Apache Druid
Druid est une base de données distribuée, orientée colonnes et open source, écrite en Java. Druid est conçu pour ingérer rapidement d’énormes quantités de données d’événement et renvoyer les données avec un faible temps de latence[2]. Le nom Druid fait référence aux druides de nombreux jeux de rôle, par analogie à l'aptitude de l'architecture du système à se métamorphoser pour résoudre différents types de problèmes de données.
Druid est couramment utilisé dans les applications d'informatique décisionnelle et de traitement analytique en ligne pour analyser de gros volumes de données historiques et en temps réel[3]. Druid est utilisé en production par les sociétés technologiques telles que Alibaba, Airbnb, Cisco[4], eBay[5], Netflix[6], PayPal, Yahoo[7] et Wikimedia Foundation[8].
Historique
Druid a été lancé en 2011 pour alimenter le produit d'analyse de la société Metamarkets. Le projet a été open source sous licence GPL en [9] - [10] et est passé à une licence Apache en [11] - [12].
Au fil du temps, un certain nombre d’organisations et de sociétés ont intégré Druid dans leur back office[3] et des committers de nombreuses organisations différentes ont été ajoutés[13].
En , la société commerciale Imply a été lancée pour fournir un produit d'entreprise construit autour de Druid[14].
En , Spicule Ltd a publié une version prise en charge de Druid sur la plate-forme Juju de Canonical[15].
Architecture
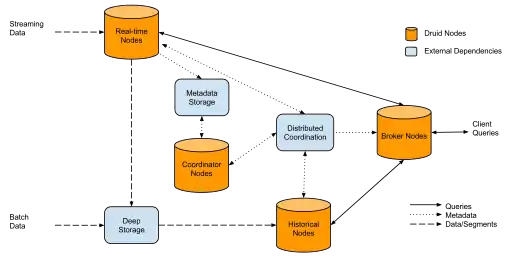
Entièrement déployé, Druid s'exécute en tant que cluster de processus spécialisés (appelés nœuds dans Druid) afin de prendre en charge une architecture tolérante aux pannes[16] les données sont stockées de manière redondante et en l'absence de point de défaillance unique[17]. Le cluster inclut des dépendances externes pour la coordination (Apache ZooKeeper), le stockage de métadonnées (par exemple MySQL, PostgreSQL ou Derby) et une installation de stockage profond (par exemple HDFS ou Amazon S3) pour la sauvegarde permanente des données.
Gestion des requêtes
Les requêtes du client sont d’abord envoyées aux nœuds broker, qui les transfèrent ensuite aux nœuds appropriés (historiques ou en temps réel). Comme les segments Druid peuvent être partitionnés, une requête entrante peut nécessiter des données provenant de plusieurs segments et partitions stockés sur différents nœuds du cluster. Les brokers peuvent savoir quels nœuds ont les données requises et fusionner ensuite des résultats partiels avant de renvoyer le résultat agrégé.
Gestion de cluster
Les opérations relatives à la gestion des données dans les nœuds historiques sont supervisées par des nœuds de coordination. Apache ZooKeeper est utilisé pour enregistrer tous les nœuds, gérer certains aspects des communications entre nœuds et organiser des élections d'un leader.
Caractéristiques
- Ingestion de données à faible latence (streaming)
- Exploration de données arbitraire sur les tranches
- Requêtes analytiques en moins d'une seconde
- Calculs approximatifs et exacts
Articles connexes
Références
- « Release 26.0.0 », (consulté le )
- (en) Nicole Hemsoth, « Druid Summons Strength in Real-Time » [« Druid appelle la force en temps-réel »], sur Datanami, (consulté le ).
- (en) druid, « Druid | Powered by Druid », druid.io (consulté le ).
- (en) Butler, « Under the hood of Cisco’s Tetration Analytics platform » (consulté le ).
- (en) « Druid at Pulsar - ebay的专栏 - 博客频道 - CSDN.NET », blog.csdn.net (consulté le ).
- (en) « The Netflix Tech Blog: Announcing Suro: Backbone of Netflix's Data Pipeline », techblog.netflix.com (consulté le ).
- (en) « Complementing Hadoop at Yahoo: Interactive Analytics with Druid » (consulté le ).
- (en) Andrew Otto et Fangjin Yang, « Analytics at Wikipedia: Big data conference: Strata Data Conference, September 25 - 28, 2017, New York, NY » (consulté le ).
- Tschetter, Eric. "Présentation du druide" , Druid.io , 24 octobre 2012.
- Higginbotham, Stacey. "Metamarkets open sources Druid, sa base de données en mémoire" , GigaOM , 24 octobre 2012.
- Harris, « The Druid real-time database moves to an Apache license », (consulté le ).
- « Druid Gets Open Source-ier Under the Apache License » (consulté le ).
- druid, « Druid | Druid Community », druid.io (consulté le ).
- Novet, Jordanie. "Imply lance 2 M $ pour commercialiser le magasin de données open source Druid" , VentureBeat , 19 octobre 2015.
- Downie, Stephen. "L'entreprise de données Spicule met la puissance du magasin d'analyse utilisé par Netflix entre les mains des clients" , EIN Presswire , 7 novembre 2018.
- Documentation du projet druide.
- Yang, Fangjin; Tschetter, Eric; Léauté, Xavier; Ray, Nelson; Merlino, Gian; Ganguli, Deep. "Druide: un magasin de données analytiques en temps réel" , Metamarkets , extrait le 6 février 2014.