Apprentissage par renforcement hors ligne
L'apprentissage par renforcement hors ligne (ou batch) est un cas particulier de l'apprentissage par renforcement, qui est une classe de problèmes d'apprentissage automatique dont l'objectif est de déterminer à partir d'expériences une stratégie (ou politique) permettant à un agent de maximiser une récompense numérique au cours du temps.
Dans le cadre de l'apprentissage par renforcement purement hors ligne, l'agent ne peut pas interagir avec l'environnement : une base d'apprentissage lui est fournie au départ et il l'exploite pour apprendre une politique. Contrastant avec les algorithmes en-ligne, où l'agent à la possibilité d'interagir comme bon lui semble avec l'environnement, les algorithmes hors-ligne tentent d'exploiter au maximum les exemples d'apprentissage dont ils disposent, sans compter uniquement sur la possibilité d'exploration. Cette approche est donc particulièrement avantageuse quand il n'est pas possible d'effectuer des expériences ou lorsque ces expériences sont coûteuses (casse de matériel possible, obligation d'avoir recours à une assistance humaine pendant les expériences, etc). En général cependant, les techniques d'apprentissage par renforcement batch peuvent être utilisées dans un cadre plus large, où la base d'apprentissage peut évoluer au cours du temps. L'agent peut alors alterner entre des phases d'exploration et des phases d'apprentissage. Les algorithmes hors-ligne sont en général des adaptations d'autres algorithmes comme le Q-Learning, eux-mêmes inspirés par les algorithmes de programmation dynamique résolvant les MDPs.
Classification des batchs
Définir précisément ce qu'est ou n'est pas un algorithme hors-ligne n'est pas forcément évident. Une des positions que l'on peut adopter est de considérer "hors-ligne" tout algorithme qui n'est pas purement en-ligne. Ceci amène alors à distinguer trois types de méthodes batch:
- Sans interaction sur l'environnement et en prenant toutes les expériences disponibles : pure batch.
Le principe du batch pure est d'être complètement hors ligne. C'est-à-dire qu'il prend une fois les expériences et apprend sa politique optimale sur ce jeu uniquement. Si une nouvelle expérience arrive, elle ne peut pas être incluse toute seule, il faut l'inclure dans l'ensemble des expériences précédentes et réapprendre sur ce nouvel ensemble.
- Avec interaction sur l'environnement et en prenant toutes les expériences disponibles : growing batch.
Dans la situation de pure-batch il peut être difficile de trouver une politique optimale si l'ensemble des expériences suit une distribution qui n'est pas celle du système réel sous-jacent. Cela peut se traduire par des représentations de probabilités de transitions erronées ou des transitions manquantes. La meilleure solution pour pallier ce manque d'information est donc d’interagir avec le système quand c'est possible et d'utiliser à chaque fois l'ensemble de l'information disponible. C'est le principe d'exploration (effectué par l’interaction) et d'exploitation (effectué par les expériences) que l'on retrouve dans les méthodes classique d'apprentissage par renforcement.
- Avec interaction sur l'environnement et en ne prenant pas toutes les expériences disponibles : semi-batch.
Le semi-batch se situe entre les deux précédentes. Le système met à jour plusieurs expériences en même temps ce qui fait que le semi-batch n'est pas purement en ligne mais il n'utilise qu'une seule fois les expériences, ce qui fait qu'il n'est pas complètement hors-ligne.
Modèle théorique sous-jacent
La modélisation classique de l'apprentissage par renforcement (en ligne ou hors ligne) utilise la notion sous-jacente de processus de décision markovien (MDP). Rappelons-en les principales notations:
- le MDP est noté ;
- la fonction de valeurs des états ;
- celle des valeurs des états-actions ;
- les politiques sont notées .




Exemples
Mountain Car
Le Moutain car est un problème classique de la littérature de l'apprentissage par renforcement, dans lequel une voiture doit atteindre le haut d'une colline.
- Les états sont décrits par la position de la voiture () et sa vitesse ();
- Les actions sont les accélérations possibles de la voiture : accélérer vers l'avant, vers arrière, ou rester en roue libre.
- La fonction de transition est obtenue en effectuant la somme des forces qui s'applique à la voiture;
- La fonction de récompense vaut
![{\displaystyle p\in [-1.2,0.6]}](https://img.franco.wiki/i/59d245a41e2580dc4c99bf0f53fe64f1858a5fba.svg)
![{\displaystyle s\in [-0.07,0.07]}](https://img.franco.wiki/i/b1051898cff8fc610702d9ad1dd7ce5a8e5dc0a2.svg)

Pendule inversé
Ce problème est un autre exemple classique, dans lequel un agent doit contrôler une perche munie d'un poids à l'aide d'un moteur pour la placer en équilibre en position verticale, avec le poids en haut. Le moteur n'étant pas assez puissant pour faire passer de la perche de sa position initiale à la position d'équilibre d'un coup, l'agent doit apprendre à faire balancer la perche.
- Les états sont la position de la perche et sa vitesse;
- Trois actions sont possibles : faire tourner le moteur dans les deux sens, ou arrêter le moteur;
- La fonction de transition est inconnue, ses valeurs sont obtenues en observant la perche;
- La fonction de récompense vaut 0 si la perche est à la position d'équilibre (avec une marge de 0.5°) et -1 sinon.
Les techniques batch
Généralités
Il existe une grande variété d'algorithmes hors-ligne dans la littérature, mais de manière générale ils brodent tous autour de quelques principes fondamentaux qui les distinguent des algorithmes purement en-ligne ou de ceux dans lesquels le MDP est connu. Initialement pensés pour résoudre les difficultés spécifiques à l'apprentissage hors-ligne, ces principes sont également avantageux dans un cadre plus général.
Experience Replay
Pour un Q-learning purement en ligne, l'agent est libre d'explorer et de générer de l'expérience comme bon lui semble. Ces expériences sont utiles par deux aspects:
1. effectivement explorer l'environnement, c'est-à-dire expérimenter de nouvelles transitions vers des états non encore visités et récolter de nouvelles récompenses;
2. faire converger l'algorithme, car celui-ci demande un grand nombre d'itérations pour propager les informations et finalement se stabiliser vers une politique optimale. Dans la situation hors ligne, on ne peut se contenter de n'utiliser qu'une seule fois une expérience donnée car le nombre d'expériences est limité par définition, et ne permettrait pas de faire converger l'algorithme.
Cette difficulté est levée en "rejouant" plusieurs fois les mêmes expériences, c'est-à-dire que le jeu de données disponible est exploité encore et encore comme s'il s'agissait de nouvelles expériences.
Fitting
Dans les méthodes classiques d'apprentissage par renforcement, il est commun de faire la mise à jour de la fonction de valeur de manière désynchronisée. C'est-à-dire qu'après chaque observation d'une transition, la valeur d'un état ou d'un état-action est mise à jour localement et les autres états sont laissés inchangés. Ensuite, ce n'est que lors de nouvelles interactions que les autres états seront évalués sur la base de la valeur mise à jour précédemment.
Les algorithmes batch, dans le but d'exploiter au maximum les données disponibles, de s'adapter à des espaces d'états continus et de contrer certains problèmes d'instabilités lors de l'apprentissage (cas de non convergence), ne se contentent pas de stocker simplement les valeurs pour chaque état ou action et d'appliquer des mises à jour de type programmation dynamique. Ils ajoutent au-dessus une forme ou une autre de globalisation et de régularisation des mises à jour qui peut se voir comme un apprentissage supervisé des fonctions de valeurs.
Par exemple, dans les algorithmes que nous présentons ci-dessous, on trouve l'utilisation d'un noyau gaussien qui permet de moyenner localement les valeurs, d'une base de fonctions dans laquelle on exprime la fonction de valeurs, ou plus explicitement d'un algorithme d'apprentissage supervisé (réseau de neurones, k-plus-proches-voisins...) pour apprendre la fonction de valeurs.
De cette manière chaque expérience utilisée va permettre de mettre à jour globalement l'ensemble de la fonction de valeurs (des états ou états-actions) sans nécessiter d'attendre que de multiples itérations propagent l'information de manière plus ou moins aléatoire.
Principe général
L'algorithme Kernel-Based Approximate Dynamic Programming (KADP) suppose qu'un ensemble de transitions observées de façon arbitraire est à sa disposition. Il suppose ensuite que l'espace des états est muni d'une distance, à partir de laquelle la notion de moyennage basé sur un noyau Gaussien prend sens. Ce noyau est utilisé pour mettre à jour itérativement la fonction de valeurs en tous les états, à partir du jeu d'échantillons . On voit bien ici l'application de l'idée d'experience replay (on utilise répétitivement toutes les données) et celle de fitting puisque le noyau permet à l'ensemble des valeurs d'être mise à jour par chaque transition.


Algorithme
L'algorithme démarre d'une fonction de valeurs des états arbitrairement choisie puis chaque itération du KADP consiste en deux phases:

Phase 1
La première phase évalue la mise à jour du processus décisionnel :
![{\displaystyle {\hat {Q}}_{a}^{i+1}(\sigma ):=\sum _{(s,a,r,s')\in F_{a}}k(s,\sigma )[r+\gamma {\hat {V}}^{i}(s')]}](https://img.franco.wiki/i/f7bfd1f242d14c66243cb45fc305e9fd3559892d.svg)
avec un sous ensemble de qui n'utilise que les actions a.

Cette équation calcule la moyenne pondérée de la mise à jour habituelle: avec comme pondération . Le noyau est choisi de telle sorte que les transitions les plus éloignées aient une moins grande influence que les plus proches.


Phase 2
La seconde phase consiste à calculer les nouvelles valeurs des états selon la politique gloutonne:

L'algorithme va donc itérer sur les équations définies au-dessus pour évaluer avec et espérer converger vers une unique solution .



Exemple d'application
Le problème du choix du portfolio optimal décrit dans [1] est un cas pratique du KADP. C'est un problème d'investissement financier où l'agent décide d'acheter ou non des actions. Le but étant à la fin de la simulation de maximiser le gain de l'agent.
Sa représentation comme un MDP est la suivante :
- l'état symbolisant la valeur de l'action à un instant t
- l'action représentant l'investissement de l'agent dans l'action avec
- La richesse de l'agent au temps t est et sa richesse au temps t+1 est





L'agent va donc au cours du temps investir (ou pas) dans une action pour maximiser sa richesse avec comme but d'être le plus riche possible à la fin du temps maximum défini. Pour rendre le problème le plus réaliste possible, l'agent adopte un comportement tel qu'il a peur de perdre ses gains autant qu'il a l'envie d'en gagner.
Fitted Q iteration (FQI)
Cet algorithme permet de calculer une approximation de la fonction de valeurs optimale des états-actions à partir d'un jeu d'échantillons du MDP. Connaissant , il est alors possible de déduire la politique correspondante : . Il repose sur le même principe que l'algorithme d'itération sur la valeur des états-actions, qui consiste à calculer de manière itérative le point fixe de l'équation de Bellman :

![{\displaystyle Q^{i+1}(s,a)=\sum _{s'\in S}[R(s,a,s')+\gamma \max _{a'\in A}Q^{i}(s',a')]T(s,a,s')}](https://img.franco.wiki/i/2a98175e683b40ce48fd6792d66e3e0e218535ab.svg)
On cherche à calculer ce point fixe à partir d'un jeu d'échantillons (un ensemble de transitions de la forme ). L'algorithme procède de la manière suivante :


- Il crée une base de données d'apprentissage constituée des couples entrée-sortie pour chaque transition . La valeur ainsi calculée pour chaque est en quelque sorte la «meilleure estimation» que l'on puisse faire de la valeur de dans l'état actuel des connaissances décrit par .
- Il en déduit une fonction à partir de l'ensemble en utilisant une méthode d'apprentissage supervisé. Cette fonction est donc une approximation de la fonction obtenue à la i+1ème itération de l'algorithme d'itération sur la valeur des états-actions.
- Il incrémente et retourne à la première étape tant qu'une condition d'arrêt n'est pas vérifiée.









Cet algorithme peut-être utilisé avec n'importe quelle méthode d'apprentissage supervisé, en particulier des méthodes non paramétriques, qui ne font aucune hypothèse sur la forme de . Cela permet d'obtenir des approximations précises indépendamment de la taille des espaces d'états et d'actions, y compris dans le cas d'espaces continus.
On peut consulter [2] pour une mise en œuvre dans laquelle la méthode d'apprentissage est une régression régularisée moindres carrés; un réseau de neurones est utilisé dans [3]; enfin une approche basée sur différents types d'arbres de régression est analysée dans [4].
De manière générale, la convergence de l'algorithme n'a été démontrée que pour une certaine classe de méthodes d'apprentissage. Différentes conditions d'arrêt peuvent être utilisées ; en pratique, fixer le nombre d'itérations permet d'assurer la terminaison de l'algorithme, et ce quelle que soit la méthode d'apprentissage utilisée.
Dans [4], plusieurs problèmes ont été utilisés pour évaluer l'algorithme avec différentes méthodes d'apprentissage supervisé, et avec plusieurs types de batch (pure batch et growing batch). Sur ces problèmes, l'algorithme de fitted Q iteration est très performant, en particulier en utilisant des méthodes d'apprentissage non paramétriques (comme la méthode des k plus proches voisins).
Itération moindres carrés de la politique (LSPI: Least-Squares Policy Iteration)
Bien adapté à l'apprentissage pûrement hors-ligne, LSPI est une approche reconnue pour exploiter efficacement un jeu de données fixe préexistant ([5] - [6]).
Description de l'algorithme
Cet algorithme est une adaptation de l'algorithme d'itération de la politique exprimé sur la fonction d'états-actions. Il se focalise exclusivement sur l'évaluation de , et la politique n'y est jamais représentée explicitement, mais simplement déduite à la volée, par le choix glouton classique:
Par rapport à PI, LSPI opère deux grands changements :
1. la fonction est exprimée comme une combinaison linéaire de fonctions , :



Les fonctions forment donc une base d'un sous-espace de l'espace des fonctions états-actions, choisie une fois pour toutes au départ. Ainsi en interne, la fonction est simplement représentée par les coefficients .



Ce modèle possède un avantage: quels que soient le nombre d'états et d'actions, seuls coefficients sont utilisés pour représenter l'ensemble des valeurs de , contre si l'on utilisait une représentation tabulaire classique. Ceci permet de traiter efficacement des MDP possédant un grand nombre d'états et/ou d'actions. On peut même, dans ce formalisme, considérer des espaces d'états ou d'actions continus.

L'inconvénient, en revanche, est que l'on est maintenant restreint aux fonctions de . Dans l'algorithme PI avec états-valeurs, la phase d'évaluation de la politique consiste à déterminer le point fixe de l'opérateur

![{\displaystyle K(Q)(s,a)=\sum _{s'\in S}[R(s,a,s')+\gamma Q(s',\pi (s'))]T(s,a,s'),}](https://img.franco.wiki/i/03d62016b6158534bc8c8ecd6c418db48f3f61fd.svg)
soit par la résolution d'un système linéaire, soit par calcul itératif sur .

Or même si par définition , on n'a pas en général . L'idée dans LSPI est alors de projeter (au sens des moindres carrés, d'où le nom de l'algorithme) la mise à jour sur :




et donc d'obtenir une approximation de qui est stable par la règle de mise à jour suivie de la projection. Dans [7] ce point fixe est obtenu par résolution d'un système linéaire.

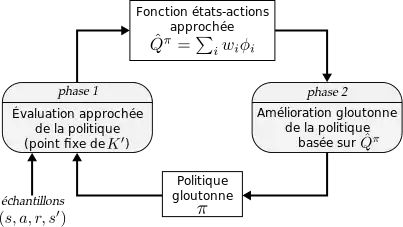
2. La deuxième différence est que LSPI ne suppose pas le MDP connu; l'algorithme se base uniquement sur un jeu d'échantillons du MDP, donnés sous la forme de quadruplets . Ces échantillons peuvent être donnés directement au départ de l'algorithme (mode pure-batch) ou progressivement (mode semi-batch ou en-ligne). Concrètement, l'algorithme se contente d'effectuer les mises à jour précédentes sur le jeu d'échantillon, éventuellement de façon répétée pour provoquer la convergence («experience replay»). On peut montrer qu'en fait cela revient à appliquer la mise à jour sur le véritable MDP, mais avec les probabilités de transitions obtenues empiriquement selon la distribution des échantillons. Ainsi, dans l'hypothèse où cette distribution est conforme aux véritables probabilités de transition du MDP sous-jacent, le résultat converge asymptotiquement vers la véritable valeur , et donc finalement vers la fonction optimale . On peut également remarquer que chaque échantillon contribue linéairement à chaque itération (il ajoute un terme dans la somme définissant et l'opérateur de projection est linéaire), ce qui permet de mettre en place des optimisations lorsque les échantillons arrivent progressivement.


La figure ci-contre résume schématiquement l'algorithme LSPI.
Exemple d'application
Dans [7], plusieurs applications de l'algorithme LSPI sont proposées. L'une d'elles, dans lequel l'algorithme est particulièrement performant notamment par rapport à un algorithme de Q-Learning, est le problème de l'équilibre et la conduite d'un vélo [8].
Dans ce problème l'apprenant connaît à chaque pas de temps l'angle et la vitesse angulaire du guidon, ainsi que l'angle, la vitesse et accélération angulaire de l'angle que forme le vélo avec la verticale. Il doit alors choisir quelle force rotatoire appliquer au guidon (choisie parmi trois possibilités), ainsi que le déplacement de son centre de masse par rapport au plan du vélo (choisie également parmi 3 possibilités), de manière d'une part à rester en équilibre (c'est-à-dire ici ne pas dépasser un angle vélo/sol de +/- 12°) et d'autre part atteindre une destination cible.
La mise en œuvre est purement hors-ligne et consiste à observer le comportement d'un agent aléatoire pour collecter de l'ordre de quelques dizaines de milliers d'échantillons sous forme de trajectoires. Les trajectoires collectées sont ensuite coupées après quelques pas de temps, pour ne garder que la partie intéressante avant qu'elles ne rentrent dans un scénario de chute inexorable. Les récompenses sont en lien avec la distance atteinte par rapport à l'objectif. Quelques passes de l'algorithme sont ensuite effectuées sur ces échantillons («experience replay») et une convergence très rapide vers des stratégies viables est observée.
Bibliographie générale
- (en) Sascha Lange, Thomas Gabel, and Martin Riedmiller, Batch Reinforcement Learning, dans Marco Wiering, Martijn van Otterlo éd., Reinforcement Learning: State-of-the-Art, Berlin Heidelberg, Springer-Verlag, coll. «Adaptation, Learning and Optimization, vol. 12», 2012 (ISBN 978-3-642-27644-6)
Notes et références
- (en) Dirk Ormoneit and Peter Glynn, «Kernel-Based Reinforcement Learning in Average-Cost Problems: An application to Optimal Portfolio Choice», Advances in Neural Information Processing Systems, 2000, p. 1068-1074
- (en) Farahmand Amirmassoud, Ghavamzadeh Mohammad, Szepesvári Csaba, Mannor Shie, Regularized Fitted Q-Iteration: Application to Planning, dans Girgin Sertan, Loth Manuel, Munos Rémi, Preux Philippe, Ryabko Daniil, Recent Advances in Reinforcement Learning, Berlin Heidelberg, Springer, col. Lecture Notes in Computer Science, 2008, (ISBN 978-3-540-89721-7) p55-68
- (en)Martin Riedmiller, Neural Fitted Q Iteration – First Experiences with a Data Efficient Neural Reinforcement Learning Method, dans Gama João, Camacho Rui, Brazdil PavelB, Jorge AlípioMário, Torgo, Luís éd., Machine Learning: ECML 2005, Springer Berlin Heidelberg, Lecture Notes in Computer Science vol. 3720, 2005, (ISBN 978-3-540-29243-2) pp 317-328.
- (en) Damien Ernst, Pierre Geurts, Louis Wehenkel, «Tree-Based Batch Mode Reinforcement Learning», Journal of Machine Learning Research 6, 2005, p. 503–556
- (en) Christophe Thiery and Bruno Scherrer, Least-Squares Policy Iteration: Bias-Variance Trade-off in Control Problems, International Conference on Machine Learning, Haifa, Israel, 2010, [lire en ligne]
- (en) Li L., Williams J. D., and Balakrishnan S, Reinforcement learning for dialog management using least-squares Policy iteration and fast feature selection. In INTERSPEECH, 2009, pp. 2475-2478.
- (en) Michail Lagoudakis, Ronald Parr, «Least-Squares Policy Iteration», Journal of Machine Learning Research 4, 2003, p. 1107-1149
- (en) Jette Randløv and Preben Alstrøm, «Learning to Drive a Bicycle Using Reinforcement Learning and Shaping», dans Proceedings of the Fifteenth International Conference on Machine Learning (ICML '98), 1998, Jude W. Shavlik (Ed.). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 463-471.
