fait en disant que la « code density » (la densité du code) est bonne.
Malheureusement, l'usage d'une pile pose quelques problèmes. Par exemple, il est impossible d'utiliser plusieurs fois la même donnée dans des calculs différents. Il faut dire que chaque opération arithmétique ou logique va automatiquement dépiler les opérandes qu'elle utilise. Dans ces conditions, si un opérande peut être utilisé dans plusieurs calculs, celui-ci doit être recalculé à chaque fois. Diverses instructions ont été inventées pour limiter la casse : des instructions permettant de permuter deux opérandes dans la pile, des instructions permettant de dupliquer le sommet de la pile, etc. Mais ce problème demeure.
Ce type d'architecture a été utilisé dans les calculatrices HP fonctionnant en notation polonaise inversée (post-fixée), dans les machines Burroughs de la gamme B 5000 et les miniordinateurs Hewlett-Packard de la gamme HP 3000. Il est aussi utilisé pour le FPU des processeurs x86.
« à accumulateur »
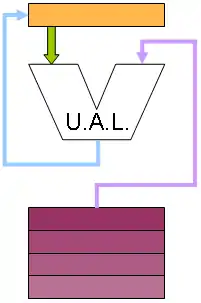
Sur une machine de ce type, historiquement ne disposant que d'un seul registre, appelé Accumulateur, tous les calculs se font implicitement sur celui-ci.
L'opération A = B + C sera traduite par la séquence suivante :
LOAD B ; copie le contenu de l'adresse B dans l'accumulateur
ADD C ; ajoute le contenu de l'adresse C à celui de l'accumulateur,
stocke le résultat dans l'accumulateur
STORE A ; stocke la valeur de l'accumulateur à l'adresse A
Sur les processeurs disposant d'un accumulateur, tous les résultats d'une instruction manipulant des registres vont être écrits dans cet accumulateur. De la même manière, toute instruction va aller manipuler le contenu de cet accumulateur.
Bien évidemment, les instructions qui manipulent plusieurs opérandes vont pouvoir aller chercher ceux-ci dans la mémoire ou dans d'autres registres. Historiquement, les premières machines à accumulateur ne contenaient pas d'autres registres pour stocker les opérandes des instructions arithmétiques et logiques. De ce fait, le seul registre pouvant stocker des données était l'accumulateur.
Par la suite, certaines architectures à accumulateur incorporèrent des registres supplémentaires pour stocker des opérandes. Cela permettait de diminuer le nombre d'accès mémoire lors de la lecture des opérandes. Mais attention : ces registres ne peuvent servir que d’opérande dans une instruction, et le résultat d'une instruction ira obligatoirement dans l'accumulateur.
Les avantages et désavantages de ces machines à accumulateurs sont les mêmes que pour les machines à pile. Leur code density est faible. Toutefois, elle n'est pas aussi bonne que pour les machines à pile. L'opérande stocké dans l'accumulateur n'a pas besoin d'être précisé, l'accumulateur étant utilisé implicitement par ces instructions. Mais si une instruction utilise plus d'un opérande, pour les opérandes restants, chaque instruction arithmétique ou logique va devoir préciser la localisation en mémoire de celui-ci — qu'il s'agisse d'une adresse mémoire ou d'un registre. Les instructions arithmétiques et logiques sont donc plus longues, ce qui diminue la code density.
Réutiliser des résultats plusieurs fois est aussi très compliqué, comme sur les machines à pile. Un résultat de calcul est automatiquement stocké dans l'accumulateur, donc le contenu de l'accumulateur est écrasé à chaque instruction arithmétique et logique et réutiliser des résultats est très difficile, sauf à passer par la mémoire.
En revanche, le nombre d'accès à la mémoire diminue avec l'utilisation de l'accumulateur. Celui-ci est placé dans le processeur, et tout accès à son contenu ne passe pas par la mémoire. Avec une machine à pile, tout opérande doit être chargé implicitement depuis la mémoire (même si certaines machines à piles ont eu la bonne idée de placer le sommet de la pile dans un registre caché au programmeur).
« une adresse, registre - mémoire »

Ici une instruction peut avoir comme opérande un ou plusieurs registres (typiquement un ou deux) et une adresse mémoire.
L'utilisation de registres est plus souple que l'utilisation d'une pile ou d'un accumulateur. Par exemple, une fois qu'une donnée est chargée dans un registre, on peut la réutiliser autant de fois qu'on veut tant qu'on ne l'a pas effacée. Avec une pile, cette donnée aurait été automatiquement effacée, dépilée, après utilisation.
De manière générale, le nombre total d'accès à la mémoire diminue fortement comparé aux machines à pile, grâce à une utilisation plus efficace des registres. Cela permet de gagner en performances car les registres sont souvent des mémoires bien plus rapides que la mémoire principale.
Chaque instruction manipulant des registres doit préciser quel registre lire ou écrire. Cette information est placée dans l'instruction et est codée sur quelques bits, réduisant ainsi la code density.
L'exemple A = B + C peut donc être traduit par la séquence :
LOAD R0, B ; copie le contenu de l'adresse B dans le registre R0 ADD R1, R0, C ; R1 = R0 + C STORE R1, A ; stocke la valeur de R1 à l'adresse A
« registre - registre »

Si les instructions ne peuvent avoir que des registres comme opérandes, il faut deux instructions, LOAD et STORE par exemple, pour respectivement charger un registre depuis un emplacement mémoire et stocker le contenu d'un registre à une adresse donnée.
Le nombre de registres est un facteur important.
Les processeurs RISC actuels sont tous de ce type.
Ce genre de machine a une code density légèrement moins bonne que les architectures registre-mémoire. En effet, certaines opérations qui auraient pris une seule instruction sur une machine registre-mémoire vont utiliser plusieurs instructions sur une machine registre-registre. Par exemple, la séquence A = B + C sera traduite en :
LOAD R0, B ; charge B dans le registre R0 LOAD R1, C ; charge C dans le registre R1 ADD R2, R0, R1 ; R2 ← R0 + R1 STORE R2, A ; stocke R2 à l'adresse A
Ce qui prend une instruction de plus.
En revanche, le nombre d'accès mémoire ou la réutilisation des registres ne change pas comparé aux machines registres-mémoire.
L'avantage des machines registres-registre est leur simplicité. Leurs instructions sont assez simples, ce qui fait que leur implémentation par le processeur est aisée. Cela vient du fait qu'un processeur est composé de circuits indépendants, chacun spécialisé dans certaines opérations : l'ALU est spécialisée dans les calculs, les registres dans le stockage des données, les circuits de communication avec la mémoire sont spécialisés dans les transferts de données, etc. Nos instructions sont exécutées en enchainant une série d'étapes élémentaires, chacune impliquant un ou plusieurs circuits du processeur. Avec des instructions complexes qu'on trouve dans les machines registre-mémoire, le processeur doit enchainer un grand nombre d'étapes, ce qui complexifie la conception du processeur : l'utilisation de micro-code devient la règle. Avec les machines registre-registre, les instructions sont souvent composées d'un faible nombre d'opérations élémentaire et leur enchainement par le processeur est simple à réaliser.
« mémoire - mémoire »

Tous les opérandes d'une instruction sont des adresses mémoire. Le processeur n'a pas de registres pour stocker des opérandes d'instructions. En conséquence, toutes les instructions vont devoir effectuer des accès à la mémoire.
C'est par exemple le cas pour le superordinateur vectoriel CDC Cyber 205. Cette machine était le concurrent du Cray-1 qui lui devait charger les vecteurs dans des registres préalablement à chaque calcul. Le VAX de DEC peut aussi être programmé de cette façon. Dans le même genre, presque toutes les architectures dataflow fonctionnent sur ce principe.
L'expression A = B + C :
ADD A, B, C ; Stocke a l'adresse A la somme B + C
De nos jours, vu que la mémoire est très lente comparé au processeur, ces architectures sont tombées en désuétude. Les architectures contenant des registres sont privilégiées, vu que ces dernières accèdent moins à la mémoire : elles sont capables de stocker des résultats intermédiaires de calcul dans les registres, diminuant ainsi le nombre d'accès mémoire.
Les instructions d'une architecture "mémoire - mémoire" sont souvent assez longues, car les adresses des opérandes sont encodées dans l'instruction. Cela réduit la code density.
Familles de processeurs
Une classification majeure distingue les processeurs CISC, RISC, VLIW, les processeurs vectoriels, architectures dataflow, DSP, etc. Cette classification se base sur des idiomes architecturaux communs entre processeurs d'une même catégorie.
On distingue généralement les jeux d'instructions complexes (CISC) et les jeux d'instructions réduits (RISC). Ces deux philosophies de conception cohabitent. La plupart des architectures actuelles sont de type RISC, mais l'architecture x86 d'Intel est de type CISC.
CISC
Les processeurs CISC embarquent un maximum d'instructions souvent très complexes mais prenant plusieurs cycles d'horloge. Leurs instructions gèrent aussi un grand nombre de modes d'adressage.
Le jeu d'instructions x86 (CISC) équipe tous les processeurs compatibles avec l'architecture Intel (qu'ils soient construits par Intel, AMD ou Cyrix). Il a reçu plusieurs extensions dont le passage à une architecture 64 bits, AMD64 (appelé plus génériquement x86-64).
Parmi les processeurs CISC notables, on peut citer, en plus du x86, Zilog Z80 et 6502, qui à eux seuls ont équipé la grande majorité des micro-ordinateurs 8 bits. La famille 680x0, qui a équipé différents micro-ordinateurs 16/32, puis 32 bits de la fin des années 80 aux années 1990, dont l'Amiga, l'Atari ST, l'Apple Macintosh ou le NeXTcube.
- VAX ;
Le M16C de Mitsubishi est un des rares microcontrôleurs à utiliser un jeu d'instructions CISC.
RISC
À l'opposé, les processeurs RISC ont un jeu d'instructions plus réduit mais chaque instruction est codée simplement et n'utilise que quelques cycles d'horloge. Toutes ses instructions sont de la classe « registre-registre ».
Il existe de nombreuses familles de processeurs RISC :
De nombreuses autres architectures existent, particulièrement pour des systèmes embarqués ou des microcontrôleurs.
Code density
De nombreux paramètres du jeu d'instructions ont tendance à affecter la taille que vont prendre nos programmes en mémoire. Par exemple, les CISC donnent souvent des programmes plus courts, en raison de la taille variable de leurs instructions. De même, la faible taille des instructions des machines à pile leur donne un avantage certain.