Complexité de Lempel-Ziv
La complexité de Lempel-Ziv est présentée pour la première fois dans l'article On the Complexity of Finite Sequences (IEEE Trans. On IT-22,1 1976), par deux informaticiens israéliens, Abraham Lempel et Jacob Ziv. Cette mesure de complexité est liée à la complexité de Kolmogorov, mais elle n'utilise comme seule fonction que la copie récursive.
Le mécanisme mis en œuvre dans cette mesure de complexité est à l'origine des algorithmes de compression de données sans perte LZ77, LZ78 et LZW. Bien que ne reposant que sur un principe élémentaire de recopie de mots, cette mesure de complexité n'est pas trop restrictive en ce sens qu'elle respecte les principales qualités attendues d'une telle mesure : elle n'octroie pas aux séquences avec certaines régularités une grande complexité et cette complexité est d'autant plus grande que la séquence est longue et peu régulière.
Principe
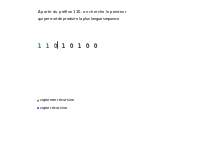
Étant donné une séquence S, de longueur n, dont la complexité peut être calculée, notée C(S), la séquence est parcourue en partant de la gauche. À imaginer qu'on ait une barre, servant de délimiteur, qu'elle va être déplacée tout au long de la séquence pendant le calcul. Au début, cette barre est placée juste après le premier caractère de la séquence. Cette position initiale de la barre sera appelée la position 1, puis chercher à la déplacer vers une position 2, qui à l'itération suivante sera considérée comme sa position initiale. On cherche à déplacer la barre (qui est à la position 1) le plus loin possible en faisant de telle sorte que le mot qui est entre la position 1 et la position courante soit un mot de la séquence qui débute avant la position 1 de la barre.
Dès que la barre se trouve à une position où cette condition (avoir entre la position 1 et la position courante un mot de la séquence déjà existant) n'est plus respectée on s'arrête, on positionne à cet endroit la barre en marquant cette position comme étant la nouvelle position initiale (position 1) de la barre et on réitère jusqu'à tomber sur la fin de la séquence. La complexité de Lempel-Ziv correspond au nombre d'itérations nécessaires pour arriver à la fin de la séquence en suivant ce procédé.
Explications formelles
La méthode proposée par Lempel et Ziv s'appuie sur plusieurs notions : reproductibilité, productibilité et histoire exhaustive d'une séquence.
Notations
Soit S une séquence de longueur n. On note S(i,j) avec le sous-mot de S allant de l'indice i à l'indice j (Si j<i, S(i,j) est la chaîne vide Λ). La longueur n de la séquence est notée l(S) et une séquence Q est un préfixe strict de S si :


Reproductibilité et productibilité

Une séquence S de longueur n est dite reproductible à partir de son préfixe S(1,j) (les j premiers caractères de S) si S(j+1,n) est un sous-mot de S(1,n-1). On note S(1,j)→S. Autrement dit, S est reproductible à partir de son préfixe S(1,j) si S(j+1,n) n'est rien d'autre qu'une copie d'un sous mot déjà existant (qui commence à un indice i < j+1) de S(1,n-1). Pour prouver qu'on peut reproduire toute la séquence S en partant de l'un de ses préfixes S(1,j), il faut montrer que :

La productibilité, quant à elle, se définit à partir de la reproductibilité : on dit qu'une séquence S est productible à partir de S(1,j) si S(1,n-1) est reproductible à partir de S(1,j). En d'autres termes, S(j+1,n-1) doit être une copie d'un sous mots de S(1,n-2). Le dernier caractère de S peut être un nouveau caractère (ou pas) entraînant éventuellement l'apparition d'un nouveau sous-mot de S (d'où le terme de productibilité).

Histoire exhaustive et complexité
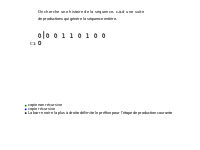
D'après la définition de la productibilité, on a Λ=S(1,0) ⇒ S(1,1). Par un processus récursif de production, où à l'étape i on a S(1,hi) ⇒ S(1,hi+1), on peut construire S à partir de ses préfixes.
Vu que S(1,i) ⇒ S(1,i+1) (en posant hi+1 =hi +1) est toujours vrai, ce processus de production de S se fait en au plus l(S) étapes. Soit m, , le nombre d'étapes nécessaires au processus de production de S.
On peut écrire S sous une forme décomposée, appelée une histoire de S et notée H(S), comme suit :




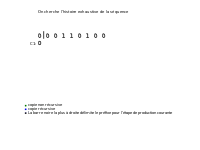
Une composante Hi(S) est dite exhaustive si S(1,hi) est la plus longue séquence produite par S(1,hi-1) (S(1,hi-1) ⇒ S(1,hi)) mais S(1,hi-1) ne reproduit pas S(1,hi) (notée ). L'indice p qui permet d'avoir la plus longue production est appelé pointeur. L'histoire de S est exhaustive si toutes ses composantes le sont, avec une éventuelle exception pour la dernière. Une séquence S n'a qu'une seule histoire exhaustive et cette histoire est, parmi les histoires de S, celle qui a le plus petit nombre de composantes. Le nombre de composantes de cette histoire exhaustive est une mesure de complexité de S.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Algorithme
Plus formellement on peut décrire la méthode par l'algorithme ci-dessous :
- i = p - 1
- l est la longueur du préfixe courant
- k est la longueur de la composante courante pour le pointeur p courant
- kmax est la longueur finale retenue pour la composante courante(maximum sur tous les pointeurs p possibles)
- C est la complexité
i := 0
C := 1
l := 1
k := 1
Kmax=k
tant que l+k <= n faire
si S[i+k] = S[l+k] alors
k := k+1
sinon
Kmax := max(k,Kmax)
i := i+1
si i = l alors // tous les pointeurs ont été traités)
C := C + 1
l := l + Kmax
k := 1
i := 0
kmax := k
sinon
k := 1
fin si
fin si
fin tant que
si k != 1 alors
C := C+1
fin si
Notes et références
Bibliographie
- (en) Abraham Lempel et Jacob Ziv, « On the Complexity of Finite Sequences », IEEE Trans. on Information Theory, , p. 75–81, vol. 22, n°1 [lecture en ligne]
Liens externes
- Exemple d'une implémentation naïve en Python, et discussions sur StackOverflow #41336798
- Implémentation en Python, Cython et Julia (sous licence MIT) sur GitHub disponible sur PyPi