Napping
Le napping[1] est une méthode de recueil des données relatives à la perception d'un ensemble de stimulus, par exemple des produits alimentaires. Elle est utilisée en analyse sensorielle. Dans cette méthode, les dégustateurs doivent représenter spatialement les ressemblances sensorielles qu'ils perçoivent entre les stimulus.
Contexte
Le contexte est celui de l'étude de la façon dont un ensemble de produits est perçu. Classiquement, il est demandé à un jury de dégustateurs d'évaluer chacun des produits à l'aide d'une fiche de dégustation comportant plusieurs descripteurs, par exemple l'acidité, l'amertume. Pour chaque critère et chaque produit, le dégustateur chiffre, sur une échelle allant par exemple de zéro à 10, l'intensité du descripteur telle qu'il la perçoit dans le produit. Cette méthode est fondamentale en analyse sensorielle. Mais elle ne dit rien quant à l'importance des descripteurs dans la perception de l'ensemble des produits proposés. C'est dans cette perspective que le Napping a été imaginé. Cela étant, le Napping est souvent considéré comme une simple méthode descriptive[2].
Description du protocole
L'ensemble des produits, disons des vins pour fixer les idées, est présenté aux dégustateurs. Il est alors demandé à chaque dégustateur de positionner l'ensemble des vins sur une nappe de papier (d'où l'origine du mot Napping) de façon telle que deux vins soient d'autant plus proche qui se ressemblent. Il est bien précisé aux dégustateurs qu'il n'y a pas de bonne ou de mauvaise réponse, qu'il s'agit là d'une perception personnelle et que tous les dégustateurs ne sont pas forcément du même avis. En effet, certains peuvent accorder, par exemple, une grande importance aux aspects olfactifs, d'autres aux aspects gustatifs, etc.
Concrètement, la saisie des données se fait à l'aide d'un écran sur lequel le dégustateur reproduit sa nappe[3].
Données
À chaque dégustateur, sont associées les coordonnées horizontale (X) et verticale (Y) de chaque produit. Cet ensemble de données est appelé nappe. S'il y a produit, ces données peuvent être regroupées dans un tableau ayant lignes (les produits) et deux colonnes (X et Y). S'il y a dégustateurs, les données sont regroupées dans un tableau ayant lignes et colonnes (figure 1).



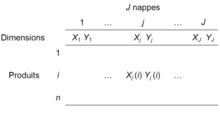
Analyse statistique
Pour analyser ce type de données, l'analyse factorielle multiple (AFM[4]) est parfaitement adaptée[1]. Dans cette analyse, chaque nappe constitue un groupe de deux variables. Pour respecter les distances sur les nappes, les variables ne doivent pas être réduites. Cette AFM fournit plusieurs graphiques dont les deux principaux sont les suivants.
- Une représentation des produits "moyennes", c'est-à-dire aussi proche que possible de l'ensemble des représentations fournies par les dégustateurs (nappe). La première dimension de cette représentation moyenne est en quelque sorte la dimension commune au plus grand nombre de nappes.
- Une représentation des dégustateurs indiquant l'importance que chacun d'eux a accordée aux dimensions de la représentation moyenne. On reconnaît là le modèle INDSCAL. Selon ce point de vue, l'AFM fournit une estimation de ses paramètres.
Petit exemple
Données
Huit vins du Bordelais ont été choisis, selon un plan d’expérience, pour étudier l’importance relative de l’Appellation (Graves ou Médoc), du cépage (Cabernet Sauvignon ou Merlot) et de l’élevage (en fût ou en cuve) sur la perception globale de ce type de vins. L’identificateur des vins commence par un n° d’ordre suivi de trois lettres rappelant les modalités des facteurs du plan. (Tableau 1).
| Identificateur | Appellation | Cépage | Elevage | |
|---|---|---|---|---|
| 1GCf | Graves | Cabernet | fût | |
| 2MCf | Médoc | Cabernet | fût | |
| 3GMf | Graves | Merlot | fût | |
| 4MMf | Médoc | Merlot | fût | |
| 5GCc | Graves | Cabernet | cuve | |
| 6MCc | Médoc | Cabernet | cuve | |
| 7GMc | Graves | Merlot | cuve | |
| 8MMc | Médoc | Merlot | cuve | |







Pour obtenir des données de perception globale de ces vins, on réunit un jury de trois personnes (= juges) auxquelles on propose d’utiliser la démarche du napping. Les données sont rassemblées dans la figure 2.
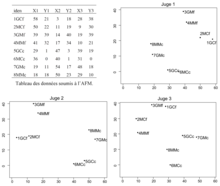
La problématique générale de cette étude s’articule principalement autour d’une question : quelle relation y a-t-il entre l’image globale de ces vins et les trois facteurs du plan utilisé pour choisir les vins ?
Méthodologie
Ces données ont été soumises à une AFM dans laquelle :
- chacune des trois nappes constitue un groupe actif,
- chacun des trois facteurs expérimentaux constitue un groupe supplémentaire.
Résultats
L’AFM a fourni, entre autres, les graphiques des figures 3 et 4.

La figure 3 conduit aux interprétations suivantes.
- Le premier axe oppose de façon très nette les vins 1, 2, 3, 4 aux autres. Ces vins ont été élevés en fût (cf. leurs identificateurs) ce qui n’est pas le cas des autres. Cette opposition est donc une opposition entre élevages. Elle est bien visible sur chaque nappe donc partagée par les trois juges.
- Le second axe oppose les vins 3, 4 7 et 8 aux autres. Ces vins ont été faits avec le cépage Merlot, les autres provenant du cépage cabernet. Il s’agit donc d’une opposition entre cépages. Elle se retrouve bien sur les nappes des juges 1 et 2.

La figure 4 montre les points suivants.
- La première dimension de la configuration moyenne des vins (l’opposition entre les vins {1, 2, 3, 4} et {5, 6, 7, 8}) est importante pour les trois juges (leur coordonnée est maximale le long de cet axe) ; elle est en adéquation presque parfaite avec l’élevage.
- La seconde dimension concerne seulement les juges 1 et 2 (un peu plus le 1 qui a une coordonnée un peu plus grande que celle du juge 2 le long de ce second axe) et est bien moins importante que la première (de fait, l’examen directe des nappes montre d’abord l’opposition entre modes d’élevage). Cette dimension est en outre très liée au cépage mais ne se confond pas avec lui.
- Il n’y a pas de liaison entre l’appellation et les deux principales dimensions de variabilité des images de ces vins.
La représentation des variables qualitatives définissant les vins apporte peu ici par rapport à la figure 3 car les variables sont peu nombreuses et n’ont que deux modalités. Il n’en est pas de même dans la pratique du napping où ce graphique apporte une visualisation des données d’autant plus précieuse que les variables sont nombreuses et comportent beaucoup de modalités.
Extension : le napping catégorisé
Le napping appartient aux méthodes holistiques appelées ainsi parce qu’elles demandent aux juges de considérer chaque produit dans son ensemble (à la différence des méthodes descriptives usuelles qui analysent chaque produit descripteur par descripteur). Une autre méthode holistique est la catégorisation dans laquelle on demande aux juges de faire des groupes de produits.
Ces deux méthodes peuvent être combinées en demandant aux dégustateurs, à l’issue du napping, de regrouper les produits qui leur paraissent particulièrement proches. Cette procédure est appelée napping catégorisé. Les données de napping catégorisé sont complexes en ce sens qu’elles contiennent à la fois des variables quantitatives (les coordonnées sur les nappes) et des variables qualitatives (l’appartenance à des groupes). Elles se traitent par AFM hiérarchique (AFMH)[5].
Historique
Le napping a été introduit en 2003 en Français[6] puis en Anglais en 2005[7]. La première étude utilisant le napping a été réalisée sur des vins de Loire avec Pascale Deneulin, alors étudiante à Agrocampus Rennes[8]. Le napping catégorisé a été introduit en 2010[9]. Ces méthodes ont été largement utilisées par Lucie Perrin dans ses travaux sur les vins de Loire[10]. Le napping est toujours l’objet de recherche et donne lieu à des thèses[11] et des articles[12].
Logiciels
Le package R SensoMineR contient toutes les fonctions nécessaires pour l’analyse de données venant du napping et du napping catégorisé. Il s'appuie sur le package R FactoMineR, qui contient des fonctions pour la plupart des méthodes utiles de l'analyse des données.
Notes et références
- Pagès, 2003
- Dehlholma et al., 2012, Valentin et al., 2012 et Pfeiffer & Gilbert, 2008.
- C'est le cas par exemple du logiciel FIZZ developed by Biosystèmes).
- L'AFM est au cœur des deux livres : Escofier & Pagès, 2008 et Pagès 2013.
- Une description de cette méthode, avec le traitement de données de napping catégorisé se trouve dans Pagès 2013.
- Pagès J., 2003
- Pagès J., 2005
- À la suite de ce travail, le napping est souvent utilisé dans le domaine du vin (exemple).
- Pagès J., Lê S. et Cadoret M., 2010
- Par exemple, le profil "ultra flash" utilisé dans Perrin & Pagès, 2009 et dans / Schneppe et al. dérive directement du napping catégorisé.
- Par exemple celle de Christian Dehlholm.
- Par exemple Giacalone et al., 2013
Bibliographie
- Escofier B. et Pagès J., Analyses factorielles simples et multiples : objectifs, méthodes et interprétation, Paris, Dunod, Paris, , 318 p. (ISBN 978-2-10-051932-3)
- Dehlholm C., Brockhoff P., Meinert L., Aaslyng M. . et Brediea W., « Rapid descriptive sensory methods – Comparison of Free Multiple Sorting, Partial Napping, Napping, Flash Profiling and conventional profiling. », Food Quality and Preference, vol. 26, no 2, , p. 267-277
- Giacalone D., Ribeiro L. et Frost M., « Consumer-based product profiling: application of partial napping® for sensory characterization of specialty beers by novices and experts », Journal of Food Product Marketing, vol. 19, , p. 201-218
- Pagès J., Analyse factorielle multiple avec R, EDP sciences, Paris, , 253 p. (ISBN 978-2-7598-0963-9)
- Pagès J., « Recueil direct de distances sensorielles : application à l’évaluation de dix vins blancs du Val de Loire. », Sciences des aliments, no 23, , p. 679–688
- Pagès J., « Collection and analysis of perceived product inter-distances using multiple factor analysis; application to the study of ten white from the Loire Valley. », Food quality and preference, vol. 16, no 7, , p. 642–649
- Pagès J., Marine Cadoret et Sébastien Lê, « The Sorted Napping: a new holistic approach in sensory evaluation. », Journal of Sensory Studies, vol. 25, no 5, , p. 637–658
- Perrin L. et Pagès J., « Construction of a product space from the Ultra-flash profiling method: application to ten red wines from the Loire Valley. », Journal of Sensory Studies, vol. 24, no 3, , p. 372-395
- Valentin D., Chollet S., Lelièvre M. et Abdi H., « Quick and dirty but still pretty good: a review of new descriptive methods in food science. », International Journal of Food Science and Technology, vol. 47, no 8, , p. 1563-1578
Liens externes
- FactoMineR, une bibliothèque de fonctions R destinée à l'analyse des données.
- SensoMineR, une bibliothèque de fonctions R destinée à l'analyse statistique de données sensorielles.