On appelle également algorithme de McNaughton et Yamada un autre algorithme, donné dans le même article[1], qui permet de construire un automate sans epsilon transitions à partir d'une expression régulière.
Principe
Étant donné un automate à n états, et dont les états sont numérotés de 1 à n, on donne une expression pour les langages composés des mots qui étiquettent les chemins de i à j, pour tout couple i, j. Cette expression est construite par récurrence au moyen d'une condition sur les chemins ; cette condition stipule que les chemins ne passent que par certains états autorisés. À chaque itération de l’algorithme, on fixe un nouvel état par lequel on s’autorise à passer. À la fin de l’algorithme, on obtient alors tous les chemins possibles.
Le fonctionnement de cet algorithme rappelle alors l’algorithme de Floyd-Warshall sur les graphes, où à chaque nouvelle étape, on s’autorise à passer par un nouveau sommet fixé.
Description
Soit un automate fini sur un alphabet, donné par un ensemble fini d'états , un ensemble de transitions, et des ensembles d'états initiaux respectivement terminaux.
On note l'ensemble des mots qui sont étiquettes de chemins de à . Le langage reconnu par l'automate est l'ensemble
L'algorithme de McNaugthon et Yamada est une méthode pour calculer des expressions régulières pour les .
On note l'expression pour l’ensemble des mots qui étiquettent des chemins de à et dont tous les sommets intermédiaires sont inférieurs ou égaux à . Les sommets de départ et d’arrivée ne sont pas intermédiaires, donc ils ne sont pas soumis à la contrainte d’être inférieurs ou égaux à .
On construit les par récurrence sur , en commençant avec , et en terminant avec . Lorsque , la contrainte sur n’est plus une restriction, et si , et .
Pour , comme les sommets sont numérotés à partir de 1, la contrainte exprime simplement qu’il n’y a pas de sommet intermédiaire. Les seuls chemins sont des transitions de à (on ignore un chemin de longueur 0 en un état ).
On a donc
Pour la récurrence, on considère un chemin de à dont les sommets intermédiaires sont plus petits que . Deux cas sont alors possibles :
les sommets intermédiaires sont plus petits que ; alors l’étiquette est dans ;
le chemin passe par l’état . On décompose alors le chemin en parties dont les sommets intermédiaires sont plus petits que . Pour cela, on considère chaque occurrence du sommet dans ce chemin : entre deux occurrences consécutives, les sommets intermédiaires sont plus petits que k-1. On a alors la formule
.
Il y a donc étapes (). Chacune des étapes demande le calcul de expressions, et la taille des expressions elles-mêmes croît avec . S’il est facilement programmable, l’algorithme est assez pénible à la main. Il est alors utile d’utiliser les règles qui permettent de simplifier des expressions régulières.
Pseudo-code
On va représenter les (respectivement ) sous forme de matrices, dont le coefficient en est (respectivement ).
On a alors, pour un automate fini à états sur l'alphabet :
Fonction McNaughton-Yamada()
\\à l'itération k de la boucle for, cette matrice représente fortofortoforto
R := \\expression rationnelle à retourner
for:
for:
if then
R := R + + \\on n'ajoute qu'aux où
else
R := R +
retourner R
Fin Fonction
Exemples
Un premier exemple
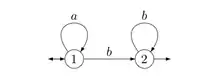
L'automate considéré.
Appliquons l'algorithme de McNaughton et Yamada à l'automate représenté.
On va utiliser la représentation matricielle introduite dans la partie précédente. On a :
;
;
.
D'où .
Le langage reconnu par est alors dénoté par l'expression rationnelle . Après simplifications, on a , ce qui est bien le résultat attendu.
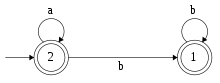
L'automate , avec les états numérotés dans l'ordre inverse.
Considérons maintenant le même automate, mais avec une numérotation différente des états.
L'algorithme appliqué à cet automate donne :
D'où .
est alors dénoté par , soit exactement la même expression rationnelle que précédemment : pour cet exemple particulier, le choix du nouvel état autorisé à chaque étape ne change pas l'expression rationnelle obtenue en fin d'algorithme.
Un deuxième exemple, où la numérotation des états change le résultat
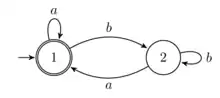
L'automate .
Donnons maintenant l'exemple présenté dans l'ouvrage de référence de Sakarovitch[2]. Appliquons maintenant l'algorithme à l'automate .
On a :
.
D'où .
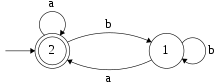
L'automate , avec les états numérotés dans l'ordre inverse.
De même que pour le premier exemple, appliquons à nouveau l'algorithme en changeant la numérotation des états.
On a :
.
D'où : l'expression rationnelle obtenue pour le même langage est différente.
(en) Jacques Sakarovitch, Elements of automata theory, Cambridge, Cambridge University Press, , 782 p. (ISBN978-0-521-84425-3, BNF42078268), p.96
Bibliographie
(en) Robert McNaughton et Hisao Yamada, « Regular expressions and state graphs for automata », IRE Trans. Electronic Computers, vol. EC-9, no 1, , p. 39-47 (DOI10.1109/TEC.1960.5221603).
(en) John E. Hopcroft, Rajeev Motwani et Jeffrey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Pearson Addison Wesley, , 3e éd., xvii+535 (ISBN978-0-321-45536-9 et 0201441241)— Section 3.2.1 From DFA’s to Regular Expressions, p. 93-98.
(en) Jacques Sakarovitch, Elements of automata theory, Cambridge University Press, , 782 p. (ISBN978-0521844253), p. 96