Unité récurrente fermée
Les unités récurrentes fermées (GRU) sont un système de porte dans les réseaux de neurones récurrents, introduit en 2014 par Kyunghyun Cho et al[1]. Le GRU est comme une longue mémoire à court terme (LSTM) avec une porte d'oubli[2], mais a moins de paramètres que LSTM, car il n'a pas de porte de sortie[3]. Les performances de GRU sur certaines tâches de modélisation de musique polyphonique, de modélisation de signaux vocaux et de traitement du langage naturel se sont avérées similaires à celles de LSTM[4] - [5]. Les GRU ont montré que le déclenchement est en effet utile en général et l'équipe de Bengio a conclu qu'aucune conclusion concrète sur laquelle des deux unités de déclenchement était la meilleure.
Architecture
Il existe plusieurs variantes de l'unité récurrente fermée dans lesquels l'unité est activé en utilisant diverses combinaisons de l'état caché et du biais précédent, ainsi une forme simplifiée appelée unité fermée minimale.
Unité entièrement fermée
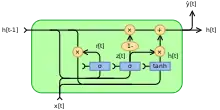
Au départ, pour , le vecteur de sortie est .



variables
- : vecteur d'entrée
- : vecteur de sortie
- : vecteur d'activation candidat
- : mise à jour du vecteur de porte
- : réinitialiser le vecteur de porte
- , et : matrices de paramètres et vecteur








- : L'original est une fonction sigmoïde.
- : L'original est une tangente hyperbolique.


Des fonctions d'activation alternatives sont possibles, à condition que .
![{\displaystyle \sigma _{g}(x)\in [0,1]}](https://img.franco.wiki/i/a8f89ffab2458ee612dd596a937f8e001c66d689.svg)
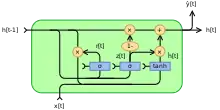
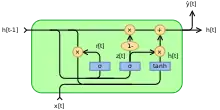
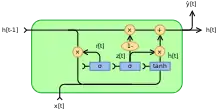
Des formes alternatives peuvent être créés en modifiant et
- Type 1, chaque porte ne dépend que de l'état caché précédent et du biais.
- Type 2, chaque porte ne dépend que de l'état caché précédent.
- Type 3, chaque porte est calculée en utilisant uniquement le biais.



Unité fermée minimale
L'unité fermée minimale est similaire à l'unité entièrement fermée, mais le vecteur d’activation de la porte de mise à jour et de la réinitialisation sont fusionné dans une porte d'oublie. Cela implique également que l'équation du vecteur de sortie doit être modifiée :

variables
- : vecteur d'entrée
- : vecteur de sortie
- : vecteur d'activation candidat
- : oublier le vecteur
- , et : matrices de paramètres et vecteur

Cadre de recommandation d'algorithme d'apprentissage
Un cadre de recommandation d'algorithme d'apprentissage peut aider à guider la sélection de l'algorithme d'apprentissage et de la discipline scientifique (par exemple RNN, GAN, RL, CNN,. . . ). Le cadre a l'avantage d'avoir été généré à partir d'une analyse approfondie de la littérature et dédié aux réseaux de neurones récurrents et à leurs variations[6].
Références
- (en) Kyunghyun Cho, Bart van Merrienboer, DZmitry Bahdanau et Fethi Bougares, « Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation », dans 1724–1734, (DOI 10.48550/arXiv.1406.1078, arXiv 1406.1078).
- Felix Gers, Jürgen Schmidhuber et Fred Cummins, « Learning to Forget: Continual Prediction with LSTM », Proc. ICANN'99, IEE, London, vol. 1999, , p. 850–855 (ISBN 0-85296-721-7, DOI 10.1049/cp:19991218, lire en ligne)
- « Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano – WildML » [archive du ], (consulté le )
- Ravanelli, Brakel, Omologo et Bengio, « Light Gated Recurrent Units for Speech Recognition », IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 2, no 2, , p. 92–102 (DOI 10.1109/TETCI.2017.2762739, arXiv 1803.10225, S2CID 4402991)
- Su et Kuo, « On extended long short-term memory and dependent bidirectional recurrent neural network », Neurocomputing, vol. 356, , p. 151–161 (DOI 10.1016/j.neucom.2019.04.044, arXiv 1803.01686, S2CID 3675055)
- Feltus, « Learning Algorithm Recommendation Framework for IS and CPS Security: Analysis of the RNN, LSTM, and GRU Contributions », IGI International Journal of Systems and Software Security and Protection (IJSSSP), vol. 13, no 1, (DOI 10.4018/IJSSSP.293236, S2CID 247143453)