Mode d'adressage
Les modes d'adressage sont un aspect de l'architecture des processeurs et de leurs jeux d'instructions. Les modes d'adressage définis dans une architecture régissent la façon dont les instructions en langage machine identifient leurs opérandes. Un mode d'adressage spécifie la façon dont est calculée l'adresse mémoire effective d'un opérande à partir de valeurs contenues dans des registres et de constantes contenues dans l'instruction ou ailleurs dans la machine.
En programmation informatique, les personnes concernées par les modes d'adressage sont principalement celles qui programment en assembleur et les auteurs de compilateurs.
Modes d'adressage pour les branchements
L'adresse de la prochaine instruction à exécuter est contenue dans un registre spécial du processeur, appelé compteur ordinal (souvent noté IP, initiales de l'anglais instruction pointer) ou compteur de programme. Les instructions de branchement (ou de saut) visent à modifier la valeur du compteur ordinal. Cette valeur est l'adresse effective de l'instruction de branchement ; elle est calculée différemment selon le mode d'adressage choisi.
Adressage absolu
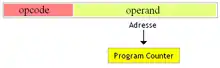
En adressage absolu, l'adresse de destination est donnée dans l'instruction ; on peut donc se rendre n'importe où dans la mémoire (programme). Au moment du branchement, le contenu du pointeur de programme est remplacé par l'adresse en question (si le branchement concerne un sous-programme, on sauvegarde le contenu du pointeur de programme).
Adressage relatif
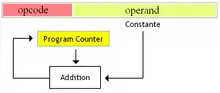
Comme de nombreux branchements s'effectuent vers des adresses mémoire proches de l'endroit où l'on se trouve au moment d'exécuter le branchement, on peut se contenter d'indiquer un décalage par rapport à l'adresse de la prochaine instruction. Par exemple si l'on exécute du code à l'adresse 0x42 et que l'on veut brancher 8 octets plus loin, on peut simplement indiquer +8 pour brancher à 0x4A au lieu d'indiquer cette adresse complète.
Ce mode d'adressage a deux avantages comparé au mode d'adressage absolu. Premièrement, il diminue la quantité de mémoire utilisée par le programme. Cela vient du fait que le décalage prend beaucoup moins de bits qu'une adresse.
Ensuite, ces branchements facilitent l'implémentation de programmes relocalisables, qui peuvent être placés n'importe où en mémoire. C'est une fonctionnalité utilisée pour les bibliothèques dynamiques, qui peuvent être chargées par plusieurs processus à des emplacements différents de leur mémoire : le code n'a pas besoin d'être modifié pour s'adapter à des adresses différentes si les branchements sont relatifs, et peut donc être partagé.
Adressage indirect
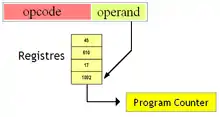
Dans certains cas, l'adresse à laquelle brancher n'est pas connue à la compilation, ou alors celle-ci peut varier selon les circonstances. Cela arrive lorsqu'un programme utilise des pointeurs sur fonction, ou lors de l’utilisation de certains fonctionnalités d'un langage (RTTI, Dynamic Dispatch, etc). Auparavant, on réglait ce genre de situation via du code auto-modifiant. Mais de nos jours, certains processeurs ont réglé ce problème en incorporant un mode d'adressage indirect pour le code.
Avec ce mode d'adressage, l'adresse vers laquelle brancher est stockée dans un registre. Le nom du registre en question est alors incorporé dans la représentation binaire de l'instruction.
Modes d'adressage pour les données
De nombreuses instructions font référence à des données se trouvant à différents endroits de la machine : registres, pile d'exécution, mémoire statique, mémoire dynamique (tas), ports d'E/S.
Adressage implicite
Certaines opérations ne peuvent être réalisées que sur une donnée se trouvant en un endroit bien précis du processeur (par exemple, l'accumulateur ou la pile). Dans ce cas, il n'est pas nécessaire de spécifier l'adresse du registre en question et on parle d'adressage implicite.
Adressage immédiat

C'est un peu un abus de langage que de parler d'adressage dans ce cas-ci. En effet, la donnée est intégrée directement dans la représentation binaire de l'instruction. Ce mode d'adressage permet d'optimiser la gestion des constantes connues à la compilation.
Généralement, les processeurs utilisant ce mode d'adressage utilisent une dizaine de bits pour encoder des opérandes. Diverses études, effectuées par Andrew Tanenbaum, ont montré qu'une grande partie (entre 75 et 90 %) des constantes numériques d'un programme pouvaient tenir sur 14 à 13 bits. Utiliser plus de bits serait donc inutile.
Ce mode d'adressage est utilisé pour des constantes numériques entières. Ce mode d'adressage est rarement utilisé pour des constantes flottantes, en raison de leur grande taille : 32 à 64 bits sur de nombreux processeurs.
Adressage direct
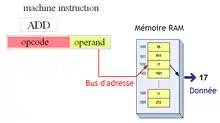
Dans ce mode d'adressage, on donne l'adresse de la donnée en mémoire (RAM, ROM ou port d'E/S s'il est intégré à la mémoire). Ce mode d'adressage permet d'indiquer n'importe quel endroit dans la mémoire, le prix à payer étant que l'on doit spécifier l'adresse concernée dans son intégralité.
Ce mode d'adressage permet parfois de lire ou d'écrire une donnée directement depuis la mémoire sans devoir la copier dans un registre.
De nos jours, ce mode d'adressage ne sert que pour les données dont l'adresse est fixée une bonne fois pour toutes. Les seules données qui respectent cette condition sont les données placées dans la mémoire statique. Pour les programmeurs, cela correspond aux variables globales et aux variables statiques, ainsi qu'à certaines constantes (les chaines de caractères constantes, par exemple).
Autrefois, ce mode d'adressage servait pour toutes les adresses mémoire, y compris celles qui pouvaient varier, comme les adresses utilisées pour manipuler des tableaux. On devait alors utiliser du code auto-modifiant pour faire varier les adresses encodées avec l'adressage direct.
Adressage registre ou inhérent
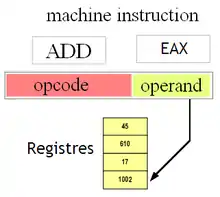
Le processeur dispose d'un certain nombre de registres de travail. Ces registres servent à stocker des données, pour qu'elles puissent servir d'opérandes pour nos instructions machines. De nombreuses instructions y font référence.
Pour sélectionner un registre parmi tous les autres, ceux-ci se voient attribuer un numéro, un identifiant, qu'on appelle un nom de registre. Vu le nombre peu élevé de registres d'un processeur (8, par exemple), il suffit d'un petit nombre de bits pour spécifier cet identifiant directement dans l'instruction manipulant ce registre. On parle dans ce cas d'adressage registre ou inhérent.
Le nombre de bits utilisés pour encoder nos registres dépend fortement du nombre de registres, mais aussi de la spécialisation de ces mêmes registres. Sur certains processeurs, les registres sont regroupés en grands ensembles bien séparés. Par exemple, on peut avoir des registres flottants séparés des registres généraux. Et il se peut que les instructions soient cantonnées à un ensemble de registres : par exemple, on aura des instructions séparées pour les registres flottants et d'autres pour les entiers. Dans ce cas, les identifiants sont spécifiques à un ensemble de registres. Ainsi, un registre flottant pourra réutiliser le même identifiant qu'un registre entier : c'est l'instruction utilisée qui sélectionnera implicitement le bon ensemble de registres.
Ce mode d'adressage n'est pas présent sur toutes les architectures : les processeurs basés sur la pile, et certains processeurs à accumulateurs s'en passent.
Adressage indirect à registre
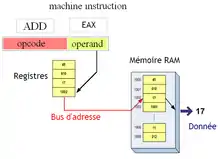
Dans ce mode d'adressage, l'adresse de la donnée se trouve dans un registre du processeur. Ce mode d'adressage permet de préciser dans quel registre se trouve l'adresse de la donnée à accéder. On retrouve donc un nom de registre dans notre instruction, mais celui-ci ne sera pas interprété de la même manière que dans le mode d'adressage inhérent.
Le mode d'adressage indirect à registre permet d'implémenter de façon simple ce qu'on appelle les pointeurs. Au début de l'informatique, les processeurs ne possédaient pas d'instructions ou de modes d'adressage pour gérer les pointeurs. On pouvait quand même gérer ceux-ci, en utilisant l'adressage direct. Mais dans certains cas, cela forçait l'utilisation de self-modifying code, c'est-à-dire que le programme devait contenir des instructions qui devaient modifier certaines instructions avant de les exécuter ! En clair, le programme devait se modifier tout seul pour faire ce qu'il fallait. L'invention de ce mode d'adressage a permis de faciliter le tout : plus besoin de self-modifying code.
Adressage indirect à registre avec incrément ou décrément
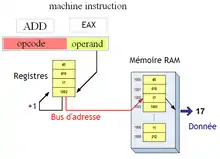
Le mode d'adressage indirect à registre existe aussi avec une variante : l'instruction peut automatiquement augmenter ou diminuer le contenu du registre d'une valeur fixe.
Cela permet de faciliter l'implémentation des parcours de tableaux. Il n'est pas rare qu'un programmeur ait besoin de traiter tous les éléments d'un tableau. Pour cela, il utilise une suite d'instructions qu'il répète sur tous les éléments : il commence par traiter le premier, passe au suivant, et continue ainsi de suite jusqu’au dernier. À chaque étape, l'adresse de l’élément à accéder est augmentée ou diminuée d'une valeur fixe. Ce mode d'adressage permet d'effectuer cette incrémentation ou décrémentation automatiquement.
Adressage indexé absolu
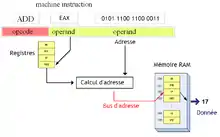
Ce mode d'adressage cherche à faciliter l'utilisation des tableaux en assembleur. Un tableau est un ensemble de données de même taille, placées les unes à côté des autres en mémoire. Pour accéder à un élément d'un tableau, le programmeur doit obligatoirement calculer son adresse et effectuer une lecture/écriture. Grâce au mode d'adressage indexé absolu, ces deux opérations peuvent être effectuées par une seule instruction.
Le calcul d'adresse est assez simple : elle vaut , en posant :

- L la longueur d'un élément du tableau ;
- i l'indice de cet élément ;
- et A l'adresse de début du tableau (l'adresse de l’élément d'indice zéro).
Notre mode d'adressage utilise ces données pour calculer l'adresse de l’élément voulu avant de le lire ou de l'écrire.
Adressage Base + Index
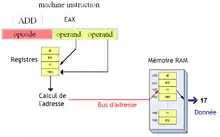
Le mode d'adressage indexé absolu ne fonctionne que pour les tableaux dont l'adresse de base est fixée une fois pour toutes. Or, dans la majorité des cas, les tableaux sont alloués via l'allocation dynamique et ont une adresse de base qui n'est pas connue à la compilation. Celle-ci change donc à chaque exécution, rendant l'adressage indexé absolu assez difficile à utiliser.
Pour contourner les limitations du mode d'adressage indexé absolu, on a inventé le mode d'adressage Base plus index. Avec ce dernier, l'adresse du début du tableau n'est pas stockée dans l'instruction elle-même, mais dans un registre. Elle peut donc varier autant qu'on veut.
Ce mode d'adressage spécifie deux registres dans sa partie variable : un registre qui contient l'adresse de départ du tableau en mémoire : le registre de base ; et un qui contient l'indice : le registre d'index.
Adressage Base + Offset
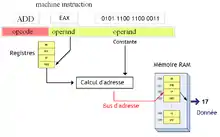
Le mode d'adressage Base + Offset a été inventé pour gérer les structures de façon plus efficace. Ces structures sont des rassemblements de données élémentaires, manipulables par le processeur, comme des pointeurs, des entiers, des flottants, etc. Ces données sont placées les unes après les autres en mémoire.
Pour sélectionner une donnée dans une structure, le processeur doit calculer son adresse. Vu que cette donnée a toujours une place bien précise dans la structure, on peut repérer celle-ci à partir de l'adresse de début de notre structure : il suffit de rajouter le nombre de bytes, dit décalage ou offset, qui séparent notre donnée du début de la structure.
Cette addition entre l'adresse de base et ce nombre de bytes est effectué automatiquement avec l'adressage Base + Offset. L'adresse et le décalage sont stockés dans deux registres.
Modes d'adressage spécialisés pour les digital signal processors
Certains processeurs spécialisés dans le traitement de signal supportent des modes d'adressage spécialisés, afin d'accélérer des traitements et des calculs qu'on trouve couramment dans le traitement de signal. La gestion de files ou les calculs de FFT peuvent ainsi être accélérés par l'utilisation de ces modes d'adressage spécialisés. Deux de ces modes d'adressage sont couramment présents dans les processeurs de traitement de signal (les DSP) : l'adressage modulo et l'adressage bit-reverse.
Adressage Modulo
Les DSPs implémentent des modes d'adressage servant à faciliter l’utilisation de files, des structures de données spéciales, utilisées occasionnellement par les programmeurs de DSP. Ces structures sont des zones de mémoire dans lesquelles on stocke des données dans un certain ordre. On peut y ajouter de nouvelles données, et en retirer. Quand on retire une donnée, c'est la donnée la plus ancienne qui quitte la file.

Ces files sont implémentées avec un tableau, auquel on ajoute deux adresses mémoires : une pour indiquer le début de la file, et l'autre la fin. Le début de la file correspond à l'endroit en mémoire où l'on va insérer les nouvelles données. La fin de la file correspond à la position de la donnée la plus ancienne en mémoire.
À chaque ajout de donnée, l'adresse de la donnée la plus récente est augmentée de la taille de la donnée, afin de réserver la place pour la donnée à ajouter. De même, lors d'une suppression, le pointeur de la donnée la plus ancienne est aussi augmenté, afin de libérer la place qu'il occupait.

Ce tableau a une taille fixe. Si jamais celui-ci se remplit jusqu'à la dernière case, (ici la 5e), il se peut malgré tout qu'il reste de la place au début du tableau : des retraits ont libéré de la place. L'insertion des données reprend au tout début du tableau.
Ce mode de fonctionnement nécessite de vérifier à chaque insertion si l'on a atteint la fin du tableau, avec l'aide d'une comparaison entre adresses De plus, si l'on arrive à la fin du tableau, l'adresse de la donnée la plus récemment ajoutée doit être remise à la bonne valeur : celle pointant sur le début du tableau.
Le mode d'adressage modulo a été inventé pour supprimer la comparaison et la gestion logicielle des débordements. Avec ce mode d'adressage, les deux adresses sont adressées en utilisant le mode d'adressage indirect à registre post ou pré-indexé : l'incrémentation de l'adresse au retrait ou à l'ajout est effectué automatiquement. Ce mode d'adressage vérifie automatiquement que l'adresse ne déborde pas du tableau lors d'une insertion. Si cette adresse "déborde", le processeur la fait pointer au début du tableau. Suivant le DSP, ce mode d'adressage est géré plus ou moins différemment.
La première méthode utilise des registres modulos. Ces registres vont stocker la taille du tableau servant à implémenter notre file. Chacun de ces registres est associé à un registre d'adresse : si jamais on utilise l'adressage modulo dans ce registre d'adresse, le processeur utilisera le contenu du registre modulo pour faire ce qu'il faut. Pour gérer l'adresse de début, le processeur va imposer quelques contraintes sur l'adresse de départ de ce tableau. Cette adresse est souvent alignée à des adresses bien précises, souvent un multiple de 64, 128, ou 256. L'adresse de début de la file est donc le multiple de 64, 128, 256 strictement inférieur le plus proche de l'adresse manipulée.
Autre solution : utiliser deux registres : un pour stocker l'adresse de début du tableau, et un autre pour sa longueur. Certains processeurs DSP utilisent un registre pour stocker l'adresse de début, et un autre pour l'adresse de fin.
Adressage bit-reverse
Le mode d'adressage bit-reverse sert à accélérer les calculs de transformées de Fourier rapides. Ces algorithmes vont prendre des données, stockées dans un tableau, et fournir des résultats, eux aussi écrits dans un tableau. L'ordre de calcul des résultats dans le tableau d'arrivée suit une logique particulière. Les bits de l'adresse du résultat sont partiellement inversés comparé aux bits de l'adresse normale.
Par exemple, pour un tableau de 8 cases, numérotées 0,1, 2, 3, 4, 5, 6, 7, les données arrivent dans cet ordre : 0, 4, 2, 6, 1, 5, 3, 7.
| Ordre normal | Ordre FFT |
| 000 | 000 |
| 001 | 100 |
| 010 | 010 |
| 011 | 110 |
| 100 | 001 |
| 101 | 101 |
| 110 | 011 |
| 111 | 111 |
Les DSPs disposent d'un mode d’adressage qui inverse tout ou partie des bits d'une adresse mémoire, afin de gérer plus facilement les calculs de FFT. Une autre technique consiste à calculer nos adresses différemment. Lors de l'ajout d'un indice à notre adresse, la direction de propagation de la retenue de l'addition est inversée. Certains DSP disposent d'instructions pour faire de genre de calculs.