Table des symboles
Une table de symboles est une centralisation des informations rattachées aux identificateurs d'un programme informatique. C'est une fonction accélératrice de compilation, dont l'efficacité dépend de la conception. Dans une table des symboles, on retrouve des informations comme : le type, l'emplacement mémoire, la portée, la visibilité, etc.

Généralités
Création de la table
Généralement, la table est créée dynamiquement. Une première portion est créée au début de la compilation. Puis, de façon opportuniste, en fonction des besoins, elle est complétée.
Création d'un symbole
La première fois qu'un symbole est vu (au sens des règles de visibilité du langage), une entrée est créée dans la table.
Collecte
Le remplissage de cette table (la collecte des informations) a lieu lors des phases d'analyse.
Identification
L'identification est le processus de recherche d'un identificateur dans la table des symboles.
La table des symboles réunit des informations sur les identificateurs : nature, type, valeur initiale, propriétés d'allocation :
- Pour toute variable, elle garde l’information de : son nom, son type, sa portée et son adresse en mémoire ;
- Pour toute fonction ou procédure, elle garde l’information de : son nom, sa portée, le nom et le type de ses arguments, ainsi que leur mode de passage, et éventuellement le type du résultat qu’elle fournit ;
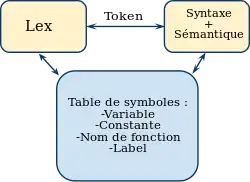
- Pour permettre un accès rapide, la table des symboles est indexée par le nom de l'identificateur (chaîne de caractères), d'où l'utilisation d'une table de hachage ;
- Lors de la définition d'un identificateur, on insère une entrée dans la table de symboles. Cette déclaration est généralement unique, à moins d'une surcharge ;
- Lors de l'utilisation d'un identificateur, on le recherche dans la table ;
- Dans certains compilateurs, les mots-clés du langage ne font pas partie de la syntaxe mais sont insérés dans la table des symboles ;
- Les propriétés d'un identificateur peuvent être des structures complexes (arbres, tables, listes, champs…).
Fonctionnement
- Put Symbole
- Get symbole (vérification de la cohérence du type)
- Begin scope (début de la portée)
- End scope (fin de la portée)
Ainsi on peut modéliser la table de symboles comme une pile, cela permet lors de la lecture du programme de conserver la structure de portée de ce programme informatique.
Structure de hachage
La structure de hachage permet d'avoir un accès rapide et en temps constant sur les noms des variables, procédures et fonctions.
Portée d'un identificateur
Portée d'une déclaration
La portée d'un identificateur correspond à sa zone d'existence (le bloc dans lequel il a été déclaré). Ainsi, plusieurs identificateurs de même nom peuvent référencer des éléments différents. Exemple d'un fragment de code C :
int i() {
int i;
if (1) {
int i;
i = 2;
}
i = 3;
return i;
}
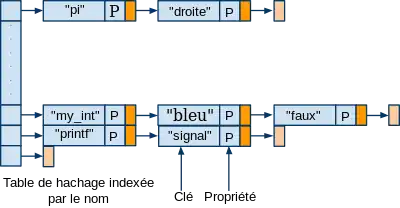
Table des symboles structurée en portée
Pour chaque bloc de programme (ayant des portées différentes) est associée une table de symboles. Chacune de ces tables est elle-même stockée dans une pile globale.
À la lecture du programme :
Quand se présente un nouveau bloc, on empile dans la pile globale une nouvelle table de symboles (pile « locale »).
Quand un bloc se termine, la table de symboles associée sera dépilée et donc détruite.
Pour un bloc donné :
Si on rencontre un identificateur dans une déclaration : on vérifie son absence dans la table en partant du sommet de la pile jusqu’à la fin de la portée (c’est-à-dire toute la pile « locale »). Si c’est le cas on l’ajoute dans la table (cf. 5.Portée d’un identificateur).
Si on rencontre un identificateur dans une partie exécutable : on vérifie sa présence dans la table (pile « locale ») en partant du sommet de la pile jusqu’à la fin. Si cet identificateur n’existe pas il y aura une erreur (cf. 5.Portée d’un identificateur).
Exemple en C :
L1 int main ()
L2 { //début premier bloc
L3 while ()
L4 { //début 2e bloc
L5 for ()
L6 {;//début 3e bloc
L7 } //fin 3e bloc
L8 } //fin 2e bloc
L9 If ()
L10 { //début 4e bloc
L11 For ()
L12 {;//début 5e bloc
L13 } //fin 5e bloc
L14 } //fin 4e bloc
L15 } //fin premier bloc
- État de la pile globale pour la L2 : [TS1]
- État de la pile globale pour la L4 : [TS1,TS2]
- État de la pile globale pour la L6 : [TS1,TS2,TS3]
- État de la pile globale pour la L7 : [TS1,TS2]
- État de la pile globale pour la L8 : [TS1]
- État de la pile globale pour la L10 : [TS1,TS4]
- État de la pile globale pour la L12 : [TS1,TS4,TS5]
- État de la pile globale pour la L13 : [TS1,TS4]
- État de la pile globale pour la L14 : [TS1]
- État de la pile globale pour la L15 : [VIDE]
(avec TSi : table de symboles numéro i)
Une identification se fait en parcourant la pile du sommet à la base.
Avantage
Simplicité : à chaque analyse d'un nouveau bloc de programme, une nouvelle Table est empilée.
La table de symboles du bloc courant est dépilée à la fin de l'analyse.
Inconvénient
L'identification d'un nom peut être lente (à cause de l'accès à plusieurs tables successives).
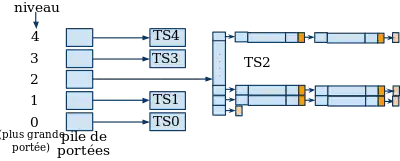
Concept
Une table associative centrale indexée par les noms des identificateurs. Chaque entrée pointe sur une pile de définitions, le sommet de chaque pile est la définition la plus récente.
Pour l’exemple ci-dessus on aurait un code C du type :
int compte; // portée 0
int main()
{
char signal; // portée 1
{
int faux; // portée 2
{
compte++;// portée 3
{
if (faux){} // portée 4
}
}
}
}
Avantage
Identifications rapides
Inconvénient
Suppressions complexes :
Quand on sort d'un bloc, le compilateur a besoin d'actualiser les déclarations visibles (portée des noms). Si on n'utilisait que la table associative, on serait obligé de parcourir toutes les entrées de la table, car on manque d'informations permettant de retrouver la liste des identificateurs déclarés à l'intérieur d'un bloc. Elle nécessite donc une autre structure de données.
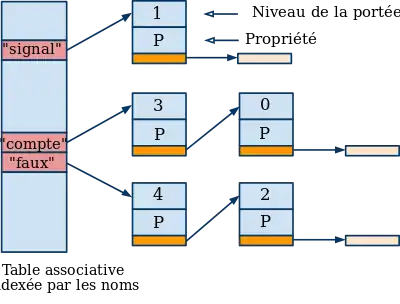
Solution pour accélérer la suppression
Pour accélérer la suppression des entrées (définitions), on utilise en plus une pile de portées qui pointe sur toutes les déclarations d'une portée. Ainsi, à la sortie d'un bloc, il est facile de retrouver toutes les déclarations : la suppression des entrées dans la TS est accélérée.
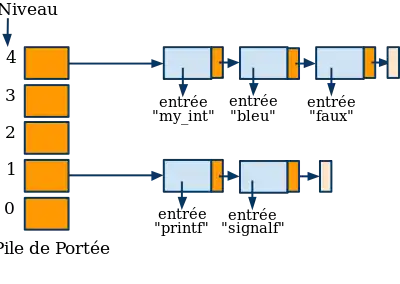
Grâce à cette structure supplémentaire, on peut retrouver les identificateurs du même bloc.
Surcharge
Définition
La surcharge permet de déclarer plusieurs fois le même identificateur (on parle de surcharge uniquement entre les identificateurs du même espace de noms et de la même portée). Elle n'est possible qu'en respectant certaines règles, et seuls certains langages (C++, Ada, Java…) permettent cette propriété.
Problème posé
La surcharge pose un problème d'ambiguïté : en effet, le processus d'identification renvoie un ensemble de définitions au lieu d'une seule.
Solution au problème
La solution à ce problème est d'inclure toutes les déclarations (définitions) dans la table des symboles. Une portée peut donc contenir plusieurs déclarations pour un même identificateur !
La réduction des définitions suit des règles dictées par le langage. Il faut pouvoir analyser le contexte pour se retrouver dans le cas où une seule définition est possible.
Par exemple, certains langages effectuent cette réduction en comparant les listes de paramètres (voir « Signature de type »).