Classification sous contrainte
En intelligence artificielle, la classification sous contrainte désigne une famille d'algorithmes d'apprentissage semi-supervisée. Cette dernière occupe une place intermédiaire entre l'apprentissage supervisé (pour laquelle les étiquettes de classes sont connues) et l'apprentissage non-supervisé (où aucune étiquette de classe n'est fournie). Elle est de plus en plus usitée, en raison du besoin croissant d'automatiser des tâches requérant une expertise humaine.
Définition
Ces dernières années, l'intérêt porté sur l'incorporation de connaissances a priori dans des processus de classification, a pris de l'ampleur dans un nombre important d'applications telles que l'indexation et la recherche par le contenu, la segmentation d'images ou l'analyse de documents[1]. Cependant, un des problèmes les plus fréquemment traités par la classification sous contrainte, est la régionalisation : l'objectif est alors de trouver des groupes de régions géographiques similaires respectant certaines contraintes.
Dans la littérature, la majorité des auteurs traitent ces problèmes en adaptant des procédures de partitionnement classiques (par exemple, les algorithmes de classification hiérarchique) et/ou des procédures d'optimisation.
L'information contenue dans ces contraintes peut prendre plusieurs formes :
- information structurelle sur les données (contraintes globales),
- capacité minimum ou maximum des groupes d'objets (contraintes de groupes),
- règles heuristiques (contraintes d'attributs),
- étiquetage partiel et contraintes de comparaisons entre objets (contraintes d'objets).
Notations utilisées

On considère disposer d'un ensemble de données X structurée et constituée de N objets, chaque objet étant décrit par D attributs (ou caractéristiques). La formule utilisée dans les sections suivantes pour le calcul des distances entre objets est définie de la manière suivante :

Cette distance est donc égale à la norme du vecteur résultant de la soustraction de xi et xj, et peut s'écrire d(xi,xj) = dij.
Les différents types de contraintes
Ajout d'attributs de position
La façon la plus évidente d'ajouter une notion de localisation spatiale dans un ensemble de données, est d'ajouter des attributs de position pour chacun des objets. Par exemple, pour une image à deux dimensions, ces attributs peuvent être définis comme étant la ligne et la colonne de chaque pixel de l'image. La fonction d(xi,xj), calculant la distance entre deux objets, permet alors d'affecter un degré de similarité important aux pixels proches et un degré faible à ceux qui sont éloignés. L'avantage de cette méthode réside dans le fait qu'elle ne requiert pas de modification de l'algorithme de classification utilisé.
Duplication des voisins
On appelle voisin de xi, l'objet xj le plus proche de l'objet xi en termes de distance dij dans l'espace en D dimensions (avec i≠j). La technique de duplication proposée consiste en l'augmentation de la taille du vecteur attributs d'un objet en ajoutant un ou plusieurs ensembles d'attributs selon le nombre de voisins considéré (cf. recherche des plus proches voisins). En effet, on affecte à chaque objet, un duplicata des caractéristiques de chacun de ses voisins (au sens de la distance calculée)[2].
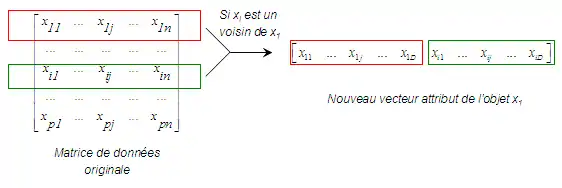
Cependant, il est aisé de voir que cette approche est souvent impraticable car elle engendre une augmentation importante de la dimension des données et donc un coût non négligeable aussi bien en termes de temps de calcul qu'en termes d'espace mémoire nécessaire à l'exécution des algorithmes de classification utilisés.
Modification du calcul de distance
Contrairement aux méthodes précédentes qui modifient l'ensemble des données (et plus particulièrement, le vecteur attribut de chaque objet par ajout de nouveaux attributs), certaines méthodes permettent d'intégrer des contraintes de manière moins directe. En effet, il est possible d'incorporer des informations spatiales en modifiant la manière de calculer la distance entre deux objets. Cette approche consiste à modifier la distance originale séparant deux objets par une fonction non-linéaire (une des fonctions les plus souvent utilisées dans la littérature est la fonction exponentielle).
![\mathrm{d_{ij}}^* = d_{ij} [1-exp({{-u_{ij}} \over {W}})]](https://img.franco.wiki/i/bdb281aeb0a31219a992e94f6e3aeeecec107de3.svg)
avec dij* représentant la distance modifiée incorporant l'information spatiale (grâce au voisinage de xi et xj), dij étant la distance originale entre les deux objets, uij s'exprimant comme une mesure de distance égale au ratio des distances moyennes des voisins de chacun des objets xi et xj, et enfin W étant un poids (de valeur arbitraire ou fixée par l'utilisateur).
Cette méthode permet donc d'associer les caractéristiques des objets aux connaissances a priori afin d'obtenir une unique source d'information. L'objectif est alors de trouver des groupes d'objets de compacité équitable et homogènes.
Modification de la fonction objectif
La dernière catégorie de méthodes intégrant des contraintes globales, et plus particulièrement des informations de voisinage, est celle modifiant la fonction objectif (et donc le critère à optimiser) d'un algorithme de classification quelconque, utilisant une procédure d'optimisation. Afin de prendre en compte les contraintes définies, il est nécessaire de remplacer cette fonction par une somme pondérée de la fonction originale avec l'information de voisinage à disposition.
De manière générale, l'optimisation de la compacité (ou variance) et de la contiguïté des groupes d'objets, nécessite la spécification de l'importance relative des deux objectifs via un paramètre de pondération λ :

ou encore :

avec foriginal* la nouvelle fonction objectif (données originales et contraintes), foriginal la fonction originale (données originales) et fcontraintes la fonction à optimiser pour l'information a priori (contraintes).
Contraintes de groupes
La connaissance à disposition peut également être fournie sous la forme d'information sur les groupes d'objets. Ces contraintes permettent de définir des exigences sur la forme globale, l'orientation ou d'autres caractéristiques des groupes. La capacité minimum ou maximum de ces derniers semble être la caractéristique la plus utilisée dans la littérature :
- Contraintes de capacité minimum : des méthodes permettant d'utiliser des contraintes sur des groupes d'objets ont été développées récemment[3], afin d'éviter d'obtenir des solutions contenant des groupes vides (solution obtenue en particulier, pour l'algorithme des k-moyennes appliqué à des données de dimensions importantes ou lorsque le nombre de groupes défini est grand). Cette approche impose des contraintes sur la structure des groupes. En effet, il est alors possible de spécifier un nombre minimum d'objets pour chaque groupe.
- Contraintes de capacité maximum : afin d'essayer de faire respecter ce genre de contraintes, il est souvent pratique d'utiliser un algorithme de classification non-supervisée du type regroupement hiérarchique. En effet, à partir de la hiérarchie créée, il est possible de sélectionner des groupes d'objets adaptés permettant de faire respecter la contrainte définie.
Contraintes d'attributs
La connaissance a priori peut également être interprétée comme de l'information dépendante des caractéristiques des objets. Ces contraintes permettent d'orienter la classification des objets selon leurs valeurs pour un attribut donné. Un algorithme de classification hiérarchique contraint et incorporant des contraintes d'attributs a été développé en 1998[4] par Bejar et Cortes.
Contraintes d'objets
Les contraintes d'objets définissent des restrictions sur des paires individuelles d'objets. Ce type de connaissance a priori sur les données est généralement fournie sous trois formes :
- les étiquettes de classes,
- le retour d'information,
- les contraintes de comparaison par paires d'objets.
Étiquetage partiel
L'étiquetage des objets d'un ensemble de grande dimensions représente une tâche difficile et coûteuse en temps ce qui la rend souvent infaisable. En revanche, il est possible d'étiqueter un sous-ensemble ne contenant que quelques objets. Cette nouvelle source d'information peut alors être utilisée de deux façons différentes :
- identification des groupes obtenus : après avoir appliqué un algorithme de classification non-supervisée, les groupes d'objets obtenus peuvent être identifiés grâce au sous-ensemble d'objets étiquetés au préalable[5]. Pour cela, l'utilisation de règles simples est requise. Parmi ces dernières, le vote majoritaire semble être une bonne alternative puisqu'il permet d'affecter une identité (ou une étiquette) à chaque groupe obtenu,
- initialisation intelligente des algorithmes de partitionnement utilisés : L'initialisation de certains algorithmes de classification non-supervisée est une étape importante et peut se révéler cruciale dans la validation et l'interprétation des résultats de partitionnement obtenus[6]. C'est pourquoi, il semble intéressant d'utiliser l'information contenue dans ces étiquettes de classes afin d'orienter le choix des paramètres initiaux.
Retour d'information
Les systèmes de classification interactifs adoptent une approche itérative, dans lesquels le système produit une partition des données puis la présente à un expert afin de l'évaluer et la valider. Cet expert peut alors indiquer clairement les erreurs de partitionnement (induits par le système), puis cette information peut être utilisée lors de l'itération suivante de l'algorithme. Cependant, le désavantage de cette méthode réside dans le fait qu'un expert peut se retrouver en difficulté lors de la validation des résultats si l'ensemble des données est de dimensions importantes.
Relation entre paires d'objets
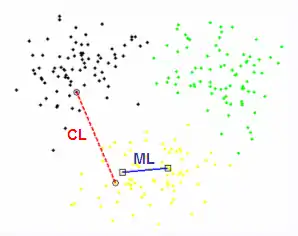
Si l'étiquetage des objets se révèle être une tâche longue et complexe, les contraintes par paires, attestant simplement que deux objets doivent être dans la même classe (Must-Link) ou non (Cannot-Link), sont par contre plus aisées à recueillir auprès d'experts[7]. De plus, cette manière de représenter l'information relationnelle est souvent considérée comme la plus générale, de par le fait qu'elle puisse reprendre une grande partie des contraintes précédemment citées. En effet, les contraintes globales ainsi que les contraintes d'attributs peuvent facilement se mettre sous la forme de contraintes de paires d'objets. Ces contraintes relationnelles peuvent être rangées dans deux catégories :
- les contraintes dures : elles se doivent d'être respectées dans la partition en sortie de l'algorithme,
- les contraintes souples : elles peuvent être ou ne pas être respectées dans la partition en sortie de l'algorithme (elles sont considérées comme des "préférences").
| 1re contrainte | 2de contrainte | Contrainte dérivée |
|---|---|---|
| ML(xi,xj) | ML(xj,xk) | ML(xi,xk) |
| ML(xi,xj) | CL(xj,xk) | CL(xi,xk) |
| CL(xi,xj) | ML(xj,xk) | CL(xi,xk) |
| CL(xi,xj) | CL(xj,xk) | ??? |
Comme démontré dans ce tableau, les contraintes de comparaison Must-Link définissant une relation d'équivalence entre objets, sont transitives, alors que les contraintes Cannot-Link sont bien symétriques mais non transitives. En effet, il est impossible de prédire la relation liant deux objets xi et xk, sachant que les paires de points (xi,xj) et (xj,xk) sont liées par deux contraintes Cannot-Link indépendantes.
Exemples d'algorithmes de classification sous contrainte
- COP-KMEANS (Algorithme des K-moyennes modifié pour prendre en compte des contraintes de comparaison entre paires d'objets),
- COP-COBWEB[8] (Algorithme COBWEB modifié et prenant en compte des contraintes de comparaison entre paires d'objets),
- Apprentissage spectral[9] (Algorithme de classification spectrale avec modification des valeurs d'une matrice de similarités : Sij = 1 si ML(xi,xj) (les objets xi et xj sont appariés en Must-Link) et Sij = 0 si CL(xi,xj)) (les objets xi et xj sont appariés en Cannot-Link).l* Classification spectrale contrainte flexible[10] (Formalisation Lagrangienne du problème d'optimisation du critère de classification spectrale et résolution par un système de valeurs propres généralisées).
Voir aussi
Notes et références
- « Han J., Kamber M., Data Mining: Concepts and Techniques. Morgan Kaufmann Publishers, 3rd Edition, 2006»
- « Roberts S., Gisler G., Theiler J., Spatio-spectral image analysis using classical and neural algorithms. In Dagli C.H., Akay M., Chen C.L.P., Fernandez B.R., Ghosh J. editors, Smart Engineering Systems: Neural Networks, Fuzzy Logic and Evolutionary Programming, vol. 6 of Intelligent Engineering Systems Through Artificial Neural Networks, p. 425-430, 1996»
- « Bradley P.S., Bennett K.P., Demiriz A., Constrained k-means clustering. Technical Report MSR-TR-2000-65, Microsoft Research, Redmond, WA. »
- « Bejar J., Cortes U., Experiments with domain knowledge in unsupervised learning: using and revising theories. Computacion y Sistemas, vol. 1(3), p. 136-143, 1998»
- « Demiriz A., Bennett K.P., Embrechts M.J., Semi-Supervised Clustering using Genetic Algorithms. Proceedings of Artificial Neural Networks in Engineering, 1999»
- « Basu S., Bannerjee A., Mooney R., Semi-Supervised Clustering by Seeding. Proceedings of the Nineteenth International Conference on Machine Learning, 2002»
- « Wagstaff K., CardieC., Clustering with Instance-level Constraints. International Conference on Machine Learning, p. 1103-1110, 2000»
- « Wagstaff K., Cardie C., Clustering with Instance-level Constraints. Proceedings of the 17th International Conference on Machine Learning, p. 1103-1110, 2000»
- « Kamvar S., Klein D., Manning C., Spectral Learning. 18th International Joint Conference on Artificial Intelligence, p. 561-566, 2003»
- « Wang X., Davidson I., Flexible constrained spectral clustering. 16th International Conference on Knowledge Discovery and Data Mining, p. 563-572, 2010»