Redondance (centre de données)
La redondance appliquée aux centres de données signifie que les services de base et les systèmes auront des doublons (équipement, liaisons, alimentation et chemins, données, logiciels…) afin de garantir les fonctionnalités dans l’éventualité où l’un de ces composants s’avérerait défaillant. Aujourd’hui, la « haute disponibilité » est pour l’essentiel obtenue par la redondance au niveau de tout l’écosysteme illustrée dans la figure. L’organisation « Uptime Institute » classe les centres de données en quatre niveaux : TIER I, II, III et IV. Ces niveaux correspondent à un certain nombre de garanties sur le type de matériel déployé dans le centre de données en vue d’assurer sa redondance.
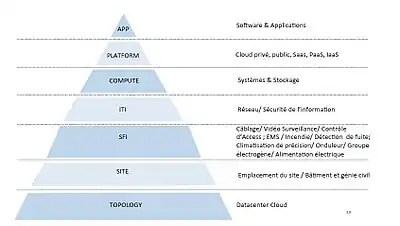
L’évolution du centre de données
En termes de technologie de l'information (TI), les catastrophes varient en type et en étendue. Elles vont de l'interruption des petites entreprises à l'arrêt complet des centres de données. Cela peut être dû à des perturbations d’origines naturelles ou erreurs humaines, allant d'une défaillance matérielle, d'une perturbation du réseau à des événements majeurs reconnus tels qu'un incendie ou une inondation[1].
Par conséquent, avec la croissance de la complexité de l'infrastructure informatique, la fonction de Récupération après Sinistre est devenue une exigence clé pour de nombreuses organisations[1]. Les solutions de Reprise après Sinistre (Disaster Recovery) sont mises en œuvre pour aider le système à résister aux catastrophes en établissant et maintenant un système de sauvegarde à distance utilisant la diversité géographique[2]. Certaines organisations ont tendance à établir un ou plusieurs sites de sauvegarde qui hébergent des ressources informatiques pour atténuer les pannes susceptibles d'affecter leurs fonctions métier et leurs services critiques[1]. En cas de sinistre, le système de sauvegarde remplace rapidement le système de production et récupère les données du système pour assurer qu'aucune donnée ou moins n'est perdue. Ainsi le système garde son fonctionnement sans interruption assurant la continuité des services critiques et reprenant les opérations normales après la reprise[2]. De ce fait, l'objectif de la réplication de l'infrastructure réseau du site de sauvegarde est de fournir une haute disponibilité et de garantir que les services critiques continuent à fonctionner pendant tout événement ou interruption[1]. La capacité à récupérer une catastrophe nécessite une planification efficace et des solutions validées[1].
La récupération du centre de données à la suite d'une défaillance
Objectifs
Le centre de données dispose généralement de dizaines de milliers de périphériques réseau et coûte des millions de dollars à construire et à maintenir[3] - [4]. Dans un tel réseau à grande échelle, les principales causes de défaillances sont les dysfonctionnements matériels / logiciels et des erreurs humaines [5] - [6]. Ces échecs peuvent entraîner une dégradation importante des performances des services réseau exécutés sur le réseau du centre de données. Ainsi, il est crucial de fournir toutes les meilleures pratiques en matière de conception et de redondance pour optimiser la disponibilité et offrir une meilleure performance dans le centre de données.
Échec en réseau
L’internet est le cerveau de l'entreprise puisque c'est l'endroit où tous les processus critiques du centre de données s'exécutent. Ce n'est que par le biais des réseaux ISP que le centre de données sera connecté à Internet. Aujourd'hui, les grandes entreprises et les fournisseurs de contenu, qui dépendent d'Internet, se tournent vers multi-homing. Une approche pour atteindre la résilience aux interruptions de service et pour améliorer la performance, en choisissant le fournisseur le plus performant pour les transferts vers diverses destinations. Multi-homing est défini simplement comme un réseau client (ou ISP) ayant plus d'un lien externe, soit vers un seul FAI, soit vers fournisseurs. Le client a généralement son propre AS (autonome system), et annonce ses préfixes d'adresse via l'ensemble de ses fournisseurs en amont en utilisant BGP[7].
Échec d’un dispositif
Les exigences de disponibilité du réseau sont soumis à la duplication d'éléments de réseau. Le but est de se débarrasser d’un point de défaillance unique, ce qui signifie que la défaillance de tout composant du réseau (un routeur, un commutateur, un serveur physique qui regroupe plusieurs machines virtuelles) entraînera un dysfonctionnement du réseau entier. Divers mécanismes de haute disponibilité comme le cluster, des protocoles pour la redondance de passerelle par défaut ont été conçus pour contourner ce problème[8].
Redondance de passerelle par défaut
Le protocole VRRP (Virtual Router Redundancy Protocol) et le protocole HSRP (Hot Standby Router Protocol) sont des protocoles de redondance de routeur conçus pour augmenter la disponibilité de passerelle par défaut sur le même sous-réseau. Cette fiabilité est obtenue en partageant une adresse IP de routeur virtuel entre plusieurs routeurs physiques pour fournir une passerelle tolérante aux pannes et un basculement transparent en cas de défaillance d'un routeur physique. Le problème de ces protocoles est la non prise de l'équilibrage de charge dont cette question pourrait faire l'objet d'investigations plus poussées à l'avenir[9].
Cluster

Cluster est un mécanisme de tolérance aux pannes qui traite les défaillances de serveur en migrant efficacement les machines virtuelles (VM) hébergées sur le serveur défaillant vers un nouvel emplacement[7]. Aujourd'hui, les fournisseurs de service du cloud préfèrent le centre de données virtuel (VDC) comme unité d'allocation des ressources que les centres de données physiques car les ressources allouées aux VDC peuvent être rapidement ajustées en fonction des besoins des locataires. L'architecture VDCs assure l'évolutivité en distribuant tout l'état de mappage virtuel-vers-physique, de routage et de réservation de bande passante dans les hyperviseurs de serveur. L'algorithme d'allocation VDC regroupe d'abord le réseau de serveurs en différents clusters. Le regroupement est effectué avec le nombre de sauts (hop count) en tant que métrique. Un serveur peut appartenir à plusieurs clusters, par ex. un cluster à deux sauts, un cluster à quatre sauts et l'ensemble du réseau. Lorsqu'un événement d'échec est signalé, l’algorithme essaye de trouver les requêtes dont les chemins de routage passent par le serveur défaillant. Pour ces chemins de routage affectés, de nouveaux chemins sont alloués. Nous effectuons cette opération avant d'essayer de réaffecter les machines virtuelles affectées (lignes 2-7). Après en désalloue les bandes passantes des chemins, qui connectent le serveur défaillant à d'autres serveurs hébergeant d'autres machines virtuelles dans le même VDC (lignes 9-10). Afin de réaffecter la VM, on essaye de trouver un serveur dans le même cluster, où le VDC est hébergé. Nous préférons le même cluster pour minimiser le délai de transmission et nous allouons ces ressources sur ce serveur et hébergeons la VM (ligne 11). Si un tel serveur n'est pas disponible dans le cluster actuel, nous passons à un cluster plus élevé[10].
Echec d’alimentation
Il existe plusieurs composants d'alimentation dans un centre de données et chacun d'entre eux représente un point de défaillance: générateur de secours et commutateur de transfert automatique (ATS), alimentation sans coupure (UPS) et, unité de distribution d'alimentation (PDU). Pour augmenter la fiabilité de ces composants d'alimentation critiques et fournir un environnement à haute disponibilité, la mise en œuvre de serveurs avec deux alimentations est une pratique courante. Dans une installation « parfaite », telle qu'un centre de données de niveau 4, il existe deux chemins d'alimentation complètement indépendants. Chaque chemin et les éléments du chemin doivent pouvoir prendre en charge 100 % de la totalité de la charge du centre de données. Ceci représente la vraie redondance 2N. La redondance 2N signifie qu'il n'y a pas de point de défaillance unique qui interrompra le fonctionnement de l'équipement du centre de données[11]. Les serveurs sont normalement installés et exploités avec les deux PDU. Lorsque les deux alimentations sont actives, les alimentations doubles partagent la charge du serveur à environ 50 % chacune. La seule façon de l’implémenter en toute sécurité est de ne jamais dépasser 40 % de la valeur nominale d’une PDU afin d'éviter une surcharge en cascade au cas d’une faille au niveau d’une PDU. Enfin il faut surveiller et gérer de manière proactive les niveaux de charge sur tous les PDU et tous les autres éléments du chemin d'alimentation[11].
Réplication de données
La réplication des données est une approche efficace pour atteindre une disponibilité et une durabilité élevées des données dans les centres de données. La réplication de données est une technique conçue pour répliquer des données sur deux ou plusieurs nœuds de stockage reliés à différents racks dans un centre de données. Une telle redondance garantit qu'au moins une copie des données est disponible pour un fonctionnement continu en cas de défaillance d'un commutateur de rack ou d'une panne d'alimentation du rack. Cependant, le choix de la conception de la réplication de données est compliqué en conservant les copies aussi étroitement synchronisées que possible et en utilisant le moins de bande passante possible. La mise à jour synchrone de toutes les copies offre une grande résilience à la perte de données, mais présente de mauvaises performances d'écriture et entraîne des coûts de réseau élevés. La bande passante réseau et la latence sont les deux facteurs limitant la réplication des données. Si la bande passante disponible n'est pas suffisante, les messages sont mis en file d'attente dans les mémoires tampon du réseau et, par conséquent, les opérations de lecture et d'écriture sur le volume de stockage physique distant prennent plus de temps. notant qu'un temps de réponse long peut être acceptable pour les applications par lots mais pas pour les applications critiques telles que les transactions en ligne. La latence augmente si le nombre de commutateurs / routeurs / liens sur le chemin de communication des messages augmente et également lorsqu'un commutateur est encombré. Nous notons que la mise en miroir à distance exige une latence ultra-faible et un débit élevé [12] - [13] - [14] - [15].
Réplication de données basée sur SDN

Les architectures SDN (Software-defined networking) dans lesquelles le plan de contrôle est découplé du plan de données deviennent populaires, car les utilisateurs peuvent contrôler intelligemment le mécanisme de routage et d'utilisation des ressources. Un élément essentiel du SDN est qu'il lie explicitement le contrôle du réseau aux exigences fonctionnelles de chaque application. Un commutateur compatible SDN (par exemple OpenFlow [16]) transmet le trafic dans le plan de données en fonction des règles du plan de contrôle qui s'exécutent sur un contrôleur séparé. SDN permet de gérer dynamiquement les flux de trafic, ce qui facilite la réplication des données de stockage à faible bande passante et à faible latence entre centres de données. Nous considérons un réseau de centre de données à routage multiple tel qu'illustré à la Figure 2. Le réseau est composé de commutateurs interconnectés en trois couches: le Top of Rack (ToR), l'agrégat et le core, comme le montre la figure. La figure montre également les pods, hôte de réplication (qui initie l'opération de réplication), le site principal où la copie principale de données est stockée dans un serveur et le site de sauvegarde où la copie de sauvegarde des données est stockée sur un serveur. Une opération de réplication génère deux flux, un flux entre l'hôte et le serveur principal et l'autre flux entre l'hôte et le serveur de sauvegarde[17].
Géo-réplication
La géo-réplication est le processus de conservation des copies de données dans des centres de données géographiquement dispersés pour une meilleure disponibilité et tolérance aux pannes. La caractéristique distinctive de la réplication géographique est la grande latence entre les datacenters qui varie considérablement en fonction de l'emplacement des centres de données. Ainsi, le choix des datacenters à déployer une application cloud a un impact direct sur le temps de réponse observable[18].
Bases de données réparties sur plusieurs centres de données
Les fournisseurs de services Web ont utilisé des banques de données NoSQL pour fournir une évolutivité et une disponibilité pour les données distribuées globalement au détriment des garanties transactionnelles. Récemment, de grands fournisseurs de services Web tels que Google se sont tournés vers la création de systèmes de stockage offrant des garanties transactionnelles ACID pour des données distribuées globalement. Par exemple, le nouveau système Spanner utilise la validation à deux phases et le verrouillage à deux phases pour fournir une atomicité et une isolation globales. données distribuées, s'exécutant au-dessus de Paxos pour fournir une réplication de journal tolérant aux pannes. Il est possible de fournir les mêmes garanties transactionnelles ACID pour les bases de données inter-centres mais avec moins de déclenchements de communication entre centres de données, par rapport à un système utilisant la réplication de journaux, comme Spanner, en utilisant une architecture plus efficace[19].
Redondance de site
La géo-redondance résout les vulnérabilités des équipements redondants colocalisés en séparant géographiquement l'équipement de sauvegarde afin de réduire la probabilité que des événements, tels que des pannes de courant, rendent les ressources de calcul indisponibles. La solution consiste à partager la charge de travail avec le ou les autres sites .Cette configuration est appelée Hot. Ce sont des sites de basculement configurés en cluster active-active. Dans cette configuration, chaque site est actif pour certaines applications et agit en veille pour les applications qui y ne sont pas actives. Cette configuration crée une résilience au niveau du site, permettant le basculement du data center. {citation|Cela constitue «une opportunité clé pour réduire le coût des centres de données de services cloud» en éliminant «une infrastructure coûteuse, telle que les générateurs et les systèmes d'alimentation sans interruption, en permettant à des centres de données entiers d'échouer} [20].
Références
Bibliographie
- (en) Zhenhai Zhao, Tingting Qin, Fangliang Xu, Rui Cao, Xiaoguang Liu et Gang Wang, « CAWRM: A remote mirroring system based on AoDI volume. », IEEE, (ISBN 978-1-4577-0373-7, DOI 10.1109/DSNW.2011.5958793, lire en ligne)
- (en) Weatherspoon, Hakim and Ganesh, Lakshmi and Marian, Tudor and Balakrishnan, Mahesh and Birman, Ken, « Smoke and Mirrors: Reflecting Files at a Geographically Remote Location Without Loss of Performance. », USENIX, (lire en ligne)
- (en) Ji, Minwen and Veitch, Alistair C and Wilkes, John and others, « Seneca: remote mirroring done write. », USENIX, (lire en ligne)
- (en) Patterson, Hugo and Manley, Stephen and Federwisch, Mike and Hitz, Dave and Kleiman, Steve and Owara, Shane, « file system based asynchronous mirroring for disaster recovery. », USENIX, (lire en ligne)
- (en) McKeown, Nick and Anderson, Tom and Balakrishnan, Hari and Parulkar, Guru and Peterson, Larry and Rexford, Jennifer and Shenker, Scott and Turner, Jonathan, « OpenFlow: enabling innovation in campus networks. », ACM, (lire en ligne)
- (en) Zakhary, Victor and Nawab, Faisal and Agrawal, Divyakant and El Abbadi, Amr, « Db-risk: The game of global database placement », ACM, (lire en ligne)
- (en) Mahmoud, Hatem and Nawab, Faisal and Pucher, Alexander and Agrawal, Divyakant and El Abbadi, Amr, « Low-latency multi-datacenter databases using replicated commit. », VLDB, (lire en ligne)
- (en) Al-Essa, Hadeel A and Abdulbaki, Abdulrahman A, « Disaster Recovery Datacenter’s Architecture on Network Replication Solution. », IEEE, (lire en ligne)
- (en) Zhang, Dongyan and Zhang, Tao, « A Multi-channel and Real-Time Disaster Recovery Backup Method Based on P2P Streaming. », IEEE, (lire en ligne)
- (en) Brotherton, HM and Dietz, J Eric, « Data Center Site Redundancy. », IEEE, (lire en ligne)
- (en) Pavlik, Jakub and Komarek, Ales and Sobeslav, Vladimir and Horalek, Josef, « Gateway redundancy protocols. », IEEE, (lire en ligne)
- (en) Kamoun, Faouzi, « Virtualizing the datacenter without compromising server performance. », ACM, (lire en ligne)
- (en) Joshi, Sagar C and Sivalingam, Krishna M, « On fault tolerance in data center network virtualization architectures. », IEEE, (lire en ligne)
- (en) Julius Neudorfer, « Do dual-power supply servers increase redundancy?. », IEEE, (lire en ligne)
- (en) Greenberg, Albert and Hamilton, James and Maltz, David A and Patel, Parveen, « The cost of a cloud: research problems in data center networks. », ACM, (lire en ligne)
- (en) Hu, Chengchen and Yang, Mu and Zheng, Kai and Chen, Kai and Zhang, Xin and Liu, Bin and Guan, Xiaohong, « Automatically configuring the network layer of data centers for cloud computing. », IEEE, (lire en ligne)
- (en) Gill, Phillipa and Jain, Navendu and Nagappan, Nachiappan, « Understanding network failures in data centers: measurement, analysis, and implications. », ACM, (lire en ligne)
- (en) Ma, Xingyu and Hu, Chengchen and Chen, Kai and Zhang, Che and Zhang, Hongtao and Zheng, Kai and Chen, Yan and Sun, Xianda, « Error tolerant address configuration for data center networks with malfunctioning devices. », IEEE, (lire en ligne)
- (en) Akella, Aditya and Maggs, Bruce and Seshan, Srinivasan and Shaikh, Anees and Sitaraman, Ramesh, « A measurement-based analysis of multihoming. », ACM, (lire en ligne)
- (en) Kanagavelu, Renuga and Lee, Bu Sung and Miguel, Rodel Felipe and Mingjie, Luke Ng and others, « Software defined network based adaptive routing for data replication in data centers. », IEEE, (lire en ligne)