Élasticité (cloud computing)
L'élasticité dans le cloud computing est la capacité de ce cloud à s'adapter aux besoins applicatifs le plus rapidement possible. Il existe plusieurs définitions selon les auteurs, certains considérant les notions de Scalability et d'élasticité comme identiques, d'autres comme étant distinctes. L'arrivée de tels systèmes distribués (voir Calcul distribué) entraîne forcément des problèmes techniques qu'il faut régler ou limiter. Au niveau économique, l'arrivée de l'élasticité a eu des impacts chez les clients et les fournisseurs de cloud. Les fournisseurs ont par exemple créé un système de paiement « pay-as-you-go » permettant de payer les ressources utilisées à la demande. Ainsi, un client peut louer un serveur sur une courte période et à la taille voulue.
De nombreux fournisseurs tels que Amazon Web Services, Microsoft Azure ou encore Google App Engine ont créé des serveurs de cloud à la demande. Mais chaque fournisseur de cloud a ses spécificités en termes de vitesse, d'élasticité, de latence, etc.
Définitions
Notions
Il est commun de considérer l'élasticité et la scalabilité comme étant des synonymes[1] - [2]. L'élasticité dans le cloud peut être comparée à la propriété physique de l'élasticité d'un matériel, qui correspond à sa capacité à revenir à sa forme originale après une déformation qu'il a subi. Ainsi l'élasticité peut être calculée comme le rapport entre la pression que le cloud peut subir sur la pression qu'elle subit[3].
Pour autant, d'autres comme N. R. Herbst et Doaa M. Shawky en font deux définitions bien distinctes :
- Scalabilité
- La scalabilité est la capacité d'un système à subvenir aux besoins en ressources, sans prendre en compte la rapidité, le temps, la fréquence, ni la granularité de ses actions[4].
- Élasticité
- L'élasticité est le degré auquel un système est capable de s'adapter aux demandes en approvisionnant et désapprovisionnant des ressources de manière automatique, de telle façon à ce que les ressources fournies soient conformes à la demande du système[5].
La scalabilité est donc un prérequis à l'élasticité[4]. Le temps est un lien important entre l'élasticité et la scalabilité : moins le système prend de temps à se s'adapter, plus il est élastique[6].
Tout l’intérêt de l'élasticité dans le cloud est d'ailleurs de répondre le plus précisément possible à la demande en ressources d'une application[4]. Pour cela, les systèmes sont capables de s'adapter en quelques minutes[7].
Ressources
Deux approches de l'élasticité existent. La première est dite élasticité horizontale. Cette forme d'élasticité s'effectue en ajoutant ou supprimant des machines virtuelles à l'instance du client[8] - [9] - [10]. La deuxième approche, dite verticale, s'effectue non plus en ajoutant des serveurs, mais en ajoutant des ressources à la machine, tel que de la RAM, du CPU, etc.[8] - [9] - [10].
En règle générale, l'élasticité horizontale a un coût en temps plus important que l'élasticité verticale du fait qu'il faille attendre que la machine virtuelle soit créée et bootée[11]. Ainsi pour de meilleures performances, on utilisera l'élasticité verticale. Le problème est que ce type d'approche est bien plus limité que la scalabilité horizontale. En effet, la scalabilité verticale ne peut pas s'étendre sur des ressources en dehors de la machine physique[9]. Ainsi, il convient de bien définir sur quelle machine la machine virtuelle va être démarrée au début, afin de pouvoir scaler de façon verticale le plus longtemps possible.
Dans son article, Chien-Yu Liu [12] définit un algorithme qui, selon lui, est le plus efficace, alliant la scalabilité quasi infinie de l'élasticité horizontale, et la rapidité de l'élasticité verticale[13]: Pour augmenter les ressources de machine virtuelle, quand la machine virtuelle ne suffit plus, il faut en créer de nouvelles sur le même cloud (élasticité horizontale). Si un seul cloud ne peut satisfaire les demandes en ressources, il faut ajouter des machines virtuelles venant d'autres clouds (élasticité horizontale). Quand le cloud ne satisfait plus les demandes, il faut passer à l'application suivante.
Métriques

N. R. Herbst, dans son article[14], nous présente une façon de calculer l'élasticité descendante et ascendante, mais aussi la précision d'un système de cloud en sur-approvisionnement et en sous-approvisionnement[15]. Ainsi, l'élasticité ascendante (respectivement descendante) est inversement proportionnelle au temps moyen passé par un système en sous-approvisionnement (respectivement sur-approvisionnement) à un état optimal (respectivement ) par la moyenne de la quantité accumulée des ressources sous-approvisionnées (respectivement sur-approvisionnement) sur la période de test (respectivement )[15]:






La Précision ascendante (respectivement descendante) est le rapport entre la quantité accumulée des ressources sous-approvisionnées (respectivement sur-approvisionnement) (respectivement ) et la période de test [15]:





Problèmes et limites
Problèmes
La flexibilité des systèmes de cloud fait naître quelques défis chez les fournisseurs[16]. Le premier est qu'il existe plusieurs configurations de base, il est généralement assez difficile de savoir laquelle choisir[17]. Le but étant d'avoir la meilleure configuration tout en étant la moins chère[17]. Une fois cette étape franchie, l'application va avoir des demandes plus ou moins importantes sur le temps. Comment, et quand approvisionner/désapprovisionner le système[18] ? Dans cette étape, l'objectif est de minimiser les coûts en infrastructure (euros) et en transition (temps)[18].
L'un des plus grands défis dans le cloud est de résoudre les erreurs dans les très grands systèmes distribués[18]. Étant des problèmes liés aux très grands systèmes, il est impossible de les résoudre sur de plus petits, ainsi, les tests sont faits directement sur les environnements de production[18]. Le fait d'utiliser des machines virtuelles peut être une solution[18]. En effet, il est possible de capturer des informations précieuses sur une VM, là où c'est impossible sur des machines physiques[18]. Malheureusement, tous les fournisseurs ont développé leur offre sans utiliser de VM, soit parce qu'ils ont débuté avant l'ère de la virtualisation, soit parce qu'ils pensaient qu'ils ne pouvaient pas se l'offrir[18].
Un autre défi est de gérer la flexibilité du stockage[19]. De nombreuses tentatives ont été faites pour répondre à cette question, variant dans la richesse des requêtes et des API de stockage, les garanties de performance offertes[19]. L'idée, étant de non seulement répondre aux attentes des programmeurs en ce qui concerne la durabilité, la haute disponibilité et la capacité de gérer et d'interroger des données, tout en gardant les avantages de la flexibilité du cloud[19].
Il existe aussi des défis qui relient élasticité et écologie des clouds. En effet, il est important que les applications hébergées sur le cloud libèrent le plus possible les ressources non utilisées[19]. Premièrement, car un ordinateur en veille ne consomme "que" deux-tiers de ses ressources, ce qui fait un grand gain d'énergie[19], et ensuite car cela implique un impact plus positif sur l'environnement, alors que la filière est très mal vue par l'opinion publique[19]. Pour cela, les fournisseurs ont créé le système de facturation à grain fin (pay-as-you-go) afin d'inciter les utilisateurs à libérer les ressources dès que possibles[19].
Les licences de logiciel posent également problème. En effet, certains fournisseurs de logiciels n'ont pas encore d'offres pour le cloud, ce qui implique des coûts de licences logiciels astronomiques[19]. Pour répondre à ce problème, l'open source est une solution très populaire[19]. Heureusement, certains fournisseurs tels qu'Amazon ou Microsoft commencent à faire des offres de licence logiciel « pay-as-you-go »[19]. Bien que les instances tournent sur une structure logiciel payante, cela reste une alternative très intéressante face aux solutions open source (respectivement 0,15 $/h contre 0,10 $/h)[19].
L'élasticité permettant d'acquérir dynamiquement ou de libérer des ressources informatiques en réponse à la demande, il est important d'avoir une surveillance ainsi qu'un contrôle de celle-ci. Les données à superviser sont classées en trois dimensions : le coût, la qualité et les ressources. Des framework comme MELA[20] permettent de surveiller et d'analyser l'élasticité des services cloud. Pour le contrôle de celle-ci, des outils comme SYSBL (Simple Yet Beautiful Language) [21], permettent d'avoir un contrôle sur trois niveaux : au niveau de l'application, au niveau du composant et au niveau de la programmation, et aussi de répondre aux exigences de l'élasticité.
Un autre problème à prendre en compte est le temps de démarrage des machines virtuelles. En effet elles doivent être disponible dans le temps et prêtes à l'emploi pour les utilisateurs[22]. Ce temps de démarrage peut prendre en compte différents facteurs[22]: le temps de la journée, la taille de l'image de OS, le type d'instance, l'emplacement des datacenters et le nombre d'instances demandées en même temps.
Limites
Chaque système a ses limites. Dans le cas du cloud, l'une des premières identifiables de son élasticité est le nombre de ressources disponibles[23], d'autres limites ont été trouvées.
D'après des tests effectués par Doaa M. Shawky, plus on alloue de machines à la fois, moins le système est élastique[24]. En effet, lors d'une expérience, il compare deux systèmes avec les mêmes valeurs de stress, l'un incrémentant le nombre de machines par paquets de 10, le second par lots de 20[6]. Il s'est avéré que le temps moyen d'extension des deux expériences est de 4427.2 secondes et 6334.4 secondes respectivement[6]. Dans le même temps, l'élasticité moyenne était respectivement de 0.0036 et 0.0028[6]. Dans le cas où l'élasticité du système se fait de manière horizontale, l'élasticité est également diminuée au fur et à mesure que le nombre de machines allouées augmente[6]. Cela est dû au fait que le temps d'extension augmente[6]. Cette limite est d'autant plus vraie pour l'élasticité horizontale du fait qu'il faille attendre l'initialisation et le démarrage de chaque machines virtuelles à instancier.
Économie
Du fait de l'élasticité du cloud, les systèmes des fournisseurs ont un taux d'utilisation de leur systèmes compris entre 5 % et 20 %[3]. De ce fait, il y a toujours des ressources disponibles dans le cas où une forte demande en ressources viendrait à arriver de la part d'un à plusieurs clients.
Fournisseurs
Les fournisseurs se permettent de faire varier leurs prix grâce aux variations des coûts du cloud: ceux-ci comprennent l'approvisionnement et l'entretien du matériel tel que les processeurs, la mémoire, le disque dur, et le réseau. La taille de la mémoire, la taille de l'espace disque utilisé, et le coût de transmission de données sont aussi pris en compte lors de la location par le client[25].
Amazon EC2 propose deux modèles économiques à ses clients[25] :
- le premier, nommé "On-demand instances", est le modèle économique le plus commun, le « use-on-demand »[26]. En choisissant cette offre, les clients n'ont pas d'engagement, et sont libres de leur planification.
- le second est nommé spot instances. Cette option permet à Amazon de jouer sur les prix selon l'utilisation de leur cloud. Moins il sera utilisé, plus les prix seront bas, mais l'inverse est vrai aussi.
Grâce à l'offre spot instances, Amazon incite ses clients à utiliser leur cloud lors des périodes creuses, à terme la société veut aplanir la courbe d'utilisation de leur cloud, ce qui permettra de baisser les coûts de maintenance[27].
Clients

L'utilisation du cloud peut, de par son élasticité, avoir plusieurs avantages pour un client :
Par exemple, une start-up qui aurait besoin de faire de gros calculs paierait le même prix à utiliser 1000 machines Amazon EC2 pendant une heure que 1 machine pendant 1000h[26].
De même, dans le cas d'une utilisation qui varie beaucoup sur le temps, il est intéressant d'utiliser le cloud. Grâce à l'élasticité de l'offre « pay-as-you-go » que proposent beaucoup de fournisseurs, le client ne paye que ce qu'il utilise[28]. Par exemple, dans le cas d'un client qui utilise 500 serveurs en heure de pointe mais seulement 100 en période creuse avec une moyenne de 300 serveurs sur la journée. Sans le cloud, le client serait obligé d'avoir 500 serveurs, soit 500 x 24 = 12 000 serveurs-heure. Grâce au cloud et son élasticité, il n'utilise que 300 x 24 = 7 200 serveurs-heure[28].
Mais cette analyse ne prend pas en compte le fait que le cloud permet une adaptation rapide à une demande en ressource non habituelle, par exemple les sites de vente en ligne en décembre[28]. L'impact est ici très minime, alors que si le client hébergeait lui-même son site, la commande et l'installation de nouveaux serveurs aurait pu prendre plusieurs semaines, sans compter le fait qu'une fois les fêtes passées, ses serveurs n'auraient plus eu d'utilité[28].
Comparaison des fournisseurs
En 2010, une comparaison a été effectuée entre les fournisseurs de cloud public : Amazon AWS, Azure, AppEngine et CloudServers[29] Ces fournisseurs ont été évalués autour de 4 critères : l'élasticité des clusters, le stockage persistant, le réseau intra-cloud, et les réseaux vastes.
Pour des raisons légales, l’identité des fournisseurs de cloud public est rendue anonyme sur les résultats, et est désignée de C1 à C4[30].
| Taille serveur | configuration | Coût/h | coût/cœur |
|---|---|---|---|
| Amazon EC2 | |||
| petit | 1 ECU, 1.7 GB ram, 160 GB espace disque | 0,085 $ | 0,085 $ |
| grand | 4 ECU, 7.4 GB ram, 850 GB espace disque | 0,34 $ | 0,085 $ |
| moyen - rapide | 5 ECU, 1.7 GB ram, 350 GB espace disque | 0,17 $ | 0,034 $ |
| XL | 8 ECU, 15GB ram, 1.7 TB espace disque | 0,68 $ | 0,085 $ |
| XL- rapide | 20 ECU, 7 GB ram, 1.7 TB espace disque | 0,68 $ | 0,034 $ |
| Cloud privé | |||
| petit | 1 cœur, 2,8 GHz, 1 GB ram, 36 GB espace disque | 0,11 $ | 0,11 $ |
| moyen | 2 cœurs, 3,2 GHz, 2 GB ram, 146 GB espace disque | 0,17 $ | 0,085 $ |
| grand | 4 cœurs, 2 GHz, 4 GB ram, 250 GB espace disque | 0,25 $ | 0,063 $ |
| rapide | 4 cœurs, 3 GHz, 4 GB ram, 600 GB espace disque | 0,53 $ | 0,133 $ |
| XL | 8 cœurs, 2 GHz, 8 GB ram, 1 TB espace disque | 0,60 $ | 0,075 $ |
| Fournisseur | Type instance | Nombre de cœurs | Prix |
|---|---|---|---|
| C1 | C1.1 | 1 | 0,085 $/h |
| C1.2 | 2 | 0,34 $/h | |
| C1.3 | 4 | 0,68 $/h | |
| C2 | C2.1 | 4 | 0,015 $/h |
| C2.2 | 4 | 0,03 $/h | |
| C2.3 | 4 | 0,06 $/h | |
| C2.4 | 4 | 0,12 $/h | |
| C3 | par défaut | N/A | 0,10 $/CPU h |
| C4 | C4.1 | 1 | 0,12 $/h |
| C4.2 | 2 | 0,24 $/h | |
| C4.3 | 4 | 0,48 $/h | |
| C4.4 | 8 | 0,96 $/h |
Cluster élastique



Une grappe de serveurs est chargée à chaque utilisation. Il y a deux types de modèles de charge parmi les fournisseurs : IaaS (AWS, Azure et CloudServers) une charge basée sur le temps alloué restant, que l’instance soit pleinement utilisée ou non ; PaaS (AppEngine), charge basée sur la consommation en excès CPU de l’application utilisateur par jour[31].
Les grappes serveur sont aussi « élastiques » dans le sens où un utilisateur peut augmenter ou réduire dynamiquement le nombre d’instances utilisées. AppEngine effectue cette modification de manière transparente contrairement à AWS, Azure et CloudServer qui supporte un « opaque scaling »[31].
Pour évaluer l'élasticité des cluster, 3 tests ont été effectués[32] :
- Temps d'exécution Benchmark
- similaire au Benchmarking traditionnel pour les architectures, elle mesure le temps d'exécution des tâches benchmark. Les tâches benchmark effectuent un stress test sur toutes les ressources de la machine (CPU, mémoire et le disque)
- Coût
- coût pour effectuer chaque tâche Benchmark
- latence du "Scaling"
- il s'agit du temps écoulé entre la demande de la ressource par le client et l'allocation d'une nouvelle instance. La latence du "scaling" peut affecter les performances et le coût du déploiement d'une application.
Pour les tests, les performances des cluster sont comparées (benchmark, coût par benchmark et latence du scaling)[33].
Stockage persistant
| Service | Opération |
|---|---|
| Table | get, put, query |
| Blob | download, upload |
| Queue | send, receive |
Les services de stockage conservent l'état et les données d'une application et sont accessibles aux instances via des appels API. Il existe 2 modèles économiques pour les opérations de stockage. Les services proposés par Amazon AWS et Google AppEngine se basent sur les cycles CPU consommés pour effectuer une opération de stockage, ce qui rend les requêtes complexes plus coûteuses. Azure et CloudServers possèdent un coût fixe par opération quelle que soit la complexité de la requête[33].
Pour comparer les fournisseurs au niveau du stockage, 3 tests ont été effectués [33]:
- temps de réponse des opérations
- mesure le temps d’exécution d'une opération de stockage. Les opérations effectuées sont supportées par tous les fournisseurs et fréquemment utilisées par les clients. Il s'agit de simples opérations de lecture/écriture, des requêtes SQL pour tester la performance des bases de données.
- l'uniformité des données
- mesure le temps entre l'écriture d'une donnée et lorsque les lectures de celle-ci retournent un résultat valide. Cette information est importante pour les clients, qui désirent que leurs données soient immédiatement disponibles.
- côut par opération
| Fournisseur | get | put | query |
|---|---|---|---|
| C1 | 0.13 | 0.31 | 1.47 |
| C3 | 0.02 | 0.23 | 0.29 |
| C4 | 0.10 | 0.10 | 0.10 |
| Fournisseur | plus petite instance | plus grande instance |
|---|---|---|
| C1 | 773.4 | 782.3 |
| C2 | 235.5 | 265.7 |
| C4 | 327.2 | 763.3 |
Réseau
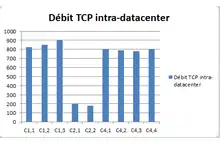

Pour comparer les performances des fournisseurs au niveau du réseau, des tests ont été effectués sur le réseau intra-cloud et sur des réseaux étendus[32].
Le réseau intra-cloud connecte les instances d'un client entre elles et les services partagés par un cloud[32]. Pour comparer les performances d'un réseau intra-cloud, des mesures sur la path capacity et la latence sont effectuées[33].
Le réseau étendu connecte les datacenter d'un cloud entre eux et les hôtes externes sur internet. Les fournisseurs proposent plusieurs zones pour héberger les applications d'un client afin de réduire la latence. AppEngine propose un service DNS pour automatiquement choisir un date center proche lors d'une demande, tandis que les autres fournisseurs demandent une configuration manuelle.Une latence optimale pour un réseau étendu est définie par la latence minimum entre une position optimale et n’importe quel data center d'un fournisseur. Le critère de comparaison des tests sera donc le nombre de data centers disponibles sur un point optimal[32].
Notes et références
Références
- Merino 2011, p. 2
- Brebner 2012, p. 1
- Doaa 2012, p. 2
- Herbst 2013, p. 3
- Herbst 2013, p. 2
- Doaa 2012, p. 3
- Agrawal 2011, p. 2
- Liu 2014, p. 1
- Sedaghat 2013, p. 1
- IBM 2012
- Liu 2014, p. 4
- Liu 2014, p. 0
- Liu 2014, p. 2
- Herbst 2013, p. 0
- Herbst 2013, p. 4
- Sharma 2011, p. 1
- Sharma 2011, p. 2
- Sharma 2011, p. 3
- Fox 2010, p. 8
- Moldovan 2013, p. 1
- Copil 2013, p. 1
- Mao 2012, p. 1
- Coutinho 2013, p. 6
- Doaa 2012, p. 0
- Schahram 2011, p. 2
- Fox 2010, p. 3
- Schahram 2011, p. 3
- Fox 2010, p. 4
- .Li 2010, p. 3
- Li 2010, p. 6
- Li 2010, p. 3
- Li 2010, p. 5
- Li 2010, p. 4
- Li 2010, p. 8
- Li 2010, p. 9
- Li 2010, p. 11
Bibliographie
![]() : document utilisé comme source pour la rédaction de cet article.
: document utilisé comme source pour la rédaction de cet article.
- (en) Doaa M. Shawky et Ahmed F. Ali, « Defining a measure of cloud computing elasticity », Systems and Computer Science (ICSCS), 2012 1st International Conference on, , p. 1-5 (ISBN 978-1-4673-0672-0, DOI 10.1109/IConSCS.2012.6502449, lire en ligne)
 : document utilisé comme source pour la rédaction de cet article.
: document utilisé comme source pour la rédaction de cet article. - (en) Michael Armbrust, Armando Fox, Rean Griffith, Anthony D. Joseph, Randy Katz, Andy Konwinski, Gunho Lee, David Patterson, Ariel Rabkin, Ion Stoica et Matei Zahariacomputing, « A view of cloud », Communications of the ACM Volume 53 Issue 4, , p. 50-58 (DOI 10.1145/1721654.1721672, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) Gandhi Anshul, Dube Parijat, Karve Alexei, Kochut Andrzej et Zhang Li, « Modeling the Impact of Workload on Cloud Resource Scaling », Computer Architecture and High Performance Computing (SBAC-PAD), 2014 IEEE 26th International Symposium on, , p. 310-317 (DOI 10.1145/1721654.1721672, lire en ligne)
- (en) Emanuel Ferreira Coutinho, Danielo Gonçalves Gomes et Jose Neuman de Souza, « An analysis of elasticity in cloud computing environments based on allocation time and resources », Cloud Computing and Communications (LatinCloud), 2nd IEEE Latin American Conference on, , p. 7-12 (DOI 10.1109/LatinCloud.2013.6842214, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) N. R. Herbst, S. Kounev et R. Reussner, « Elasticity in cloud computing: What it is, and what it is not », Proceedings of the 10th International Conference on Autonomic Computing(ICAC 2013), San Jose, CA. USENIX, 2013, pp. 23-27, (lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) Edwin Schouten, « Rapid elasticity and the cloud », sur http://thoughtsoncloud.com/, : document utilisé comme source pour la rédaction de cet article.
- (en) Chien-Yu Liu, Meng-Ru Shie, Yi-Fang Lee, Yu-Chun Lin et Kuan-Chou Lai, « Vertical/Horizontal Resource Scaling Mechanism for Federated Clouds », Information Science and Applications (ICISA), 2014 International Conference on, , p. 1-4 (ISBN 978-1-4799-4443-9, DOI 10.1109/ICISA.2014.6847479, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) Mina Sedaghat, Francisco Hernandez-Rodriguez et Erik Elmroth, « A Virtual Machine Re-packing Approach to the Horizontal vs. Vertical Elasticity Trade-off for Cloud Autoscaling », CAC '13 Proceedings of the 2013 ACM Cloud and Autonomic Computing Conference, (ISBN 978-1-4503-2172-3, DOI 10.1145/2494621.2494628, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) Luis Rodero-Merino, Luis M. Vaquero et Rajkumar Buyya, « Dynamically Scaling Applications in the Cloud », ACM SIGCOMM Computer Communication Review table of contents archive Volume 41 Issue 1, , p. 45-52 (ISSN 0146-4833, DOI 10.1145/1925861.1925869, lire en ligne)
- (en) Sadeka Islam, Kevin Lee, Alan Fekete et Anna Liu, « How a consumer can measure elasticity for cloud platforms », ICPE '12 Proceedings of the 3rd ACM/SPEC International Conference on Performance Engineering, , p. 85-96 (ISBN 978-1-4503-1202-8, DOI 10.1145/2188286.2188301, lire en ligne)
- (en) Schahram, Dustdar, Yike Guo, Benjamin Satzger et Hong-Linh Truong (2011)., « Principles of Elastic Processes. », IEEE Internet Computing, vol. 15, no. 5, pp. 66-71, september/october 2011. (DOI doi:10.1109/MIC.2011.121, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) Chen-Fang Weng et Kuochen Wang, « Dynamic resource allocation for MMOGs in cloud computing environments », Wireless Communications and Mobile Computing Conference (IWCMC), 2012 8th International, , p. 142-146 (ISBN 978-1-4577-1378-1, DOI 10.1109/IWCMC.2012.6314192, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) Kranas, Pavlos (2012)., « ElaaS: An Innovative Elasticity as a Service Framework for Dynamic Management across the Cloud Stack Layers. », Proceedings of Sixth International Conference on Complex, Intelligent and Software Intensive Systems (CISIS) (IEEE), 4-6 july 2012. (DOI doi:10.1109/CISIS.2012.117, lire en ligne)
- (en) Georgiana Copil, Daniel Moldovan, Hong-Linh Truong et Schahram Dustdar., « Multi-level Elasticity Control of Cloud Services. », 11th International Conference, ICSOC 2013, Berlin, Germany, p429-436, 2-5 december 2013. (DOI doi:10.1007/978-3-642-45005-1_31, lire en ligne)
- (en) Daniel Moldovan, Georgiana Copil, Hong-Linh Truong et Schahram Dustdar., « MELA: Monitoring and Analyzing Elasticity of Cloud Services. », IEEE International Conference on Cloud Computing Technology and Science 2013, Bristol, p80-87, 2-5 december 2013. (DOI doi:10.1109/CloudCom.2013.18, lire en ligne)
- (en) Ming Mao et Marty Humphrey ., « A Performance Study on the VM Startup Time in the Cloud », Cloud Computing (CLOUD), 2012 IEEE 5th International Conference on Honolulu, HI, p423 - 430, 24-29 june 2012. (DOI 10.1109/CLOUD.2012.103, lire en ligne)
- (en) P. Brebner, « Is your cloud elastic enough?: performance modelling the elasticity of infrastructure as a service (IaaS) cloud applications », Proceeding ICPE '12 Proceedings of the 3rd ACM/SPEC International Conference on Performance Engineering, , p. 263-266 (ISBN 978-1-4503-1202-8, DOI 10.1145/2188286.2188334, lire en ligne) : document utilisé comme source pour la rédaction de cet article.
- (en) U. Sharma, « A Cost-Aware Elasticity Provisioning System for the cloud », Distributed Computing Systems (ICDCS), 2011 31st International Conference on, , p. 559 - 570 (ISSN 1063-6927, DOI 10.1109/ICDCS.2011.59, lire en ligne)
- (en) A. Eldin, « An adaptive hybrid elasticity controller for cloud infrastructures », Network Operations and Management Symposium (NOMS), 2012 IEEE, , p. 204 - 212 (ISSN 1542-1201, DOI 10.1109/NOMS.2012.6211900, lire en ligne)
- (en) D. Agrawal, « Database Scalability, Elasticity, and Autonomy in the Cloud », 16th International Conference, DASFAA 2011, Hong Kong, China, April 22-25, 2011, Proceedings, Part I, , p. 2-15 (ISBN 978-3-642-20148-6, DOI 10.1007/978-3-642-20149-3_2, lire en ligne)
- (en) Hong-Linh Truong, Daniel Moldovan, Georgiana Copil et Schahram Dustdar., « SYBL: An Extensible Language for Controlling Elasticity in Cloud Applications. », 13th IEEE/ACM International Symposium, 2013, Deft, p112-119, 13-16 may 2013. (DOI doi:10.1109/CCGrid.2013.42, lire en ligne)
- (en) Ang Li, Xiaowei Yang, Srikanth Kandula et Ming Zhang., « CloudCmp: comparing public cloud providers. », IMC '10 Proceedings of the 10th ACM SIGCOMM conference on Internet measurement, 2010, p1-14, 2010. (ISBN 978-1-4503-0483-2, DOI 10.1145/1879141.1879143, lire en ligne) : document utilisé comme source pour la rédaction de cet article.