Espace de versions
Un espace de versions est un dispositif utilisé en apprentissage supervisé pour induire des concepts généraux ou des règles à partir d'un ensemble mêlant des exemples vérifiant la règle qu'on cherche à établir et des contre-exemples ne la vérifiant pas. L'espace de versions au sens restreint est l'ensemble des hypothèses cohérentes avec le jeu d'exemples. La technique des espaces de versions a été proposée pour la première fois par Tom Mitchell en 1978.
Historique
La notion des espaces de version a été introduite par Tom Mitchell dans le contexte de son travail sur le programme Meta-Dendral, un système expert dont le but était de reconnaître des composants chimiques à partir de spectrométrie de masse. Le système devait pouvoir déduire seul des règles sur les spectromètres qui lui permettent de déterminer l'élément chimique en question. À l'époque, la méthode la plus courante était la recherche dans l'espace des hypothèses : partir d'une hypothèse collant au premier exemple, puis la modifier en ajoutant des exemples au fur et à mesure pour tenter de la faire correspondre. Cependant il n'était pas toujours trivial de trouver des règles de modifications d'hypothèses, et il était parfois nécessaire de retourner en arrière (dans le cas où aucune modification de la règle courante ne fonctionne). Tom Mitchell a proposé une méthode systématique ne nécessitant pas de retour en arrière, même s'il faut toujours définir un espace d'hypothèses et des règles de modification (dans ce cas des règles de généralisation et de spécialisation).
Bien que le principe d'élimination de candidats ne soit pas une méthode populaire d'apprentissage, en raison notamment de sa grande sensibilité au bruit (Russell & Norvig 2002)), certaines applications pratiques ont été développées (Sverdlik & Reynolds 1992, Hong & Tsang 1997, Dubois & Quafafou 2002).
Concept
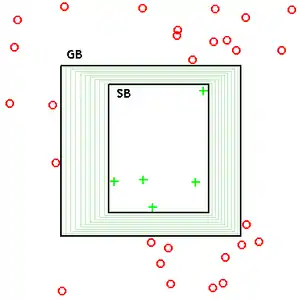
La technique des espaces de versions sert à déterminer, dans un espace d'hypothèses, lesquelles peuvent correspondre à un ensemble d'exemples pris dans l'espace des données. Il faut donc commencer par définir l'espace des hypothèses. Cet espace est généralement choisi par les experts. Idéalement, il doit comporter le concept cible, mais ce n'est pas toujours le cas, et il peut être volontairement simplifié pour ne pas trop compliquer l'algorithme. S'il est trop simplifié, il y a le risque qu'au final aucune hypothèse ne satisfasse l'ensemble d'exemples. Par exemple, pour classer des points en 2D, on peut prendre comme hypothèses les rectangles.
L'espace des versions est l'ensemble des hypothèses qui sont cohérentes avec le jeu d'exemples. Son cardinal peut être très grand, voire infini. L'algorithme ne peut donc pas garder en mémoire l'ensemble de toutes les hypothèses valides. Toutefois, l'espace des hypothèses est partiellement ordonné : si le sous-ensemble de l'espace des données classé positivement par une hypothèse H1 est inclus dans le sous-ensemble de l'espace des données classé positivement par H2, alors H1 est plus spécifique que H2, ou encore, H2 est plus général que H1. Cet espace peut donc être représenté par ses bornes : le G-set, l'ensemble des hypothèses les plus générales qui sont cohérentes avec les exemples connus, et le S-set, l'ensemble des hypothèses les plus spécifiques qui sont cohérentes avec les exemples connus.
La méthode consiste ensuite en une élimination des candidats, par mise à jour de cet espace des versions lors d'ajouts successifs d'exemples. Il faut pour cela des règles de généralisation, lorsqu'un élément du S-set ne classe pas correctement un exemple positif, et de spécialisation lorsqu'un algorithme du G-set ne classe pas correctement un exemple négatif.
Idéalement, l'espace de versions doit converger vers une unique hypothèse. Ceci n'est bien sûr possible que si le concept cible appartient à l'espace des hypothèses.
Algorithme
L'algorithme de mise à jour de l'espace des versions est le suivant :
- Remonter le premier exemple positif
- Initialiser S à l'ensemble des hypothèses du premier cas
- Initialiser G à l'ensemble des hypothèses les plus générales
- Répéter pour chaque nouvel exemple
- Mettre à jour S :
- Si est négatif
- Éliminer les hypothèses de S couvrant
- Si est positif
- Généraliser juste assez les hypothèses de S ne couvrant pas pour qu'elles couvrent
- Éliminer les hypothèses de S qui couvrent maintenant des exemples négatifs ou qui sont plus générales que d'autres hypothèses de S
- Si est négatif
- Mettre à jour G :
- Si est négatif
- Spécialiser juste assez les hypothèses de G couvrant pour qu'elles ne couvrent plus
- Éliminer les hypothèses de G qui ne couvrent plus des exemples positifs ou qui sont plus spécifiques que d'autres hypothèses de G
- Si est positif
- Éliminer les hypothèses de G ne couvrant pas
- Si est négatif
- Mettre à jour S :

Exemple
Dans cet exemple, on cherche à déterminer les sports qu'une personne aime regarder. Les paramètres sont le sport, le type (équipe/individuel), le lieu (intérieur/extérieur), le niveau (national/mondial) et le jour. Un exemple est donc un quintuplet, par exemple (football, équipe, extérieur, national, dimanche).
On choisit un espace des hypothèses simples : une hypothèse est une conjonction d'hypothèses sur chaque paramètre. Une hypothèse sur un paramètre impose soit une valeur précise (par exemple « national » pour le paramètre « niveau »), soit n'impose aucune valeur (toutes les valeurs sont bonnes), ce que l'on note avec un point d'interrogation. Dans cet exemple simple on n'autorise pas les disjonctions (par exemple « il fait beau ou nuageux »). Exemple d'hypothèse qui n'accepte que les sports d'équipe : (?, équipe, ?, ?, ?).
Étape 1 Exemple positif : (football, équipe, extérieur, national, samedi)


Étape 2 Exemple positif : (hockey, equipe, extérieur, national, samedi) L'hypothèse du S-set ne couvre pas cet exemple, on doit donc la généraliser.

Les hypothèses du G-set couvrent cet exemple, il n'y a donc rien à modifier.

Étape 3 Exemple négatif : (gymnastique, individuel, intérieur, mondial, samedi) Les hypothèses du S-set ne couvrent pas cet exemple, il n'y a donc rien à modifier.

Il faut spécialiser l'hypothèse du G-set pour ne plus inclure cet exemple. Il y a plusieurs solutions possibles, elles sont toutes ajoutées au G-set.

Étape 4 Exemple positif : (handball, equipe, intérieur, national, samedi) L'hypothèse du S-set ne couvre pas cet exemple, on doit donc la généraliser.

Une hypothèse du G-set ne couvre pas cet exemple et doit être éliminée.

Étape 5 Exemple négatif : (décathlon, individuel, extérieur, mondial, dimanche) Les hypothèses du S-set ne couvrent pas cet exemple, il n'y a donc rien à modifier.

Les hypothèses du G-set ne couvrent pas cet exemple, il n'y a donc rien à modifier.

Dans ce cas nous n'avons pas assez d'exemples pour arriver à une convergence.
Références
- Vincent Dubois, Quafafou, Mohamed « Concept learning with approximation: Rough version spaces » ()
— « (ibid.) », dans Rough Sets and Current Trends in Computing: Proceedings of the Third International Conference, RSCTC 2002, Malvern, Pennsylvania, p. 239–246 - (en) Tzung-Pai Hong, « A generalized version space learning algorithm for noisy and uncertain data », IEEE Transactions on Knowledge and Data Engineering, vol. 9, no 2, , p. 336–340 (DOI 10.1109/69.591457)
- (en) John Stuart Mill, A System of Logic, Ratiocinative and Inductive: Being a Connected View of the Principles of Evidence and the Methods of Scientific Investigation, Honolulu, HI, University Press of the Pacific, 1843/2002
- (en) Tom M. Mitchell, Machine Learning, [détail des éditions]
- (en) Larry Rendell, « A general framework for induction and a study of selective induction », Machine Learning, vol. 1, , p. 177–226 (DOI 10.1007/BF00114117)
- W. Sverdlik, Reynolds, R.G. « Dynamic version spaces in machine learning » ()
— « (ibid.) », dans Proceedings, Fourth International Conference on Tools with Artificial Intelligence (TAI '92), Arlington, VA, p. 308–315