Arbre d'ondelettes
Un arbre d'ondelettes (en anglais wavelet tree) est une structure de données qui contient des données compressées dans une représentation presque optimale, appelée succincte[1]. Cette structure étend les opérations de parcours et de sélection[2] définies sur les vecteurs de bits (en) compressés à des alphabets quelconques.
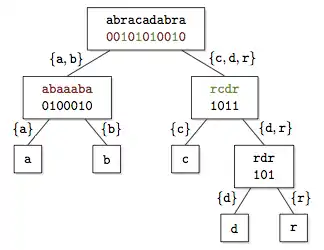
abracadabra. À chaque nœud, les symboles de la chaîne sont projetés sur une partition de l'alphabet en deux parties, et le vecteur de bits désigne la partie à laquelle appartiennent les symboles. Seuls les vecteurs de bits sont conservés, les chaînes indiquées dans les nœuds ne servent qu'à faciliter la présentation.Introduits à l'origine pour représenter des tableaux des suffixes compressés[3], les arbres d'ondelettes ont trouvé des applications dans des contextes variés[4] - [5]. L'arbre d'ondelettes est défini en partitionnant récursivement l'alphabet en deux sous-ensembles; les feuilles correspondent aux symboles de l'alphabet, et à chaque nœud est associé un vecteur de bits compressé qui mémorise le sous-ensemble auquel appartiennent les symboles.
Le nom dérive de l'analogie avec la transformée en ondelettes des signaux qui décompose récursivement un signal en composantes de fréquences basses et hautes.
Exemple
Dans l'exemple reproduit ci-dessus, l'alphabet de départ est partagé en deux sous-alphabets {a, b} et {c, d, r}. Le premier vecteur, à la racine, remplace les symboles du mot abracadabra par 0 ou 1, selon que le symbole est dans le premier sous-alphabet ({a, b}) ou dans le second ({c, d, r}). Au niveau suivant, on ne conserve plus que les symboles sélectionnés. La séquence de gauche est également partagée en deux, selon que la lettre est un a ou un b. Pour la séquence de droite, deux étapes sont nécessaires pour arriver à des alphabets formés d'un seul symbole. Pour trouver le deuxième a dans la chaîne initiale, on cherche d'abord le deuxième 0 dans le code 0100010 qui se trouve en troisième position, puis le troisième 0 dans le code 00101010010. C'est la quatrième lettre de cette chaîne, donc la quatrième du mot abracadabra.
Propriétés
Soit un alphabet fini à symboles. En utilisant un dictionnaire succinct (en) dans chaque nœud de l'arbre, une chaîne de longueur peut être représentée en place , où est l'entropie de Shannon d'ordre 0 de .







Pour un tableau de bits de taille donné, les trois opérations considérées sont les suivantes :

- qui retourne l'élément qui est en position dans la chaîne de départ.
- qui retourne le nombre d'éléments égaux à parmi les premiers éléments du tableau, formellement .
- qui retourne la plus -ième position dans le tableau qui contient un , formellement .




![{\displaystyle {\mathsf {rank}}_{q}(x)=\operatorname {Card} \{y\in [0\cdots x]:B[y]=q\}}](https://img.franco.wiki/i/7f9ba91f5d33303d4561bfdcdf1564652d01bd39.svg)


Si l'arbre est équilibré, les trois opérations , , et peuvent être réalisées en temps .




Extensions
Plusieurs extensions de la structure de base ont été présentées dans la littérature. Pour réduire la hauteur de l'arbre, on peut utiliser des arbres dont les nœuds ont une arité supérieure aux nœuds binaires[4]. La structure de données peut être rendue dynamique, ce qui permet des insertions et suppressions à des positions arbitraires de la chaîne ; ceci permet l'implémentation du FM-index[6] dynamique[7]. On peut encore généraliser ceci et autoriser de modifier l'alphabet de base : un wavelet trie[8] exploite une structure de trie sur l’alphabet des chaînes pour permettre des modifications dynamiques.
Notes et références
- Une telle structure de données est appelée en anglais succinct data structure (en), soit structure de données succincte. Elle doit permettre les opérations de recherche et aussi d'insertion/suppression sur les données compressées sans avoir à les décompresser auparavant, et elle s'approche de l'optimum théorique donné par la théorie de l’information.
- Opérations notées et .
- Roberto Grossi, Ankur Gupta et Jeffrey Scott Vitter, « High-order entropy-compressed text indexes », Proceedings of the 14th Annual SIAM/ACM Symposium on Discrete Algorithms (SODA), janvier 2003, 841-850.
- Paolo Ferragina, Raffaele Giancarlo et Giovanni Manzini, « The myriad virtues of Wavelet Trees », Information and Computation, Volume 207, no 88, août 2009, Pages 849-866
- Le FM-index, nommé ainsi d'après leur inventeurs Ferragina et Manzini, est une structure qui permet de se passer du texte.
- Ho-Leung Chan, Wing-Kai Hon, Tak-Wah Lam, et Kunihiko Sadakane, « Compressed Indexes for dynamic text collections », ACM Transactions on Algorithms, volume 3, (n°2), 2007
- Roberto Grossi et Guiseppe Ottaviano, « The Wavelet Trie: maintaining an indexed sequence of strings in compressed space », Proceedings of the 31st Symposium on the Principles of Database Systems (PODS), 2012
Liens externes
- Wavelet Trees. Un blog qui décrit la construction d'un wavelet tree, avec exemples.
- Mikaël Salson, Structures d’indexation compressées et dynamiques pour le texte. Un manuscrit en français avec de nombreux exemples détaillés.