Disponibilité des hyperviseurs
La disponibilité des machines virtuelles et des hyperviseurs est une préoccupation propre à la sécurité des hyperviseurs et plus généralement à la sécurité informatique. En cas de défaillance, de quelque nature que ce soit, le système virtualisé composé d'hyperviseurs et de machines virtuelles doit garantir la continuité de fonctionnement des services pour lesquels ils ont été mis en place. La disponibilité est assurée grâce à la mise en place de dispositifs agissant sur un ou plusieurs éléments de l'ensemble virtualisé.
Historique
Le développement de la virtualisation des systèmes apparaît dans les années 1960 et au début de la décennie suivante pour répondre aux besoins de réduction des coûts des systèmes physiques de l'époque[1].

En 1974, alors que les professeurs Gerald J. Popek et Robert P. Goldberg effectuaient, sur le mainframe d'IBM 360/370, les premiers travaux sur la virtualisation, ceux-ci ont mis en avant deux problèmes liés à la disponibilité qui concernent en particulier les temps de réponse et la disponibilité des ressources[2]. Dans les années 1980-1990 certains projets comme Amiga, SideCar ou encore Enplant ont essayé d’exploiter cette technologie. Mais certains problèmes, notamment de protection en cas de panne, ont conduit à leur abandon[3]. Lors du DemoFall de 1999, l’entreprise VMware se dévoile au marché et présente son premier produit, VMware Workstation 1.0 pour Linux et Windows[4]. Ce système va permettre d'améliorer, entre autres, la disponibilité des serveurs lors d'une défaillance avec un faible coût de redondance et un redémarrage très rapide du système en cas de panne[5]. Aujourd'hui, les différents acteurs ont inclus diverses solutions dans leurs produits, tel que, le mirroring, la réplication, le basculement de cluster et les snapshots, afin de disposer d'une haute disponibilité[6].
Définition
D'après la norme française X 60-503, la définition de la disponibilité représente l'aptitude d’un dispositif (équipement, système, service), sous les aspects combinés de sa fiabilité, de sa maintenabilité et de la logistique de maintenance, à remplir ou à être en état de remplir une fonction à un instant donné ou dans un intervalle de temps donné[7].
En informatique la disponibilité d'un système désigne une architecture capable de fournir ou de rendre disponible un service lorsque l'utilisateur en a besoin. Cette notion peut être exprimée mathématiquement en fonction de deux paramètres[8] :
- Indice de fiabilité MTBF[note 1]
- Il désigne le temps moyen entre défaillances consécutives. La somme des temps de bon fonctionnement inclut les temps d'arrêts (hors défaillance) et les temps de micro arrêts. Elle peut s'exprimer en unité qui peut par exemple être le nombre de pannes pour 100 heures de production[9].

- Indice de maintenabilité MTTR[note 2]
- Ce paramètre exprime la moyenne des temps de tâches de réparation. Il est calculé en additionnant les temps actifs de maintenance ainsi que les temps annexes de maintenance. Le tout est divisé par le nombre d'interventions[9].

| Temps actifs | Temps annexes |
|---|---|
| Temps de localisation de la défaillance | Temps de détection |
| Temps de diagnostic | Temps d'appel à la maintenance |
| Temps d'intervention | Temps d'arrivée de la maintenance |
| Temps de contrôle et d'essai | Temps propre à la logistique d'intervention |
La disponibilité, qui s'exprime en pourcentage, est calculée de la manière suivante:

Présentation de la disponibilité
La virtualisation et par voie de conséquence sa disponibilité, est devenue un enjeu majeur ces dernières années pour faire face à tout type de défaillances des systèmes réels. Elle permet de réduire les coûts de fonctionnement des systèmes informatiques et augmente la disponibilité des systèmes et des services critiques[11].
Pour utiliser la virtualisation il faut déployer des VMs[note 3] sur un serveur physique. Celles-ci ont besoin d'être contrôlées automatiquement ou manuellement, il faut donc mettre en place un SLO[note 4]. Le composant majeur de ce SLO est la haute disponibilité des systèmes virtualisés[12].
Un certain nombre de procédés ont permis de déterminer des modèles de disponibilité que l'on peut classer en trois groupes[13] :
Objectif et intérêt
Les solutions de haute disponibilité permettent, en cas de défaillance, de maintenir en état de fonctionnement un système virtualisé quel que soit le problème rencontré : système ou applicatif[6].
Ses faiblesses
La recherche de la disponibilité dans la virtualisation évolue en permanence et s'avère être très difficile à mettre en œuvre. La disponibilité peut être perturbée voire arrêtée à la suite de nombreux événements en particulier sur le système hôte lorsqu'il est défaillant[17].
Un système virtualisé peut être interconnecté avec un nombre important de réseaux hétérogènes[18]. Ce genre de configuration provoque des échanges d'informations et de communications de tout type avec de nombreuses possibilités d'accès malveillants. Dans cette hypothèse, la prévention face aux intrusions est plus difficile à assurer et la tolérance aux pannes face aux intrusions malveillantes est donc fragilisée.
La disponibilité est donc un dispositif perfectible et exposé à de nombreux paramètres de perturbation.
La disponibilité pour les machines virtuelles
Éléments de base
La disponibilité des hyperviseurs concerne aussi bien les hyperviseurs eux-mêmes que les machines virtuelles qu’ils contrôlent. L'organisation DMTF[note 5] a défini des états sémantiques pour les machines virtuelles. La spécification de ces états est[19] :
- L'état « Définie »
- Il indique que la machine virtuelle est seulement déclarée dans le système. Elle est inactive et ne consomme pas de ressources systèmes.
- L'état « Active »
- La machine virtuelle fonctionne normalement.
- L'état « Pause »
- Cet état indique que la machine virtuelle reste instanciée mais ne permet pas d'exécuter de tâches.
- L'état « Suspendue »
- La machine virtuelle et ses ressources sont stockées dans une mémoire non volatile. Cet état ne permet pas d'exécuter des opérations.
Niveau de disponibilité
L'équipe de l'entreprise IBM dirigée par Erin M. Farr a mis en place des niveaux de disponibilité en s'appuyant sur les états sémantiques des machines virtuelles et l'IDC[note 6]. En effet l'IDC a établi des niveaux de disponibilité nommés AL1 à AL4 basés sur les expériences passées lors de pannes qui ont alors été définis de manière appropriée pour traiter les défaillances[20]. L'équipe d'IBM a donc généralisé ce concept aux environnements virtuels en mettant en place quatre niveaux de disponibilité nommés de HAVEN1 à HAVEN4 qui correspondent aux niveaux de disponibilité établis par IDC[21].
| Niveau IDC | Description | Niveau HAVEN | Description |
|---|---|---|---|
| IDC niveau 4 (AL4) | Transparent pour l'utilisateur; Pas d'interruption de service; Pas de perte de transactions; Pas de dégradation des performances | Niveau HAVEN4 | Basculement automatique vers une image de la machine virtuelle qui continuera de traiter les mêmes opérations. |
| IDC Niveau 3 (AL3) | Service en ligne; Possibilité de relance de la transaction courante, Possibilité de dégradation des performances | Niveau HAVEN3 | Basculement automatique vers un point de contrôle avant la défaillance de la machine virtuelle. |
| IDC Niveau 2 (AL2) | Utilisateur interrompu mais peut se reconnecter rapidement; Possibilité de relancer plusieurs transactions du fichier de transaction; Possibilité de dégradation des performances | Niveau HAVEN2 | Basculement automatique sur une image de la machine virtuelle précédemment définie. |
| IDC Niveau 1 (AL1) | Impossible de travailler; Arrêt du système; Intégrité des données assurées | Niveau HAVEN1 | Récupération manuelle de la machine virtuelle par un reboot de cette dernière. |
Modèles de la disponibilité des machines virtuelles
Parmi les différents modèles de la disponibilité, plusieurs études se sont appuyées sur le modèle de Markov (en). Ce modèle peut être considéré comme un diagramme d'état avec quelques restrictions mathématiques. La représentation d'un système peut être modélisée par la définition de tous les états que le système peut prendre. Ces états sont reliés par des arcs qui servent à représenter la transition d'un état à l'autre. L'arc peut représenter la probabilité pour passer à l'état suivant, ou la vitesse à laquelle le système se déplace dans l'état suivant[22]. L'équipe du professeur Kim s'est appuyée sur le modèle de Markov pour établir un modèle de la disponibilité des machines virtuelles[23].
Les solutions mises en place pour les machines virtuelles
La haute disponibilité est aujourd'hui un élément essentiel à prendre en compte. Pour permettre de maintenir en état de fonctionnement le système à virtualiser ou les applications en cas de défaillance, un certain nombre de solutions sont mises en place[6]: Deux domaines d'actions sont représentés :
- La redondance des matériels et la mise en cluster : Failover clustering, Mémorisation d'état, Migration à chaud.
- La sécurisation des données : Mirroring, Réplication, RAID, Snapshot.
La redondance des matériels et la mise en cluster
Cluster de basculement
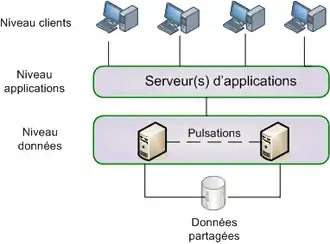
En français cluster de basculement, est une technologie permettant d'automatiser la reprise d'une application ou d'un service sur un autre serveur (nœud)[24]. Un cluster est un terme informatique qui désigne une grappe de serveurs. Cela regroupe une ou plusieurs machines physiques capables de supporter le même ensemble de machines virtuelles.
Failover signifie en langage informatique un basculement qui s'opère lorsque le composant principal est en défaut et que ce dernier ne peut pas fonctionner correctement. Alors le service ou l'application bascule d'une machine en défaut vers une machine en fonctionnement nominal[25].
En référence au schéma ci-contre :
Le niveau Application correspond à un service rendu aux utilisateurs. À ce niveau l'utilisateur ne voit que l'hôte virtuel. Le service de cluster est une application distribuée sur les deux nœuds du cluster et dirige les requêtes vers le serveur (nœud) actif.
Le niveau données abrite les applications et les données associées (BD, messagerie, etc.). La redondance des matériels, des applications et des données y est assurée. Le mécanisme de pulsation est un mécanisme par lequel les nœuds restent en contact permanent afin de détecter les défaillances du nœud actif.
Les données partagées représentent le support physique (indépendant des nœuds) utilisé par le service de cluster pour gérer le basculement (volume SAN[note 7]).
La mémorisation d’état
Un autre moyen utilisé dans la disponibilité est de s’appuyer sur la sauvegarde d’état. Dans ce cadre-là, le système SMP-ReVirt permet de revenir à l’état antérieur à la survenue d’une défaillance, d’un incident de sécurité ou de bug[26]. Ce système nécessite de conserver les états par sauvegarde et de détection du problème à l’aide de la page de protection hardware de la machine virtuelle. L’utilisation en mode multi processeurs permet en fait de disposer en parallèle de l’état et de la configuration d’une même machine virtuelle.
La migration à chaud
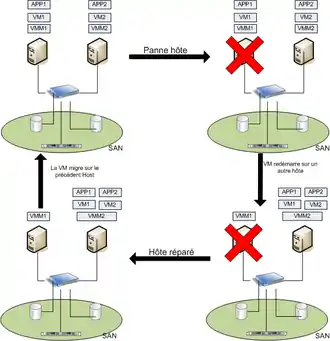
Les machines virtuelles sont dotées de plus en plus d'applications qui sont critiques pour les entreprises. Les différents acteurs du marché ont alors développé des services de haute disponibilité permettant aux applications de toujours fonctionner car le crash d'un élément est en principe transparent[1]. Les solutions qui ont été mises en place par les acteurs se nomment :
Le principe de fonctionnement qui est illustré par le schéma ci-contre est le suivant :
En haut à gauche de l'illustration, deux machines hôtes sont actives et exécutent des applications(APP1 et APP2) au-dessus, respectivement, de deux machines virtuelles(VM1 et VM2). Elles sont managées par les hyperviseurs (VMM1 et VMM2). Un SAN est utilisé pour garantir la disponibilité des données pour les deux applications.
Quand une panne est détectée, la machine virtuelle (VM1) redémarre instantanément sur le second hôte(VMM2). Cet hôte exécute les deux machines virtuelles(VM1 et VM2) jusqu'à que le premier hôte soit réparé. Une fois que l'hôte(VMM1) est réparé, le système reprend son état initial sans qu'aucun arrêt de fonctionnement ne soit initialisé. La migration de la machine virtuelle se fait à chaud, c'est ce que l'on appelle la migration à chaud[1].
La sécurisation des données
Les 4 solutions présentées ci-dessous ont toutes l'objectif de disposer d'un double de l'équipement virtuel à secourir en cas de défaillance. Seul le mécanisme change mais son automatisation est tout le temps recherchée.
Le Mirroring
Cette technique consiste à mettre en place un serveur dit principal puis de créer un serveur dit miroir. Ce dernier sera identique au serveur principal et sera à jour par rapport à lui. En cas de défaillance sur le serveur principal, le serveur miroir assurera la continuité de service sans interruption de services ni perte de données[6].
Réplication
La réplication est définie, techniquement, par un serveur primaire qui publie les données et le détail des transactions à un ou plusieurs autres serveurs[6]. C'est un aspect de la disponibilité qui est très étudié.
Habituellement la réplication s’opère sur la partie logicielle d’une machine virtuelle. En essayant de l’étendre à la partie physique, la disponibilité s’en trouve complétée et donc améliorée. L’architecture proposée par ReNIC (en)[note 8] s’appuie sur ce modèle[30].
Il existe un système basé sur la réplication qui offre une tolérance aux pannes pour n'importe quel type de service centralisé. Dans cet exemple, le système fait fonctionner chaque instance de service dans une machine virtuelle et reproduit dynamiquement l'intégralité de la machine virtuelle. Le service offert à l'utilisateur n'est pas affecté lors de cette opération[31].
Le RAID
La perte d'un serveur physique supportant de nombreuses machines virtuelles aurait un impact significatif, affectant notamment les applications qui fonctionnent sur les machines virtuelles. En conséquence, dans un environnement de serveurs virtuels, il faut mettre en place une stratégie de protection particulièrement importante[32]. La mise en place d'une solution RAID[note 9] est un bon complément au mirroring et à la réplication. Il protège d'une manière efficace contre la perte d'un disque dur[33]. L'étude du professeur Joshi, a démontré que dans un système virtualisé, la solution RAID5 apportait une meilleure sécurisation que les solutions RAID0, RAID1, RAID2, RAID3 ou RAID4[34].
Le snapshot
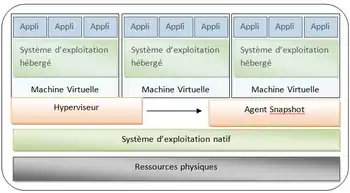
Le principe de cette solution est de prendre périodiquement des photos des états des serveurs. Les utilitaires nécessaires à cette solution sont habituellement intégrés dans les infrastructures de machines virtuelles.
Ils correspondent à des outils standards virtuels qui aident au contrôle de l'infrastructure globale. Sa mise en œuvre est simple, flexible, peu couteuse et efficace[35]. Le snapshot s’appuie sur le mécanisme déjà utilisé classiquement sur tout type de virtualisation consistant à disposer d'une réplique du dispositif à assurer. L’adaptation est ici de la rendre la plus automatique possible.
Les différents acteurs ont intégré cette fonction dans leurs produits. Par exemple les snapshots de VMware permettent de capturer l'intégralité de l'état de la machine virtuelle. Cela comprend la mémoire, les paramètres de configuration et les disques virtuels. Ainsi cette fonction permet de revenir à un état antérieur de la machine virtuelle lorsque c'est nécessaire[36].
Les avantages de la disponibilité pour les machines virtuelles
La disponibilité vise à améliorer les critères de continuité de fonctionnement quelles que soient les circonstances. Elle présente des avantages d'autant plus importants qu'elle est efficace.
Robustesse
La disponibilité permet d'assurer la continuité de fonctionnement en particulier lors d'incidents de fonctionnement. Les moyens d’agir sont d’améliorer la tolérance de fonctionnement face aux pannes par actions proactives, ou par amélioration de la robustesse du système.
Par exemple, la technologie VFT[note 10] utilisée pour le cloud computing en particulier s’appuie sur la détection d’erreurs et le recouvrement vers une situation normalisée en cas d’incident. Un module de cloud management et un autre décisionnel sont utilisés dans ce dispositif de management de la virtualisation[37] - [38].
L’approche traditionnelle pour la tolérance aux pannes inclut des systèmes de vérifications, de redémarrages ou de la duplication. Dans la structure de tolérance aux pannes proactives, l’application est périodiquement contrôlée et lors d’apparitions d’erreurs, elle est totalement ou partiellement relancée[39].
Les hyperviseurs qui s’appuient sur un système de rétablissement proactif offrent des perspectives prometteuses de disponibilité selon l’auteur[18]. En utilisant l’hyperviseur pour initialiser une nouvelle réplique en parallèle au système actif, le temps de perturbation des applications se réduit en cas de reboot.
Économique
La mise en place de la disponibilité sur les machines virtuelles, permet aux utilisateurs de faire des économies d'infrastructures ou de coût énergétique dans les datacenters. L'équipe de M. Liu a démontré que l'on pouvait diminuer de manière significative les coûts de consommation énergétique dans le cas de la migration à chaud[40].
Les aspects sécuritaires
La disponibilité dépend de plusieurs facteurs. Celui sur la sécurité est un élément important surtout ces derniers temps avec le retour en force de la virtualisation. Un certain nombre de projets ont vu le jour afin d'améliorer la disponibilité tout en assurant une protection optimale du système. C'est par exemple le cas du projet HyperShield de l'équipe japonaise de M. Nomoto. En effet ce système permet de migrer vers un autre système d'exploitation tout en assurant la sécurité des machines virtuelles[41].
Virtualiser la sécurité
La nouvelle tendance dans l’industrie est de virtualiser les fonctions de sécurité réseau au sein d’applications de sécurité virtuelles[42]. Ces applications sont placées sur des hôtes qui distribuent alors les fonctions de sécurités nécessaires au travers de clusters.
La disponibilité pour les hyperviseurs
Les 2 types d’hyperviseur et leur disponibilité
Garantir qu’un Hyperviseur soit disponible en cas de défaillance revient à garantir la disponibilité d’une plateforme de virtualisation dont le rôle est de permettre à plusieurs systèmes d’exploitation de travailler sur une même machine physique en même temps. Le procédé pour y parvenir diffère selon le type d’hyperviseurs[43]:
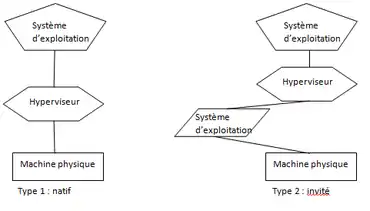
- Hyperviseur de type 1 ou natif
- Dans ce type d’hyperviseur utilisant la paravirtualisation, rechercher la disponibilité revient à garantir la continuité de la fonction de contrôle du système d’exploitation et d’obtenir de bonnes performances de fonctionnement tout en isolant les ressources[44]. Les performances de ces hyperviseurs sont pratiquement équivalentes aux performances d'une machine physique[45].
- Hyperviseur de type 2 ou hébergé
- La disponibilité consiste ici à assurer la continuité de la virtualisation complète qui est définie dans ce type d’ hyperviseur. Il est représenté par un logiciel s’exécutant à l’intérieur d’un autre système d’exploitation. En termes de disponibilité, ce n’est cependant que sur un troisième niveau qu’un système d’exploitation invité s’exécutera en utilisant les services fournis par le système d’exploitation hôte pour gérer la mémoire et l’ordonnancement dans les systèmes d'exploitation des machines virtuelles[46].
À l'image des types de disponibilité pour les machines virtuelles, nous retrouvons les critères de classifications identiques. Cette partie est détaillée sur les machines virtuelles[47].
Les solutions mises en place pour les hyperviseurs
Beaucoup de recherches et d'études ont été faites sur les moyens de garantir la disponibilité grâce aux hyperviseurs. En parallèle, les dispositifs améliorant la disponibilité sur les hyperviseurs commencent à apparaître. Ceux-ci reprennent des principes déjà éprouvés sur les machines virtuelles comme la réplication ou la solution à plusieurs hyperviseurs.
3 techniques essentielles existent:
- Les solutions multi-hyperviseurs
Dans la solution MultiHype, l’architecture proposée se compose de plusieurs hyperviseurs sur une unique plateforme physique. Chaque machine virtuelle de ce dispositif fonctionne en concurrence et indépendamment les unes des autres.
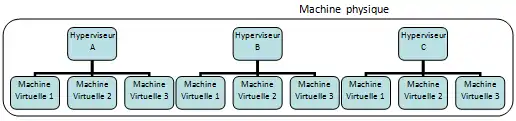
Ce système permet de confiner toute anomalie sur son propre périmètre sans perturber les autres. Grâce à ce type de protection, l’ensemble est plus résistant et moins sensible aux attaques et défaillances de tout type. La disponibilité de cette virtualisation s’en trouve améliorée. La configuration comporte un contrôle de la mémoire et un système d’isolement pour faire face aux défaillances des machines virtuelles[48].
- Les solutions à base de réplication
Le dispositif Remus[49] permet ainsi d'offrir une haute tolérance aux pannes sans avoir à modifier la partie logicielle où se trouve l'hyperviseur. Il s'agit d'encapsuler ici la partie logicielle à protéger au sein même d'une machine virtuelle et de diffuser les changements d'état vers un hôte de secours à une fréquence supérieure à 40 fois par seconde. En parallèle, il s'agit d'utiliser aussi discrètement que possible une machine virtuelle active dans le but de répliquer l'état de fonctionnement et la configuration mise en œuvre. Le but recherché est de répliquer des snapshots d'instances complètes de systèmes à une période maximale de 25ms entre 2 machines physiques.
Le dispositif Romulus basé sur la technologie type KVM. Il s’agit d’un prototype de réplication de machines virtuelles utilisant la technologie Kernel (que l’on compare ici avec la technologie XEN). L’implémentation est entièrement faite dans l’espace utilisateur en ne relayant seulement au niveau du noyau de type Kernel, que les fonctionnalités qui sont incluses dans le noyau Linux original[note 11].
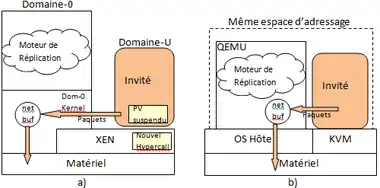
Une étude comparative a été réalisée entre les 2 technologies bien distinctes que sont a) Xen et b) Kernel. Dans cette étude, la technologie Xen est mise en œuvre dans l'hyperviseur Remus alors que la technologie Kernel est utilisée pour l'hyperviseur Romulus. La technologie Xen est bien plus éprouvée que la technologie Kernel[50]. Cette comparaison, jugée inhabituelle par son auteur D. Petrovic, vise à rechercher lequel de ces 2 types d'hyperviseurs basés sur la réplication est le plus efficace en termes de disponibilité. Le résultat est nettement à l’avantage de l’architecture KVM grâce en particulier au coût bien moindre du protocole nécessaire à la réplication[51].
L'architecture permettant une tolérance aux défaillances d'intrusion dans les machines virtuelles repose sur le principe de la réplication de services de réseaux s'appuyant sur les hyperviseurs de type Xen.
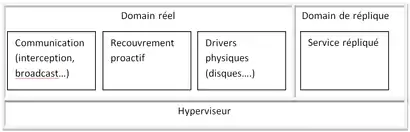
Cette solution s'appuyant sur la technologie des hyperviseurs permet de fournir des communications et de la réplication dans un domaine dédié pendant que le service répliqué est exécuté dans un autre domaine hôte et isolé. Les 2 parties étant isolées grâce en particulier à l'hyperviseur, le recouvrement est plus facile et plus efficace en cas de défaillance ou d'intrusion malveillante.
Chaque élément de l'infrastructure peut être répété. il peut ainsi constituer un ensemble répliqué de toute part pour créer l'architecture complète de réplication[52]. Au moindre problème, la réplique créée prend alors la relève du système principal pour éviter les défaillances et les indisponibilités éventuelles des fonctionnalités mises en œuvre.
La disponibilité peut être améliorée à l’aide d’un algorithme de réplication[53]. Celui-ci adapte le contexte de fonctionnement au comportement du service souhaité et de la bande passante disponible entre les éléments principaux et les éléments de secours. Cet algorithme est perçu comme une extension des hyperviseurs de type Xen. Dans cette configuration, il s’agit de créer des reproductions de services et de les faire fonctionner ensemble dans une distribution centralisée[54]. Cet algorithme calcule chaque phase de durée de réplication. Elles sont basées sur la caractérisation des échanges mémoires locaux du service protégé et du nombre de paquets réseaux en sortie générés pendant cette phase de calcul. Il prend aussi en compte la disponibilité de la bande passante entre les nœuds primaires et de secours[53].
- Les solutions intégrées
Dans le domaine de la disponibilité des hyperviseurs, la technique de renouvellement de la haute disponibilité dans les systèmes virtualisés s’exécute aussi bien pour les machines virtuelles que pour les hyperviseurs sans nécessité de faire de modification des applications. Cette technique améliore la disponibilité des 2 éléments avec des temps d'arrêts moins longs en cas de nécessité[55].
La solution d'infrastructure logicielle CIVIC, de par sa configuration, offre un environnement indépendant à chaque utilisateur et permet un contrôle centralisé tant sur la partie hardware que logicielle. Cette configuration améliore ainsi la disponibilité des ressources et facilite grandement toute la partie mise en œuvre du système virtualisé[56].
Les avantages de la disponibilité pour les hyperviseurs
La disponibilité est encore plus importante pour les hyperviseurs car ils sont chargés du contrôle des machines virtuelles. Les hyperviseurs présentent cependant plusieurs avantages dont la disponibilité ou la continuité de service des systèmes virtualisés, la résistance aux attaques malveillantes, la réduction des coûts de fonctionnement et la facilité de mise en œuvre[57].
La continuité de service
Lors d'un incident d'hyperviseur de quelques secondes, la continuité de service consiste à maintenir le fonctionnement des programmes en cours sans interruption. La solution Remus fournit en ce sens une excellente tolérance aux pannes. Lors d'une défaillance de quelques secondes, ce dispositif permet la continuité d'exécution des programmes en cours[49]. Les hyperviseurs qui s’appuient sur un système de rétablissement proactif offrent des perspectives prometteuses de disponibilité selon l’auteur[18]. Si l'on utilise l’hyperviseur pour initialiser une réplique de secours en parallèle au système actif, le temps de perturbation des applications se réduit en cas de redémarrage.
La sécurité
Le second attrait de la disponibilité des hyperviseurs est de type sécuritaire. De nombreux développements ont été réalisés sur ce sujet. La solution de type multi-hyperviseur offre ainsi une excellente garantie de sécurité informatique en confinant l'hyperviseur malveillant du reste de la structure[48]. Un autre dispositif sécuritaire s'appuie sur les systèmes à base de réplication alliés au critère de tolérance aux erreurs d'intrusions. C'est à partir de la surveillance de ce critère que la réplication s'active[18].
Économique
Il est moins couteux de mettre en place des dispositifs de protection sur des systèmes virtuels que sur des systèmes réels. Une comparaison du coût de 3 types de solutions d'hyperviseur pour obtenir un certain niveau de disponibilité a été réalisée en tenant compte des coûts des processeurs, des mémoires et des communications. Il en résulte que pour un même coût, la résistance de fonctionnement optimal diffère grandement selon les types d'infrastructures choisies. L'étude est réalisée pour comparer les performances de fonctionnement et de disponibilité en se basant sur un même coût pour les 3 types de solutions d'hyperviseur[58].
Notes et références
Notes
- MTBF pour Mean Time Between Failures qui pourrait être traduit par Temps moyen entre pannes
- MTTR pour Mean Time To Repair qui pourrait être traduit par Temps moyen de réparation
- VMs pour Virtual Machine qui pourrait être traduit par machines virtuelles
- SLO pour Service Level Objectives qui pourrait être traduit par objectifs de niveau de service
- DMTF pour Distributed Management Task Force représente l'organisation qui maintient des standards pour l'administration de systèmes informatiques
- IDC pour International Data Corporation représente une entreprise américaine spécialisé dans l'étude de marché
- SAN pour Storage Aera Network qui peut être traduit par Un réseau de stockage
- ReNIC pour Replicable Network Interface Controller qui peut être traduit par Réplication du contrôleur d'interface réseau
- RAID pour Redundant Array of Independent(or inexpensive) Disks que l'on peut traduire par regroupement redondant de disques indépendants
- VFT pour Virtualization Fault Tolerance que l'on peut traduire par Virtualisation et Tolérance aux Fautes
- KVM pour kernel Virtual Machine qui pourrait être traduit par Machine Virtuelle de type Kernel
Références
- Matos 2012, p. 995
- Popek 1974, p. 417
- Gelibert 2012, p. 7
- L'Informaticien 2010, p. 1
- vmware 2000, p. 10
- Chan 2012, p. 2
- AFNOR 1985, p. 6
- Correia 2011, p. 1
- Oggerino 2001, p. 12
- Zhang 2009, p. 200
- Matos 2012, p. 994
- Kim 2009, p. 365
- Paharsingh 2012, p. 16
- Paharsingh 2012, p. 17
- Paharsingh 2012, p. 19
- Paharsingh 2012, p. 21
- Weidong 2012, p. 76
- Reiser 2007, p. 83
- DMTF 2010, p. 17
- IDC 2010, p. 3
- Farr 2008, p. 677
- Paharsingh 2012, p. 40
- Kim 2009, p. 368
- Yang 2010, p. 408
- GIPSA 2012, p. 30
- George 2008, p. 121
- XenServer 2011, p. 3
- Thurrott 2010, p. 1
- VMware 2007, p. 5
- Dong 2012, p. 40.1
- Colesa 2009, p. 339
- Joshi 2010, p. 278
- Joshi 2010, p. 279
- Joshi 2010, p. 282
- Chan 2012, p. 1
- VMware 2012, p. 11
- Das 2013, p. 47
- Yang 2011, p. 122
- Vallee 2008, p. 659
- Liu 2011, p. 659
- Nomoto 2010, p. 37
- Debashis 2010, p. 86
- Scheffy 2007, p. 14-27
- Barham 2003, p. 165
- Barham 2003, p. 176
- Benkemoun, p. 14
- haven 2008, p. 675
- Weidong 2012, p. 75
- Cully 2008, p. 161
- Petrovic 2012, p. 76
- Petrovic 2012, p. 73
- Reiser 2011, p. 371
- Mihai 2011, p. 943
- Mihai 2011, p. 941
- Rezaei 2010, p. 289
- Jinpeng 2007, p. 51
- Regola 2008, p. 409
- Yu 2010, p. 7
Bibliographie
![]() : document utilisé comme source pour la rédaction de cet article.
: document utilisé comme source pour la rédaction de cet article.
- (fr)David GELIBERT, Farid SMILI, Jérôme DEROCK, Loïc RATSIHORIMANANA, Mickaël DREYER et Thomas GERVAISE, Livre blanc : La sécurité et la virtualisation, Polytech Lyon, , 54 p. (lire en ligne).

- (fr) La rédaction de L'Informaticien, « Site L'informaticien "VMWARE : Une réussite loin d’être virtuelle" »,
- (en) VMware, « Site VMware "User's manual VMware ESX Server Version 1.0" », , p. 152
- (en) DMTF, « Virtual System Profile », , p. 56
- (fr) IDC, « "Oracle's MAA Portfolio : Deploying High-Availability Solutions Across the Enterprise" », , p. 13
- (fr) « Terminologie relative à la Fiabilité - Maintenabilité - Disponibilité extrait NF X 60-503 », AFNOR, , p. 1 - 42 (lire en ligne)
- (en) Chris Oggerino, High Availability Network Fundamentals, Cisco Press, , 237 p. (ISBN 1-58713-017-3, lire en ligne)
- (en) Citrix XenServer, « Site Ctrix : "Storage XenMotion: Live Storage Migration with Citrix XenServer®" » [archive du ], (consulté le ), p. 7
- (en) Paul Thurrott, « "Windows Server Virtualization Preview" »,
- (en) Vmware, « "Automating High Availability (HA) Services with VMware HA" », , p. 15
- (fr) Lucas Bonnet, État de l’art des solutions libres de virtualisation pour une petite entreprise, Livre blanc, 95 p. (lire en ligne)
- (fr) Christian Bulfone, « Serveur et virtualisation », GIPSA-lab, , p. 60
- (en) Ricardo Paharsingh, « Availability Modeling of Computing Systems with Virtual Architectures », , p. 102
- (fr) VMware, « Guide d'administration d'une machine virtuelle vSphere », , p. 178
- (en) Chan Hoi et Chieu Trieu, « An approach to high availability for cloud servers with snapshot mechanism », MIDDLEWARE '12 Proceedings of the Industrial Track of the 13th ACM/IFIP/USENIX International Middleware Conference, (ISBN 978-1-4503-1613-2, DOI 10.1145/2405146.2405152)
- (en) Dong Yaozu, Chen Yu, Pan Zhenhao et Jiang Yunhong, « ReNIC: Architectural extension to SR-IOV I/O virtualization for efficient replication », Journal ACM Transactions on Architecture and Code Optimization (TACO) - HIPEAC Papers, , p. 40-1 - 40-22 (DOI 10.1145/2086696.2086719)
- (en) Daniel J. Scales, Mike Nelson et Ganesh Venkitachalam, « The design of a practical system for fault-tolerant virtual machines », ACM SIGOPS Operating Systems Review, , p. 30 - 39 (DOI 10.1145/1899928.1899932)
- (en) George W. Dunlap, Dominic G. Lucchetti, Michael A. Fetterman et Peter M. Chen, « Execution replay of multiprocessor virtual machines », VEE '08 Proceedings of the fourth ACM SIGPLAN/SIGOPS international conference on Virtual execution environments, , p. 121 - 130 (ISBN 978-1-59593-796-4, DOI 10.1145/1346256.1346273)
- (en) Debashis Basak, Rohit Toshniwal, Serge Maskalik et Allwyn Sequeira, « Virtualizing networking and security in the cloud », ACM SIGOPS Operating Systems Review, , p. 86 - 94 (DOI 10.1145/1899928.1899939)
- (en) S. Laniepce, M. Lacoste, M. Kassi-Lahlou, F. Bignon, K. Lazri et A. Wailly, « Engineering Intrusion Prevention Services for IaaS Clouds: The Way of the Hypervisor », Service Oriented System Engineering (SOSE), 2013 IEEE 7th International Symposium on, , p. 25 - 36 (ISBN 978-1-4673-5659-6, DOI 10.1109/SOSE.2013.27)
- (en) P. Das et P.M. Khilar, « VFT: A virtualization and fault tolerance approach for cloud computing », Information & Communication Technologies (ICT), 2013 IEEE Conference on, 11-12 april 2013, p. 473 - 478 (ISBN 978-1-4673-5759-3, DOI 10.1109/CICT.2013.6558142)
- (en) Yang Chao-Tung, Chou Wei-Li, Hsu Ching-Hsien et A. Cuzzocrea, « On Improvement of Cloud Virtual Machine Availability with Virtualization Fault Tolerance Mechanism », Cloud Computing Technology and Science (CloudCom), 2011 IEEE Third International Conference on, nov. 29 2011-dec. 1 2011, p. 122 - 129 (ISBN 978-1-4673-0090-2, DOI 10.1109/CloudCom.2011.26)
- (en) G. Vallee, C. Engelmann, A. Tikotekar, T. Naughton, K. Charoenpornwattana, C. Leangsuksun et S.L. Scott, « A Framework for Proactive Fault Tolerance », Availability, Reliability and Security, 2008. ARES 08. Third International Conference on, 4-7 march 2008, p. 659 - 664 (ISBN 978-0-7695-3102-1, DOI 10.1109/ARES.2008.171)
- (en) H.P. Reiser et R. Kapitza, « Hypervisor-Based Efficient Proactive Recovery », Reliable Distributed Systems, 2007. SRDS 2007. 26th IEEE International Symposium on, 10-12 oct. 2007, p. 83 - 92 (ISBN 0-7695-2995-X, DOI 10.1109/SRDS.2007.25)
- (en) Min Lee, A.S. Krishnakumar, P. Krishnan, N. Singh et S. Yajnik, « Hypervisor-assisted application checkpointing in virtualized environments », Dependable Systems & Networks (DSN), 2011 IEEE/IFIP 41st International Conference on, 27-30 june 2011, p. 371 - 382 (ISBN 978-1-4244-9231-2, DOI 10.1109/DSN.2011.5958250)
- (en) Kim Dong Seong, F. Machida et K.S. Trivedi, « Availability Modeling and Analysis of a Virtualized System », Dependable Computing, 2009. PRDC '09. 15th IEEE Pacific Rim International Symposium on, 16-18 nov. 2009, p. 365 - 371 (ISBN 978-0-7695-3849-5, DOI 10.1109/PRDC.2009.64)
- (en) Brendan Cully, Geoffrey Lefebvre, Dutch Meyer, Mike Feeley, Norm Hutchinson et Andrew Warfield, « Remus: high availability via asynchronous virtual machine replication », NSDI'08 Proceedings of the 5th USENIX Symposium on Networked Systems Design and Implementation on, , p. 161-174 (lire en ligne)
- (en) T. Nomoto, Y. Oyama, H. Eiraku, T. Shinagawa et K. Kato, « Using a Hypervisor to Migrate Running Operating Systems to Secure Virtual Machines », Computer Software and Applications Conference (COMPSAC), 2010 IEEE 34th Annual, 19-23 july 2010, p. 37-46 (ISBN 978-0-7695-4085-6, DOI 10.1109/COMPSAC.2010.11)
- (en) Jin Seongwook, Jinho Seol et Seungryoul Maeng, « Towards Assurance of Availability in Virtualized Cloud System », Cluster, Cloud and Grid Computing (CCGrid), 2013 13th IEEE/ACM International Symposium on, 13-16 may 2013, p. 192 - 193 (ISBN 978-1-4673-6465-2, DOI 10.1109/CCGrid.2013.110)
- (en) R.D.S. Matos, P.R.M. Maciel, F. Machida, Kim Dong Seong et K.S. Trivedi, « Sensitivity Analysis of Server Virtualized System Availability », Reliability, IEEE Transactions on (Volume:61 , Issue: 4), , p. 994 - 1006 (ISBN 978-1-4244-9231-2, DOI 10.1109/TR.2012.2220711)
- (en) S. Correia, G. Cherkaoui et J. Celestino, « Increasing router availability through virtualization », Global Information Infrastructure Symposium (GIIS), 2011, 4-6 aug. 2011, p. 1 - 6 (ISBN 978-1-4577-1260-9, DOI 10.1109/GIIS.2011.6026697)
- (en) Weidong Shi, JongHyuk Lee, Taeweon Suh, Dong Hyuk Woo et Xinwen Zhang, « Architectural support of multiple hypervisor over single platform for enhancing cloud computing security », CF '12 Proceedings of the 9th conference on Computing Frontiers, , Pages 75-84 (ISBN 978-1-4503-1215-8, DOI 10.1145/2212908.2212920)
- (en) A. Rezaei et M. Sharifi, « Rejuvenating High Available Virtualized Systems », Availability, Reliability, and Security, 2010. ARES '10 International Conference on, ju15-18 feb. 2010, p. 289 - 294 (ISBN 978-1-4244-5879-0, DOI 10.1109/ARES.2010.69)
- (en) Erin M. Farr, Richard E. Harper, Lisa F. Spainhower et Jimi Xenidis, « A Case for High Availability in a Virtualized Environment (HAVEN) », Availability, Reliability and Security, 2008. ARES 08. Third International Conference on, 4-7 march 2008, p. 675 - 682 (ISBN 978-0-7695-3102-1, DOI 10.1109/ARES.2008.182)
- (en) D. Petrovic et A. Schiper, « Implementing Virtual Machine Replication: A Case Study Using Xen and KVM », Advanced Information Networking and Applications (AINA), 2012 IEEE 26th International Conference on, 26-29 march 2012, p. 73 - 80 (ISBN 978-1-4673-0714-7, DOI 10.1109/AINA.2012.50)
- (en) M. Hirano, T. Shingagawa, H. Eiraku et S. Hasegawa, « A Two-Step Execution Mechanism for Thin Secure Hypervisors », Emerging Security Information, Systems and Technologies, 2009. SECURWARE '09. Third International Conference on, 18-23 june 2009, p. 129 - 135 (ISBN 978-0-7695-3668-2, DOI 10.1109/SECURWARE.2009.27)
- (en) Adrian. Colesa, Bogdan Marincas, Iosif Ignat et Cosmin Ardelean, « Strategies to transparently make a centralized service highly-available », Intelligent Computer Communication and Processing, 2009. ICCP 2009. IEEE 5th International Conference on, 27-29 aug. 2009, p. 339 - 342 (ISBN 978-1-4244-5007-7, DOI 10.1109/ICCP.2009.5284741)
- (en) Adrian. Colesa et Bica Mihai, « An adaptive virtual machine replication algorithm for highly-available services », Computer Science and Information Systems (FedCSIS), 2011 Federated Conference on Computer Science and Information Systems, 18-21 sept. 2011, p. 941 - 948 (ISBN 978-1-4577-0041-5, lire en ligne)
- (en) Huai Jinpeng, Li Qin et Hu Chunming, « CIVIC: a Hypervisor based Virtual Computing Environment », Parallel Processing Workshops, 2007. ICPPW 2007. International Conference on, 10-14 sept. 2007, p. 51 (ISBN 978-0-7695-2934-9, DOI 10.1109/ICPPW.2007.28)
- (en) Paul Barham, Boris Dragovic, Keir Fraser, Steven Hand, Tim Harris, Alex Ho, Rolf Neugebauer, Ian Pratt et Andrew Warfield, « Xen and the art of virtualization », SOSP '03 Proceedings of the nineteenth ACM symposium on Operating systems principles, , p. 164-177 (ISBN 1-58113-757-5, DOI 10.1145/945445.945462)
- (en) Gerald J. Popek et Robert P. Goldberg, « Formal requirements for virtualizable third generation architectures », Magazine Communications of the ACM CACM, , p. 412-421 (DOI 10.1145/361011.361073)
- (en) Xu Zhang, Chuang Lin et Xiangzhen Kong, « Model-Driven Dependability Analysis of Virtualization Systems », Computer and Information Science, 2009. ICIS 2009. Eighth IEEE/ACIS International Conference on, janu 1-3 june 2009, p. 199 - 204 (ISBN 978-0-7695-3641-5, DOI 10.1109/ICIS.2009.36)
- (en) Shubhalaxmi Joshi, Umesh Patwardhan et Pallavi Deshpande, « Raid 5 for Secured Storage Virtualisation », Data Storage and Data Engineering (DSDE), 2010 International Conference on, 9-10 feb. 2010, p. 278 - 282 (ISBN 978-1-4244-5678-9, DOI 10.1109/DSDE.2010.67)
- (en) Yang Liu et Jie-Bin Xu, « Analysis And Optimization Of Fast Faillure Detection And Failover For HA Cluster-Based Systems », Machine Learning and Cybernetics (ICMLC), 2010 International Conference on (Volume:1), 11-14 july 2010, p. 408 - 412 (ISBN 978-1-4244-6526-2, DOI 10.1109/ICMLC.2010.5581029)
- (en) Kim Dong Seong, F. Machida et K.S. Trivedi, « Availability Modeling and Analysis of a Virtualized System », Dependable Computing, 2009. PRDC '09. 15th IEEE Pacific Rim International Symposium on, 16-18 nov. 2009, p. 365 - 371 (ISBN 978-0-7695-3849-5, DOI 10.1109/PRDC.2009.64)
- (en) Meng Yu, Alex Hai Wang, Wanyu Zang et Peng Liu, « Evaluating survivability and costs of three virtual machine based server architectures », Security and Cryptography (SECRYPT), Proceedings of the 2010 International Conference on, 26-28 july 2010, p. 1-8 (lire en ligne)
- (en) Nathan Regola et Jean Christophe Ducom, « Recommendations for Virtualization Technologies in High Performance Computing », Cloud Computing Technology and Science (CloudCom), 2010 IEEE Second International Conference on, nov. 30 2010-dec. 3 2010, p. 409 - 416 (ISBN 978-0-7695-4302-4, DOI 10.1109/CloudCom.2010.71)
- (en) Clark Scheffy, « Virtualization for dummies, AMD Special Edition », Wiley Publishing, Inc., (ISBN 9780470131565)
- (en) Benkemoun, « Etude de la virtualisation et du fonctionnement de la solution libre Xen », p. 37
- (en) Haikun Liu, Cheng-Zhong Xu, Hai Jin, Jiayu Gong et Xiaofei Liao, « Performance and Energy Modeling for Live Migration of Virtual Machines », HPDC '11 Proceedings of the 20th international symposium on High performance distributed computing, , p. 171-182 (ISBN 978-1-4503-0552-5, DOI 10.1145/1996130.1996154)
Voir Aussi
Liens externes
- Site institutionnel de l'ANSSI
- Site de l'ANSSI sur la sécurité informatique pour le grand public
- Site d'information de l'État français sur la sécurité informatique pour le grand public
- Les obligations de sécurité informatique qui existent en droit français, en particulier dans la réglementation des données personnelles