Presto (moteur de requête SQL)
Presto est un projet distribué sous licence Apache, qui consiste en un moteur de requête SQL optimisé pour les interactions temps réel.
| Développé par | Facebook dans une moindre mesure Netflix, Airbnb, Groupon |
|---|---|
| Première version | |
| État du projet | Développement |
| Écrit en | Java |
| Environnement | Hadoop |
| Type | Entrepôt de données |
| Licence | Licence Apache version 2.0 |
| Site web | prestodb.io |
Description
Presto, 100 % open source, est un moteur distribué de requête SQL ANSI pour l'exécution des requêtes interactives analytiques sur des sources de données de toutes tailles allant de gigaoctets à pétaoctets. Presto a été conçu dès le départ pour l'analytique interactive permettant une évolution de la taille des organisations telles que Facebook.
Facebook a commencé l'effort de développement sur Presto en 2012, et a été rejoint plus tard par d'autres utilisateurs Presto importants, comme Netflix, Airbnb et Groupon. En , le leader du data-warehousing Teradata rejoint la communauté Presto et propose une feuille de route pour des fonctionnalités 100% open source. Teradata offre un support entreprise pour les utilisateurs de Presto[1] - [2] - [3].
Principaux utilisateurs
Facebook utilise Presto pour des requêtes interactives sur plusieurs datastores internes, avec leur entrepôt Hadoop de 300 Pb.
Netflix gère un entrepôt de données de 25 Pb sur Amazon S3 et utilise Presto pour ses cas d'utilisation interactifs ad hoc.
AirBnb est un contributeur important à la communauté Presto et l'utilise comme moteur de requête par défaut sur un datastore de 1.5 Pb. Airpal, l'outil d’exécution de requête (web) d'AirBnB, s'appuie sur Presto pour l'analyse des données et a été utilisé par plus d'un tiers de ses employés[4].
Architecture
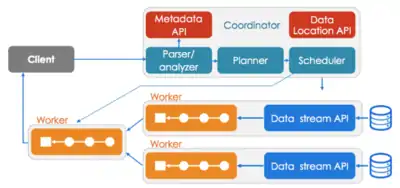
L'architecture de Presto est très similaire aux architectures classiques MPP DBMS. Il peut être visualisé comme un nœud de coordonnateur de travail en synchronisation avec plusieurs nœuds de travail.
Les clients envoient des requêtes SQL qui sont parsées et planifiées en parallélisant les tâches et en ordonnançant les workers. Les Workers joignent les lignes de différentes sources de données afin de retourner un résultat homogène.
L’exécution de requête sur presto est très rapide en raison de la transformation en mémoire. Les données intermédiaires sont reliées par pipeline à travers les nœuds dans le mode MPP.
Fonctionnalités
Support ANSI SQL
Presto offre un vaste support de SQL ANSI, y compris:
- Types de données SQL standard en plus de JSON, ARRAY, MAP et ROW
- Fonctions de fenêtrage
- Fonctions statistiques
- UNNEST et TABLESAMPLE
Capacités d'interface
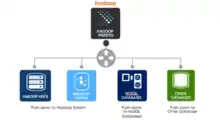
en)) Presto's query federation capabilities⇔Presto permet le requêtage de données là où elles sont, y compris sur HDFS, sur Cassandra, sur des bases relationnelles et quelques data-stores propriétaires.
Une requête Presto unique peut combiner des données provenant de sources multiples, permettant l'analyse à travers l'écosystème de l'entreprise. Presto s'adresse aux analystes qui s'attendent à un temps de réponse allant de la seconde à quelques minutes.
Presto offre actuellement des connecteurs vers de nombreuses sources de données, comme Hadoop HDFS, MySQL, Kafka, Cassandra, PostgreSQL et Redis. Beaucoup d'autres connecteurs peuvent être trouvés sur github. Les connecteurs permettent des jointures à travers les données de différentes sources, par exemple MySQL et HDFS. Les connecteurs supplémentaires aux sources de données continueront à être édité au fil du temps par des contributeurs majeurs de Presto, y compris Teradata.
Références
- "Presto |Distributed SQL Query Engine for Big Data." Presto | Distributed SQL Query Engine for Big Data. Facebook. Web. 6 Oct. 2015.
- "Presto." SQL Engine for Hadoop & More. Teradata. Web. 6 Oct. 2015.
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Presto (SQL query engine) » (voir la liste des auteurs).
- Jacques Cheminat, « Facebook rend Open Source son moteur de requête SQL Presto », Le Monde Informatique, (consulté le )
- Antoine Crochet- Damais, « Big Data : Facebook ouvre les sources de Presto », Journal du net, (consulté le )
- Dominique Filippone, « Teradata supporte Presto, le moteur de requête SQL de Facebook », le Monde Informatique, (consulté le )
- (en) Doug Henschen, « Airbnb Boosts Presto SQL Query Engine For Hadoop », Information Week, (consulté le )