Algorithme d'Aho-Corasick
L'algorithme d'Aho-Corasick est un algorithme de recherche de chaîne de caractères (ou motif) dans un texte dû à Alfred Aho et Margaret Corasick et publié en 1975. L'algorithme consiste à avancer dans une structure de données abstraite appelée dictionnaire qui contient le ou les mots recherchés en lisant les lettres du texte T une par une. La structure de données est implantée de manière efficace, ce qui garantit que chaque lettre du texte n'est lue qu'une seule fois. Généralement le dictionnaire est implanté à l'aide d'une trie ou arbre préfixe auquel on rajoute des liens suffixes. Une fois le dictionnaire implanté, l'algorithme a une complexité linéaire en la taille du texte T et des chaînes recherchées.
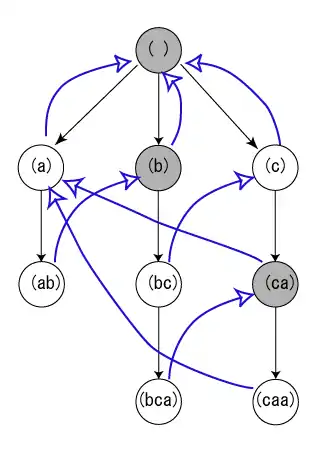
L'algorithme extrait toutes les occurrences des motifs. Il est donc possible que le nombre d'occurrences soit quadratique, comme pour un dictionnaire a, aa, aaa, aaaa et un texte aaaa. Le motif a apparaît à quatre reprises, le motif aa à trois reprises, etc.
Description
De manière informelle, l'algorithme génère un arbre préfixe (une trie) avec des liens entre les nœuds. Chaque nœud représentant une chaîne (par exemple abc) a un lien vers le nœud qui correspond au plus long suffixe disponible (dans le cas d'abc, il s'agit de bc s'il existe, autrement c ou encore la racine). De plus l'arbre préfixe maintient des liens entre un nœud donné et le nœud représentant le suffixe le plus long qui apparaît dans le dictionnaire. Les correspondances peuvent ainsi être énumérées en parcourant la liste chaînée. L'algorithme utilise ensuite l'arbre pendant l'exécution, se déplaçant progressivement dans le texte en entrée et en conservant la correspondance la plus longue. L'utilisation de l'arbre préfixe garantit une complexité linéaire. Pour chaque nœud présent dans le dictionnaire et tout lien dans la liste chaînée des suffixes du dictionnaire, une sortie est générée.
Applications et historique
Quand les mots recherchés sont connus à l'avance (par exemple pour une base de données des signatures de virus informatiques ou la recherche d'une séquence particulière dans un génome), alors la construction de l'automate peut être exécutée au préalable et le résultat stocké pour une utilisation ultérieure. Dans ce cas, la complexité est linéaire en fonction de la longueur de l'entrée plus le nombre de correspondances trouvées.
L'algorithme d'Aho-Corasick fut initialement utilisé dans l'utilitaire grep disponible sous Unix.
Voir aussi
Source
- Alfred V. Aho et Margaret J. Corasick, , Efficient string matching: An aid to bibliographic search, Communications of the ACM, vol. 18, issue 6, pages 333–340, DOI 10.1145/360825.360855.
Liens externes
- Algorithmes Aho-Corasick en langage C by Spawnrider
- Aho-Corasick entry in NIST's Dictionary of Algorithms and Data Structures
- (en) Alfred V. Aho et Margaret J. Corasick, « Efficient string matching: an aid to bibliographic search », Communications of the ACM, New York, ACM, vol. 18, no 6, , p. 333-340 (ISSN 0001-0782 et 1557-7317, OCLC 1514517, DOI 10.1145/360825.360855)