Arbre syntaxique
En linguistique
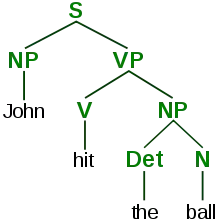
En linguistique, l'arbre syntaxique représente la structure syntaxique d'une phrase. Le nombre de catégories morphosyntaxiques correspondent à des classes distributionnelles, c'est-à-dire à la place qu'elles occupent dans la phrase, sur l'axe syntagmatique. En fonction de son voisinage, chaque élément peut commuter avec un autre élément de même catégorie. Les catégories morphosyntaxiques de la phrase sont : le déterminant, le nom, le pronom, le verbe, l'adjectif, l'adverbe, la préposition, la conjonction et l'interjection. En français, on identifie généralement la phrase par la lettre P (remplaçant le S de sentence dans l'exemple visuel ci-contre).
Dans les approches de type grammaire de dépendance, à la suite de Lucien Tesnière, on parle plutôt de stemma.
En informatique
En compilation, l'arbre syntaxique abstrait représente la structure syntaxique d'un code source. En effet, l'analyse syntaxique crée un arbre syntaxique avec beaucoup de nœuds qui n'auront pas d'utilité lors de la compilation et qu'il faut simplifier[1].
L'arbre syntaxique abstrait est, en fait, produit après les analyses syntaxique et sémantique, par la suppression d'éléments inutiles pour la génération du code (avec des contrôles sémantiques[2]). C'est sur cet arbre de syntaxe abstraite, auquel on a ajouté une analyse sémantique, que l'on s'appuyera lors de la compilation.
Voir aussi
Articles connexes
Liens externes
- Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman, Compilers: Principles, Techniques, and Tools, Addison Wesley Publishing Company, 1986