Codage de Shannon-Fano
Le codage de Shannon-Fano est un algorithme de compression de données sans perte élaboré par Robert Fano à partir d'une idée de Claude Shannon.
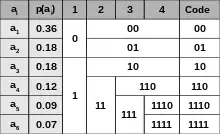
Il s'agit d'un codage entropique produisant un code préfixe très similaire à un code de Huffman, bien que pas toujours optimal, contrairement à ce dernier.
Principe
La probabilité de chaque symbole à compresser doit être connue. Dans la plupart des cas, des fréquences ou occurrences fixes calculées à partir des données à compresser sont utilisées ; on parle alors de codage de Shannon-Fano semi-adaptatif (qui nécessite deux passes successives sur les données à compresser : la première pour calculer les probabilités, la seconde pour compresser à proprement parler). Il est également possible d'utiliser des probabilités fixes non dépendantes des données à compresser (codage statique) ou des probabilités variant au fur et à mesure de la compression (codage adaptatif).
Le processus est de trier les symboles à compresser par ordre croissant de leurs nombre d’occurrences. Puis l'ensemble trié des symboles est séparé en deux groupes de telle façon que le nombre d'occurrences des deux parties soient égaux ou presque (le nombre d'occurrences d'un groupe étant égale à la somme des occurrences des différents symboles de ce groupe). On réitère le processus jusqu'à obtenir un seul arbre. On associe ensuite par exemple le code 0 à chaque embranchement partant vers la gauche et le code 1 vers la droite.
Comparaison avec le codage de Huffman
L'approche du codage de Shannon-Fano est descendante : l'algorithme part de l'ensemble des symboles et divise cet ensemble récursivement jusqu'à arriver à des parties ne contenant qu'un seul symbole. L'inconvénient de cette approche est que, lorsqu'il n'est pas possible de séparer un ensemble de symboles et deux sous-ensembles de probabilités à peu près égales (c'est-à-dire lorsque l'un des sous-ensembles est beaucoup plus probable que l'autre), les codes produits ne sont pas optimaux.
Le codage de Huffman a une approche ascendante : l'algorithme part des symboles et regroupe ceux ayant la probabilités la plus faible, jusqu'à avoir regroupé tous les symboles. Cette approche permet d'obtenir systématiquement un code optimal au niveau du symbole, dans le pire cas de la même longueur que le code de Shannon-Fano équivalent, dans tous les autres cas plus court.
Les codages de Shannon-Fano et de Huffman souffrent cependant tous les deux du même inconvénient : ils codent les symboles sur un nombre de bits entier. Un codage arithmétique, optimal au niveau du bit, permet de coder des symboles sur un nombre de bits arbitraire (y compris 0), et d'atteindre l'entropie de Shannon.
Utilisations
Comme le codage de Huffman est très similaire au codage de Shannon-Fano et donne de meilleurs résultats, ce dernier n'est pratiquement plus utilisé aujourd'hui.
Le codage de Shannon-Fano est utilisé après une compression par LZ77, pour le codage entropique de l'algorithme implode, utilisé historiquement dans le format ZIP[1]. L'algorithme implode a été détrôné par l'algorithme deflate, remplaçant le codage de Shannon-Fano par un codage de Huffman.
Voir aussi
Articles connexes
Bibliographie
- Claude Elwood Shannon, « A Mathematical Theory of Communication », Bell System Technical Journal, vol. 27, pp. 379-423, .
- Robert Mario Fano, « The transmission of information », Technical Report No. 65, 1949. Research Laboratory of Electronics, M.I.T., Cambridge, USA.
Références
- « PKZIP Data Compression Techniques », sur tylogix.com (consulté le ).