Cross Industry Standard Process for Data Mining
Cross Industry Standard Process for Data Mining (CRISP-DM)[1] est un modèle de processus d'exploration de données qui décrit une approche communément utilisée pour résoudre les problèmes du domaine de l'analyse, de l'extraction et des sciences des données.
Des sondages effectués en 2002[2], 2004[3], 2007[4], 2014[5] et 2020[6] montrent qu'il s'agit de la méthode principale utilisée pour les projets d'analyse, d'extraction et de science des données. Cette méthode a été créée par un consortium formé des compagnies NCR, SPSS et Daimler-Benz. Le processus définit une hiérarchie consistant de phases majeures, de taches générales, de taches spécialisées et d'instances de processus[7].
Phases principales
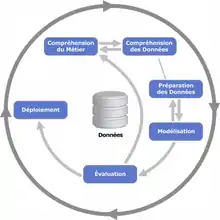
CRISP-DM découpe le processus de data mining en six phases principales[8] :
- connaissance du métier
- connaissance des données
- préparation des données
- modélisation des données
- évaluation
- déploiement
Histoire
La méthode CRISP-DM est conçue en 1996. En 1997, elle se développe en tant que projet de l'Union européenne financé par le programme ESPRIT. Le projet est conduit par quatre compagnies : ISL, NCR Corporation, Daimler-Benz et OHRA. Ce cœur du consortium apporte différentes expériences au projet : ISL, plus tard acquis et intégré dans SPSS Inc. produit ses progiciels d'analyse prédictive du même nom, intégré de nos jours au groupe IBM. Le géant informatique NCR Corporation créa la division Teradata spécialisée dans les entrepôts de données et son propre progiciel de data mining. Daimler-Benz avait une importante équipe de data miners. OHRA, une compagnie d'assurance, venait juste de commencer à explorer le potentiel d'utilisation du data mining.
La première version de la méthode fut publiée sous le numéro de version CRISP-DM 1.0[9] en 1999.
CRISP-DM 2.0
En , le consortium annonce qu'il va commencer à travailler sur une seconde version de CRISP-DM. Le , le CRISP-DM SIG se réunit pour discuter des améliorations pour CRISP-DM 2.0 et de la feuille de route qui en découle[10]. Depuis le , le site web redirige vers une page du site d'IBM dédié à SPSS.
Avantages
- Méthode neutre par rapport aux métiers
- Méthode neutre par rapport aux outils
- Méthode liée étroitement à KDD Process Model[11]
- Point d'ancrage du processus de data mining
Notes
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Cross Industry Standard Process for Data Mining » (voir la liste des auteurs).
Liens externes
- « CRoss Industry Standard Process for Data Mining »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?) (consulté le )
- CRoss Industry Standard Process for Data Mining Blog
- Le site des dataminers Article publié par Pascal BIZZARI,
- The Data Mining Group (DMG): The DMG is an independent, vendor led group which develops data mining standards, such as the Predictive Model Markup Language (PMML)
Références
- (en) C. Shearer, « The CRISP-DM model: the new blueprint for data mining »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?) [PDF] (consulté le ). J Data Warehousing 2000;5:13—22.
- Gregory Piatetsky-Shapiro (2002) KDnuggets Methodology Poll
- Gregory Piatetsky-Shapiro (2004) KDnuggets Methodology Poll
- Gregory Piatetsky-Shapiro (2007) KDnuggets Methodology Poll
- (en-US) « CRISP-DM, still the top methodology for analytics, data mining, or data science projects », sur KDnuggets (consulté le )
- (en-US) Jeff Saltz, « CRISP-DM is Still the Most Popular Framework for Executing Data Science Projects », sur Data Science Project Management, (consulté le )
- Robert Nisbet, John Elder, Gary Miner Handbook of Statistical Analysis & Data Mining Applications (Academic Press) page 35
- (en) Gavin Harper, « Methods for mining HTS data », Drug Discov. Today, vol. 11, nos 15-16, , p. 694–699 (PMID 16846796, DOI 10.1016/j.drudis.2006.06.006, lire en ligne).
- « CRISP-DM 1.0 »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?) (consulté le ).
- « CRISP-DM SIG »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?) (consulté le ).
- « KDD Process Model »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?) (consulté le )