ASCII étendu
Les codages de caractères ASCII étendu, aussi connus dans leur dénomination anglaise extended ASCII, sont un ensemble de jeux de codage de caractères qui ont en commun le sous-ensemble de caractères ASCII. Ce terme est informel et peut être critiqué pour deux raisons : d'une part cette dénomination pourrait laisser penser que le standard ASCII aurait été étendu, alors qu'il désigne en fait un ensemble de normes qui incluent le sous-ensemble ASCII ; d'autre part, l'ASCII étendu ne désigne pas un codage de caractère donné mais un ensemble imprécis de normes précisant chacune un codage de caractères surensemble de l'ASCII.
La notion d'extended ASCII est d'un usage commun dans la documentation technique. Elle est reprise par le MSDN de Microsoft [1]. Elle est reprise par de nombreuses pages de manuel Unix comme celles de MacOS X [2].
L'Encyclopédie Britannica associe ce concept à l'année 1981, à IBM et au codage 8 bits[3].
Variations et extensions
Vu l'existence de milliers de standards et variantes informatiques de codage des caractères, il est difficile de se faire une idée des liens de parenté entre chacun d'entre eux. Le tableau suivant donne une illustration du positionnement de l'ASCII, de ses extensions et de ses variantes, par rapport à quelques familles de standards informatiques, dans un contexte temporel.
| Télégraphie | Téléphonie | Informatique | Avion | ||||
|---|---|---|---|---|---|---|---|
| Code Baudot | |||||||
| ↓ | |||||||
| A.I. 2 | |||||||
| Diverses variations des codages EBCDIC et autres codages | |||||||
| ↓ | |||||||
| ISO/CEI 646 - IRV (variante internationale) | Arinc | ||||||
| ↓ | ↓ | ||||||
| ISO/CEI 646 - US (États-Unis) | |||||||
| ISO/CEI 646 : Autres nations | |||||||
| ↓ | |||||||
| ISO/CEI 646 : Autres nations | |||||||
| ↓ | ↓ | ↓ | ↓ | ↓ | |||
| ASCII | Page de code DOS (437, 850…) | Séries ISO 8859 (exemple ISO/CEI 8859-1, ISO/CEI 8859-15) | ISO/CEI 2022 (illimité à 256 caractères) | ||||
| ↓ | |||||||
| Codage windows (Windows-1252, etc) ou Ansinew | |||||||
| ↓ | |||||||
| ISO 10646 / Unicode | |||||||
| ↓ | |||||||
| AI no 5 | GSM 03.38 (en) (SMS) | ||||||
| Légende | |
| ASCII | Un des standards assimilable à l'ASCII |
| Extensions de l'ASCII | Complète l'ASCII |
| Variante de l'ASCII | Différents de l'ASCII pour quelques caractères |
| Précurseur de l'ASCII | Un sous-ensemble |
| Sans lien avec l'ASCII | Sans lien avec l'ASCII |
Histoire
Le besoin d'uniformiser les codages des caractères tout en préservant des spécificités locales a été ressenti dès avant les années 1960, avec l'apparition des normes ISO/CEI 646 et de ses différentes déclinaisons locales dont l'ASCII. Si, à l'origine, l'ASCII a été pensé comme un codage de caractères pour les États-Unis, l'influence de l'industrie informatique a conduit à délaisser les différentes variantes de l'ISO-646 pour imposer l'ASCII. Le choix de codage d'un octet par caractère a dans un premier temps permis de représenter les caractères absents de l'ASCII. Il ne posait pas de problème à l'époque, dans la mesure où les ordinateurs n'étaient pas connectés en réseau.
Diverses extensions propriétaires sont apparues sur les PC non-EBCDIC, en particulier dans les universités. Atari et Commodore ont ajouté de nombreux symboles graphiques non-ASCII (Respectivement, ATASCII et PETSCII, basé sur la norme ASCII originale de 1963).
L’IBM PC a introduit une extension de l’ASCII sur huit bits, qu’IBM a ensuite décliné en de multiples variantes pour des langues et des cultures différentes. IBM a appelé ces jeux de caractères des pages de code, et leur a attribué des numéros qui restent encore employés de nos jours. Dans une page de code compatible avec ASCII, les 128 premiers codes (valeurs 0 à 127) représentent les mêmes caractères que l’ASCII, tandis que les 128 codes suivants (valeurs 128 à 255) fournissent un ensemble de caractères spécifique.
- Dans l’IBM PC originel, et les PC ultérieurs fonctionnant sous DOS vendus en Amérique du Nord, la page de code 437 était utilisée. Elle incluait quelques-uns des caractères accentués nécessaires pour le français, l'allemand et d’autres langues européennes, ainsi que certains caractères graphiques de dessin.
- En Europe de l’Ouest, c’est la page de code 850 qui était distribuée ; elle offrait un support plus complet des langues latines.
Ces jeux de caractères ont permis de rédiger des documents dans des combinaisons de langues telles qu’anglais et français (avec la page de code 850), mais pas, par exemple, français et grec (qui exigeait la page de code 737 incompatible avec celle nécessaire pour le français).
Apple Computer a introduit ses propres codes huit bits ASCII étendus dans Mac OS, comme MacRoman.
Digital Equipment Corporation a développé le Multinational Character Set, basé sur des versions préliminaires de ISO/CEI 8859. Il a été soutenu par le VT220.
Fonctionnement et théorie
L'utilisation de codages de caractères de type ASCII étendu repose d'une part sur la reconnaissance de syntaxe basée sur l'ASCII, et d'autre part sur un traitement souvent indifférencié des 128 valeurs restantes.
Cet aspect a été important pour les langages de programmations comme le langage C ou d'autres langages comme le HTML. Il a permis d'utiliser ces mêmes langages informatiques dans différents pays, grâce à l'ASCII, tout en permettant l'introduction de chaînes de caractères et de commentaires dans la langue appropriée (locale, régionale ou nationale).
Apports et limitations
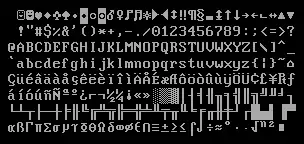
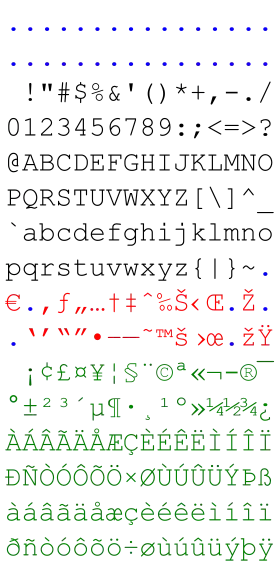
L'ASCII étendu a permis à moindre coût de déployer mondialement des logiciels représentant le texte en peu d'octets et d'ignorer tout ou partie des problématiques d'internationalisation. Il a également conduit a des problèmes d'interopérabilité, qui ont abouti à l'émergence de standards tels qu'Unicode.
Apports
Les codages de caractères étendant l'ASCII additionnent à l'ASCII les caractères manquants à une langue, une culture ou un pays.
La préservation de l'ASCII permet la préservation des caractères de contrôle, des nombres et des labels en caractères non accentués. Elle permet également la préservation de symboles spécifiques à l'ASCII mais très utilisés en informatique, notamment dans les langages de programmation, comme les parenthèses, les chevrons, les accolades ou les crochets. Avant l'émergence de ce concept, le langage C avait dû avoir recours au concept de digrammes et de trigrammes pour pallier l'absence de ces caractères. Depuis l'utilisation de l'ASCII étendu, l'usage des digrammes et des trigrammes dans le langage C est tombé en désuétude.
L'existence de 128 valeurs disponibles permet d'ajouter par exemple, selon le cas, des symboles graphiques informatiques, des symboles mathématiques (lettres grecques), des alphabets ou compléments d'alphabets locaux, des symboles littéraires ou de ponctuation, des symboles commerciaux.
Les codages de caractères ISO-8859 apportent également une deuxième plage de caractères de contrôle dite C1, entre les valeurs 128 et 159.
Un logiciel, un protocole, un fichier de configuration, un fichier de code source ou tout autre service peut donc, dans une certaine mesure, être interopérable avec un ensemble de codage de caractères étendant l'ASCII, sans connaître précisément les différentes extensions existantes.
Limitations

Les différentes techniques d'extension de l'ASCII posent différentes problématiques :
S'il peut être facile de savoir que le codage est en partie ASCII, l'autre partie du codage est parfois, voire souvent, incertaine.
Les extensions de l'ASCII peuvent reposer sur des techniques variées. Certaines techniques garantissent que chaque octet représente un caractère, alors que d'autres utilisent plusieurs octets pour représenter un caractère. Certaines extensions introduisent des octets nuls (UTF-16) alors que d'autres réservent l'usage de cette valeur particulière. Certaines extensions garantissent qu'un octet a toujours la même signification, alors que dans d'autres (ISO/CEI 2022), le caractère représenté par un octet dépend du contexte. Certaines extensions permettent des séquences d'échappement dans lesquels les valeurs de caractères ASCII ne sont pas des caractères ASCII. Certaines extensions apportent des caractères de contrôle ou des caractères d'espacement qui ne sont pas reconnus par tous les logiciels.
Cette diversité est généralement difficile ou impossible à gérer entièrement et peut conduire à des problématiques d'interopérabilité comme à des mojibake ou autres affichages malencontreux.
Standardisation et normalisation
Il n'existe pas de standardisation spécifique de la notion d’« ASCII étendu ». Elle est donc sujette a interprétation. Ainsi certains considèrent que la présence d'un indicateur d'ordre des octets suffit à dire que l'UTF-8 n'est pas de l’ASCII étendu ; la même question peut se poser pour des codages de caractères tels shift-JIS, ou ceux incluant des séquences d'échappement. Certains considèrent que l'UTF-16 est une forme d'extension de l'ASCII.
Usages et applications
Dans de nombreux protocoles (notamment le courrier électronique et le HTTP), le codage de caractères du contenu doit être étiqueté avec des attributs IANA des identificateurs de jeu de caractères.
Aspects économiques et sociaux
Parce que ces extensions ASCII sont autant de variantes, il est nécessaire d'identifier quel jeu est utilisé pour un texte particulier pour qu'il puisse être interprété correctement. Cependant, parce que les caractères les plus utilisés (ceux en ASCII, les points de code sept bits) sont communs à tous les jeux, il est extrêmement difficile d'identifier correctement un jeu de caractères. Si cela est sans incidence pour un fichier en langue anglaise, cela a des conséquences fâcheuses pour les utilisateurs d'autres langues.
Par ailleurs, sur Internet, parce que les logiciels de nombreux internautes utilisent la norme ISO 8859-1, et parce que Microsoft Windows (en utilisant la page de code 1252, sur-ensemble de la norme ISO 8859-1) était il y a encore peu de temps le système d'exploitation en position dominante pour les ordinateurs personnels (ce n'est plus le cas avec l'accélération de l'usage des tablettes et smartphones fonctionnant majoritairement sur d'autres systèmes d'exploitation), l'utilisation inopinée/impromptue de la norme ISO 8859-1 a été tout à fait banalisée, et souvent présumée.

Ce n'est plus le cas depuis mi-2008 où l'Unicode (plus précisément un de ses codages standardisés, UTF-8) a dépassé en usage tous les autres jeux de caractères codés sur l'Internet. Si on y ajoute l'ASCII sur 7 bits (en version américaine entièrement compatible avec UTF-8), Unicode représente depuis 2008 les deux tiers des volumes de texte codés disponibles sur Internet. C'est d'autant plus remarquable que l'UTF-8 n'a été réellement standardisé que deux ans avant et son usage était encore peu significatif au début de l'année 2007 (où les codages alors en compétition étaient les codages « ASCII étendus », avec majoritairement ISO 8859-1 ou son extension par la page de code 1252 de Windows, suivis des autres jeux de la série ISO 8859). En outre, les comités de normalisation internationaux ont totalement arrêté depuis des années leurs travaux concernant la normalisation des jeux de caractères autres que ceux basés sur l'ISO/IEC 10646 (et Unicode pour les algorithmes liés). Tous les nouveaux protocoles de communication de l'Internet ont l'obligation de prendre en charge uniquement l'UTF-8 comme codage par défaut (même s'ils ont des options activables pour en supporter d'autres) et de nombreux anciens protocoles encore utilisés ont été étendus avec une spécification leur permettant d'utiliser le codage UTF-8.
Depuis 2008, l'adoption d'UTF-8 s'est considérablement accélérée, tant en pourcentage des volumes de données échangées (ou accessibles par des interfaces de programmation et d’interrogation telles que les API web) qu'en volume total de nouvelles données produites. Parallèlement, les anciens codages étendus de l'ASCII ont vu leur utilisation diminuer rapidement (pour les échanges de données sur les réseaux publics de communications, mais aussi par « contagion » sur les systèmes privés internes), et pour certains (notamment les variantes nationales de l'ISO/IEC 646, dont la variante française qui a été déclassée par l'AFNOR en tant que norme française) tomber déjà en désuétude (ne subsistant plus que pour des usages strictement internes liés à l'exploitation de données historiques archivées, mais non converties pour des raisons de coût ou de planification). Il en résulte que l'UTF-8 est le seul codage de caractères « ASCII étendu » qui subsiste (en plus de l'ASCII de base) pour tous les nouveaux développements destinés à une utilisation partagée ou aux échanges sur les réseaux de communication.
Même en Chine, où la prise en charge de la norme nationale de codage GB18030 (elle aussi une extension de l'ASCII) a été rendue obligatoire, UTF-8 a dépassé en usage cette norme nationale, depuis que la conversion entre GB18030 et UTF-8 a été figée (ce qui permet aux systèmes de traiter n'importe quelle donnée de l'Internet et d'interagir sans perte avec les systèmes chinois qui exigent uniquement GB18030).
Pourtant, alors même que le support de l'UTF-8 a été intégré dans de nouveaux logiciels ou leurs mises à jour récentes, ce n'est pas toujours le codage par défaut lors de leur installation (cas de certains éditeurs de texte), alors qu'il pourrait l'être sans que l'utilisateur final ait besoin de chercher et changer cette option (l'utilisateur devrait même pouvoir choisir de ne pas installer la prise en charge optionnelle de nombreux autres jeux de caractères codés).
En pratique, tous les systèmes de développement actuels prennent en charge l'UTF-8 (entre autres codages), soit nativement, soit à l'aide de bibliothèques standardisées. Seuls certains anciens équipements (tels que des afficheurs simplifiés sur des appareils électroniques grand public) peuvent localement ne pas prendre en charge autre chose qu'un jeu limité de caractères (souvent alors uniquement l'ASCII de base sans aucune extension, ou seulement une partie telle que les 10 chiffres, les 26 lettres latines capitales, l'espace et quelques signes de ponctuation).
Articles connexes
Bibliographie
De nombreux livres apparaissent dans Google Books lors de la recherche de "Extended ASCII". Ces livres utilisent la dénomination Extended ASCII, sans nécessairement la définir.
À titre d'exemple :
- Advanced Rails - Page 238
- Mastering Microsoft Windows Vista Home: Premium and Basic - Page 219
- High Definition: An A to Z Guide to Personal Technology - Page 119
- Digital Typography Using LaTeX - Page 14
- New Perspectives on Microsoft Office 2007 - Page 13
- New Perspectives on Computer Concepts - Page 24
- Dictionary of Information Technology - Page 212
Notes et références
- (en) « Visual Studio 2005 Retired documentation », sur Microsoft Download Center (consulté le ).
- http://www.manpages.info/macosx/file.1.html
- (en) « Extended ASCII / computer science », sur Encyclopedia Britannica (consulté le ).
- Mark Davis, « Unicode nearing 50% of the web », Official Google Blog, Google, (consulté le )