Commande par retour d'état
En automatique, la commande par retour d'état est un moyen de modifier le comportement en boucle fermée d'un système dynamique donné par une représentation d'état. Cette approche suppose l'état connu. Quand ce n'est pas le cas, on peut utiliser un observateur d'état de manière à reconstruire l'état à partir des mesures disponibles.
Une finalité de la commande par retour d'état peut être de minimiser (ou maximiser) un indice de performance (Commande optimale, Commande LQ). Ce peut être aussi d'obtenir un système en boucle fermée dont les pôles, c'est-à-dire les valeurs propres de la matrice d'état, soient placés de manière appropriée. Ces pôles, en effet, déterminent le comportement du système, mais uniquement si celui-ci est monovariable : dans le cas multivariable, il est indispensable de considérer également les vecteurs propres[1]. Dans la plupart des cas, la commande doit réaliser d'autres fonctions essentielles pour tout asservissement, telles que suivi par la sortie d'un signal de référence, et rejet de perturbations. Il est alors nécessaire de faire en premier lieu les augmentations d'état nécessaires.
Historique
La notion de commande par retour d'état remonte aux travaux de Pontryagin (en Russie) et de Bellman (aux États-Unis) sur la commande optimale. La commande en temps minimal sous contraintes sur la commande, notamment (commande « Bang-Bang »), est une commande (non linéaire) à retour d'état. Les commandes linéaires à retour d'état, dont il est question dans cet article, sont apparues avec les travaux de Kalman, d'une part sur la théorie algébrique des systèmes d'état[2], d'autre part sur la commande « linéaire quadratique »[3]. Cet auteur a montré peu après que les commandes linéaires quadratiques jouissent de propriétés très utiles[4], qui ont pu ensuite être exprimées en termes de marge de gain et de marge de phase garanties, tout d'abord dans le cas monovariable[5], puis dans le cas multivariable[6] - [7]. Entre-temps se développaient des approches algébriques ayant pour finalité le placement de pôles[8]. Il a été montré par Wonham[9] qu'il existe une commande à retour d'état plaçant les pôles du système bouclé à des valeurs arbitraires du plan complexe (vérifiant toutefois une condition de symétrie par rapport à l'axe réel) si, et seulement si le système est commandable. Cette commande n'est unique que pour un système monovariable. Dans le cas multivariable, il existe une infinité de solutions qui peuvent avoir des propriétés de robustesse très différentes[1]. Davison[10], ainsi que Francis et Wonham[11], considérant qu'un asservissement n'a pas pour unique finalité la stabilisation ou l'augmentation de la rapidité d'un système, mais aussi et surtout le rôle d'assurer le rejet des perturbations et le suivi par la sortie d'un signal de référence en présence d'une erreur de modèle, ont proposé, de manière semble-t-il indépendante, et dans un formalisme différent mais au fond équivalent, de réaliser une augmentation d'état appelée « principe du modèle interne » (à ne pas confondre avec la commande à modèle interne (en)[12]). Dans le cas de perturbations et d'un signal de référence constants, ce Principe revient à rajouter une action intégrale à la commande[13]. Ce dernier type de commande linéaire (qui devient alors instationnaire) est très utilisé pour l'asservissement des systèmes non linéaires grâce à la technique des « gains préprogrammés »[14] - [15].
Commande à retour d'état « élémentaire »
La commande par retour d'état est une méthode employée en asservissement pour placer les pôles du système en boucle fermée dans le cas où toutes les variables d'état sont mesurées.
Formalisme
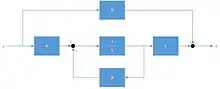
Soit le système d'état


: colonne qui représente les n variables d'état
: colonne qui représente les m commandes
: colonne qui représente les p sorties



: matrice d'état
: matrice de commande
: matrice d'observation
: matrice d'action directe.




Les pôles du système sont les racines de l'équation :

Puisque les systèmes sont à coefficients réels, l'ensemble est un ensemble symétrique du plan complexe, (symétrie étant par rapport à l'axe réel).

Une commande par retour d'état est de la forme

où est une variable auxiliaire, calculée à partir du signal de référence.

Les équations du système bouclé sont alors


Théorèmes fondamentaux
Les pôles du système bouclé sont les racines de . Les conditions suivantes sont équivalentes[16] :

(i) Pour tout ensemble symétrique de nombres complexes, il existe une commande à retour d'état pour laquelle les pôles du système bouclé sont les éléments de .


(ii) Le système est commandable.
De plus, la matrice de gain réalisant ce « placement de pôles » est unique si, et seulement si [1].


D'autre part, les conditions suivantes sont équivalentes[16] :
(iii) Il existe un ensemble symétrique de nombres complexes inclus dans le demi-plan gauche (ouvert) et une commande à retour d'état pour laquelle les pôles du système bouclé sont les éléments de .
(iv) Le système est stabilisable.
Exemple
On considère un système décrit de la façon suivante :


Ce système est commandable et a pour pôles et . On suppose que l'on souhaite que le système asservi ait ses pôles en et . Le polynôme caractéristique est alors





Déterminons maintenant de telle sorte que

- .

Sur cet exemple, mais aussi dans le cas général[1], on obtient un système linéaire dont les inconnues sont les coefficients de la matrice de gains . On a en effet
- .

et il reste à égaler ce polynôme avec . La résolution donne


et la commande à retour d'état s'écrit donc
- .

Il s'agit d'une commande de type proportionnel et dérivé (PD). Cet exemple montre donc que la commande à retour d'état « élémentaire », telle que celle qui a fait l'objet de cette section, souffre d'une grave lacune. On aurait en effet souhaité obtenir une commande de type PID. Nous verrons dans la section suivante comment pallier cette carence.
Remarque
Comme on l'a déjà mentionné, dans le cas des systèmes à plusieurs entrées le problème du placement de pôles n'admet pas une solution unique, et certaines de ces solutions peuvent être mauvaises, car non robustes, tandis que d'autres sont bonnes. Une possibilité est de déterminer une solution issue de la théorie de la commande linéaire quadratique[1].
Commande à retour d'état et bouclage intégral
Nous supposons maintenant que le système est régi par les équations

où et sont des perturbations constantes, inconnues. On désigne par un signal de référence constant, et le but de l'asservissement est de faire tendre vers l'erreur de consigne , malgré les perturbations, et même lorsque les coefficients des matrices et sont entachés d'une erreur à condition que celle-ci soit suffisamment petite.







Les conventions pour les dimensions sont les mêmes que précédemment. On supposera sans perte de généralité que les matrices et sont de rang et , respectivement.



Le système ci-dessus n'a pas une représentation d'état linéaire du fait des signaux et . Une manière de les éliminer consiste à dériver les deux équations, et à choisir comme nouvel état et comme nouvelle entrée[13] - [1].



On obtient alors en effet le système d'état


On montre alors facilement, grâce au test de Popov-Belevich-Hautus que
(1) est commandable (resp. stabilisable) si, et seulement si (i) est commandable (resp. stabilisable), (ii) et (iii) n'est pas un zéro invariant du système .





(2) est observable (resp. détectable) si, et seulement si est observable (resp. détectable).


L'interprétation de la condition (i) est évidente. La condition (ii) signifie que le nombre de degrés de liberté de la commande doit être suffisant pour réaliser les objectifs de l'asservissement. La condition (iii), enfin, signifie qu'on ne doit pas imposer à la sortie d'un système dérivateur de suivre un signal de référence.
Supposons commandable. On peut alors choisir un ensemble symétrique de valeurs propres dans le demi-plan gauche et déterminer une matrice de gains telle que le spectre de coïncide avec . La commande réalise alors le placement de pôles. D'après la définition de et de on a, en posant où et ont lignes et, respectivement, et colonnes:






![{\displaystyle K_{a}=\left[{\begin{array}{cc}K_{p}&K_{i}\end{array}}\right]}](https://img.franco.wiki/i/7d745f80bd83fc82906c545a6d5ca499f1dc5a62.svg)


- .

Puisque les matrices de gains et sont à coefficients constants, on obtient, à une constante additive près,
- .

Exemple
Reprenons l'exemple précédent. On a
- ,

- .

La commande qui place les pôles en est donnée par avec . On en déduit (à une constante additive près)



et on a donc un régulateur PID dont la fonction de transfert peut être mise sous la forme standard


avec et (en supposant que l'unité de temps choisie est la seconde) s et s. Les pôles de la boucle fermée n'ont pas été choisis au hasard: ceux du système en boucle ouverte sont 1, -5 et 0 (en prenant en compte le pôle de l'intégrateur: on considère ici toutes les valeurs propres de la matrice ). On a commencé par prendre le symétrique par rapport à l'axe imaginaire des « pôles instables » du système : ici le pôle valant 1. Puis on a décalé vers la gauche (à partie imaginaire constante) les pôles trop « lents » (ayant un module ou un coefficient d'amortissement trop petits): ici le pôle à l'origine. Cette méthode, qui a une justification théorique, permet d'assurer une bonne robustesse du système bouclé[1].




Commande à gains préprogrammés
Supposons maintenant que les matrices , et dépendent d'un paramètre , lui-même variable en fonction du temps (θ : t↦θ(t)). Dans ce cas, la matrice telle que définie ci-dessus dépend elle-même de , par conséquent la commande définie (à une constante additive près) par




ne s'exprime plus comme indiqué plus haut. Seule l'expression

(à une constante additive près) est correcte, et de nombreux exemples montrent l'avantage de cette formulation sur celle qui précède. Cette remarque, et sa généralisation au cas où un observateur est également utilisé pour reconstruire l'état, ont donné lieu à de nombreuses publications[14] - [15].
Notes et références
Notes
Références
- (en) Brian D. O. Anderson et John B. Moore, Linear Optimal Control, Prentice-Hall, , 413 p. (ISBN 0-13-536870-7)
- H. Bourlès, « Sur la robustesse des régulateurs linéaires quadratiques multivariables, optimaux pour une fonctionnelle de coût quadratique », C.R. Acad. Sc. Paris, i, vol. 252, , p. 971-974
- H. Bourlès et O. L. Mercier, « La régulation de poursuite optimale quadratique multivariable des systèmes linéaires perturbés », RAIRO Automatique, vol. 16, no 4, , p. 297-310
- (en) Henri Bourlès, Linear Systems, John Wiley & Sons, , 544 p. (ISBN 978-1-84821-162-9 et 1-84821-162-7)
- (en) E. J. Davison, « The Robust Control of a Servomechanism Problem for Linear Time-Invariant Multivariable Systems », IEEE Trans. on Automat. Control, vol. 21, no 1, , p. 25-34
- (en) B. A. Francis et W. M. Wonham, « The internal model principle for linear multivariable regulators », Appl. Maths & Optim., vol. 2, no 2, , p. 170-194
- (en) R. E. Kalman, « Contributions to the Theory of Optimal Control », Bol. Soc. Matem. Mex., , p. 102-119
- (en) R. E. Kalman, « When is a Linear Control System Optimal? », Trans. ASME, Ser.D: J. Basic Eng., vol. 86, , p. 1-10
- (en) R. E. Kalman, « Mathematical description of linear systems », SIAM J. Control, série A, vol. 1(2), , p. 152-192
- (en) C. E. Langenhop, « On the Stabilization of Linear Systems », Proc. Amer. Math. Soc., vol. 15, no 5, , p. 735-742
- (en) D. J. Leith et W. E. Leithead, « Survey on gain-scheduling analysis&design », Internat. J. Control, vol. 73, no 11, , p. 1001-1025
- (en) Manfred Morari et Evanghelos Zafiriou, Robust Process Control, Englewood Cliffs (N.J.), Prentice-Hall, , 488 p. (ISBN 0-13-782153-0, lire en ligne)
- (en) W. J. Rugh et J. S. Shamma, « Research on gain scheduling », Automatica, vol. 36, , p. 1401-1425
- (en) M. G. Safonov et M. Athans, « Gain and Phase Margin for Multiloop LQG Regulators », IEEE Trans. on Automat. Control, vol. 22, no 2, , p. 173-179
- (en) W. M. Wonham, « On Pole Assignment in Multi-Input Controllable Linear Systems », IEEE Trans. on Automat. Control, vol. 12, no 6, , p. 660-665
- (en) W. Murray Wonham, Linear multivariable control : a geometric approach, New York/Berlin/Paris etc., Springer, , 334 p. (ISBN 0-387-96071-6)
Voir aussi
Autres ouvrages sur le sujet
- Henri Bourlès et Hervé Guillard, Commande des systèmes. Performance et robustesse, Paris, Ellipses, , 305 p. (ISBN 978-2-7298-7535-0)
- (en) Eduardo Sontag, Mathematical Control Theory : Deterministic Finite Dimensional Systems, New York, Springer, , 2e éd., 532 p., relié (ISBN 978-0-387-98489-6, LCCN 98013182, lire en ligne)