Étoile (modèle de données)
Un schéma en étoile, ou modèle de données « en étoile », est une structure multidimensionnelle stockant des données atomiques ou agrégées, typiquement dans des datawarehouse ou datamart. Souvent considéré (à tort) comme un modèle dénormalisé[1], le modèle en étoile permet une économie de jointures à l'interrogation, ce qui le rend optimisé pour les requêtes d'analyse.
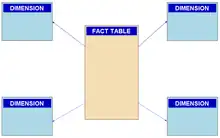
Le modèle en étoile est implémenté sur un SGBD relationnel classique tel que Oracle, IBM DB2, SQL Server, Teradata, MySQL ou encore PostgreSQL. Il existe une variante, le modèle en flocon.
Un ensemble d'étoiles ou de flocons dans lequel les tables de faits se partagent certaines tables de dimensions forme un modèle « en constellation ».
Faits et dimensions
Un modèle en étoile est constitué d'une table centrale, dite table des faits, et de nombreuses tables dimensionnelles autour[1].
La table située au centre de l'étoile, table des faits ou mesures (ou encore métriques), contient les éléments mesurés dans l'analyse comme les montants, les quantités, les taux, etc.
Les tables situées aux extrémités de l'étoile, tables de dimensions, ou encore axes d'analyse ; niveaux de suivi) sont les dimensions explorées dans l'analyse comme le temps (jour, mois, période, etc.), la nomenclature des produits (référence, famille, etc.), la segmentation clientèle (tranche d'âge, marché, etc.), etc.
Le principe d'optimisation de ce modèle en étoile est le suivant : une clé calculée « technique » (clé générique) sert de jointure relationnelle entre les tables de dimensions et la table des faits. La requête SQL réalise d'abord sa sélection sur les tables de dimensions (peu volumineuses) et ensuite seulement, à partir des clés ainsi sélectionnées, la jointure avec la volumineuse table des faits.
Schéma en flocon
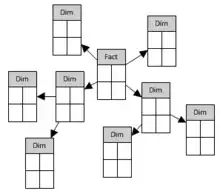
Le modèle de données dit « en flocons » est une variante du modèle en étoile : chaque table de dimension est re-normalisée pour faire apparaître la hiérarchie sous-jacente (nomenclature, etc.). La normalisation n'est pas indispensable car ni mises à jour ni suppressions ne sont effectuées directement sur l'entrepôt de données. L'intérêt principal du modèle en flocons réside dans le gain en espace de stockage qui est de l'ordre de 5 à 10 %.
Notes et références
- Corr et Stagnitto 2013, p. 8.
Annexes
- [Corr et Stagnitto 2013] (en) Lawrence Corr et Jim Stagnitto, Agile Data Warehouse Design : Collaborative Dimensional Modeling, from Whiteboard to Star Schema, DecisionOne Press, , 328 p. (ISBN 978-0-9568172-0-4)