Arbre des suffixes
En informatique, un arbre des suffixes (en anglais suffix tree) est une structure de données arborescente contenant tous les suffixes d'un texte. L'arbre des suffixes est utilisé pour l'indexation de textes et la recherche de motifs, notamment en bio-informatique.
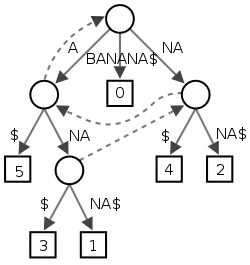
BANANA terminé par $. Les six chemins de la racine à une feuille (représentée par une boîte) correspondent aux six suffixes A$, NA$, ANA$, NANA$, ANANA$ et BANANA$. Les nombres dans les boîtes donnent la position de départ du suffixe correspondant. En pointillés sont dessinés les liens suffixes.Définition
On suppose que l'on s’intéresse à un texte, au sens informatique, c'est-à-dire une suite de caractères. Un suffixe est une partie du texte : la suite des caractères entre une certaine position et la fin du texte. L'arbre des suffixes est une structure pour stocker un ensemble de suffixes.
L'arbre a les propriétés suivantes :
- Les feuilles de l'arbre contiennent un numéro qui correspond à la position de début du suffixe dans le texte.
- Les branches peuvent être étiquetées de différentes manières :
- par une chaîne de caractères de longueur supérieure ou égale à 1,
- par un couple qui correspond à la sous-chaîne commençant à la position , de longueur , dans le texte.



En général, on termine le texte par un caractère spécial $ (non présent dans le reste du texte), pour éviter que certains suffixes se terminent sur des nœuds de l'arbre.
On peut parler d'arbre compact des suffixes, si :
- chaque nœud a au moins deux fils,
- toutes les étiquettes des branches sortant d'un même nœud commencent par une lettre différente.
Utilisations
L'arbre des suffixes est une structure assez naturelle et peut être utilisée pour résoudre un grand nombre de problèmes en temps linéaire. L'un des problèmes les plus classiques est la recherche de motifs.
Recherche de motifs
L'arbre des suffixes est très utilisé comme structure d'indexation. En effet, il permet, de rechercher un motif M, de longueur , dans un texte de longueur en temps . Ainsi, la recherche prend un temps qui dépend uniquement de la longueur du motif.



La recherche de motifs est relativement simple. En partant de la racine de l'arbre, il faut suivre la branche dont l'étiquette commence comme M. En suivant cette branche on arrive alors à un nouveau nœud et on recommence le processus sur la partie restante de M. Le processus est répété jusqu'à :
- ne plus pouvoir descendre dans l'arbre par la lettre lue, il n'y a pas d'occurrence de M dans le texte,
- avoir lu M en entier, on arrive
- sur un nœud de l'arbre ou au milieu d'une branche. Le nombre de feuilles présentes dans le sous arbre correspond au nombre d'occurrences de M dans le texte. De plus chaque feuille contenant la position du début de suffixe, on peut déterminer la position de chacune des occurrences.
- sur une feuille. Il n'y a qu'une seule occurrence de M dans le texte, elle se trouve à la position indiquée par le numéro de la feuille.
Détection de répétitions
Considérons un arbre compact des suffixes. Lorsqu'il y a un nœud, il a au moins deux fils. Cela signifie que la chaîne de caractères qui nous a mené à ce nœud est répétée au moins deux fois dans le texte. Ainsi, en considérant tous les nœuds de l'arbre on peut connaître toutes les répétitions dans le texte.
Autres
Diverses autres tâches, comme détecter des palindromes, peuvent être effectuées rapidement grâce à l'arbre des suffixes en utilisant des algorithmes de plus petit ancêtre commun.
Construction
Les principaux algorithmes de construction de l'arbre des suffixes sont ceux de Weiner (Weiner 1973), McCreight (McCreight 1976) et Ukkonen (Ukkonen 1995). Ces trois algorithmes ont une complexité en temps linéaire. Asymptotiquement en moyenne, ces algorithmes nécessitent un espace en (en pratique de l'ordre de 12n). L'algorithme d'Ukkonen a l'avantage d'être online.

L'espace utilisé par une telle méthode peut être un problème pour indexer des textes très longs (centaines de Mo à quelques Go). D'autres méthodes existent afin de réduire l'espace mémoire nécessaire aux structures d'indexation. La table des suffixes en est un exemple, bien que l'espace requis puisse être trop important (de l'ordre de 4n).
L'algorithme de Farach-Colton, Ferragina et Muthukrishnan 2000, prend comme mesure de complexité le nombre d'appels à une mémoire externe, et est optimal selon ce point de vue.
Voir aussi
Bibliographie
Articles
- (en) Edward M. McCreight, « A Space-Economical Suffix Tree Construction Algorithm », Journal of the ACM, vol. 23, no 2, , p. 262--272 (lire en ligne)
- (en) Esko Ukkonen, « On-line construction of suffix trees », Algorithmica, vol. 14, no 3, , p. 249--260 (lire en ligne)
- (en) P. Weiner, « Linear pattern matching algorithms », dans 14th Annual IEEE Symposium on Switching and Automata Theory, (DOI 10.1109/SWAT.1973.13), p. 1-11.
- Martin Farach-Colton, Paolo Ferragina et S. Muthukrishnan, « On the sorting-complexity of suffix tree construction. », Journal of the ACM, vol. 47, no 6, , p. 987-1011 (DOI 10.1145/355541.355547).
Ouvrages
- (en) Dan Gusfield, Algorithms on Strings, Trees and Sequences : Computer Science and Computational Biology, Cambridge, Cambridge University Press, , 534 p. (ISBN 978-0-521-58519-4, BNF 37532677).
Notes et références
Liens externes
- Construction d'arbres de suffixes Introduction à la construction et à l'utilisation d'arbres de suffixes, présentation et comparaison des algorithmes de Ukkonen et de Hunt avec l'approche TDD.
- Présentation générale et approfondie des arbres des suffixes. Université de Montréal.